深度学习中的图像数据扩增(Data Augmentations)方法总结:常用传统扩增方法及应用
深度学习中的图像数据扩增(Data Augmentations)方法总结:常用传统扩增方法及应用
1. 前言
这篇文章主要参考 A survey on Image Data Augmentation for Deep Learning, 总结了常用的传统扩增方法及其应用时的注意事项。这里的传统方法指不包括基于深度学习(比如 GAN)等新的扩增方法。
另外需要注意的是,虽然对于不同的任务,比如对于分类,检测任务,不同的任务在采用某一个具体的扩增方法的时候会有所不同,比如对于检测任务需要考虑对 bounding box 进行相应的操作,但是这里仅仅从扩增方法的角度来说是没有区别的。
最后, 数据扩增的具体方法非常多,而且除了各个训练框架提供的方法之外还有很多第三方库,这里仅仅是整理了一些比较常见的扩增方法。更多的扩增方法可以参考第三方库 imgaug, albumentations 等。
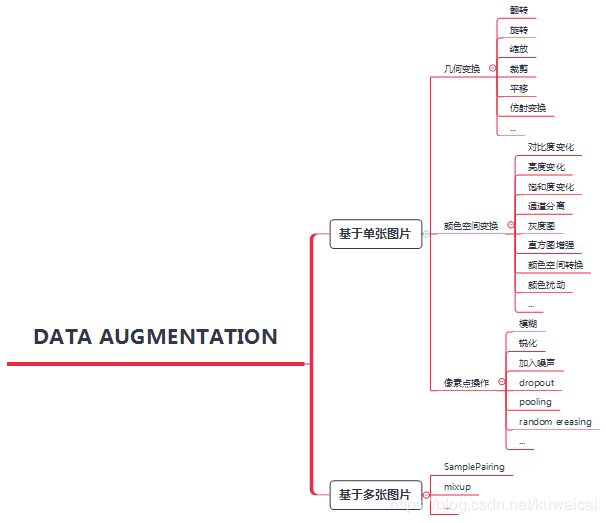
2. 数据扩增
数据扩增是对数据进行扩充的方法的总称。数据扩增可以增加训练集的样本,可以有效缓解模型过拟合的情况,也可以给模型带来的更强的泛化能力。怎么理解呢?
数据扩增的目的就是使得训练数据尽可能的接近测试数据,从而提高预测精度。另外数据扩增可以迫使网络学习到更鲁棒性的特征,从而使模型拥有更强的泛化能力,比如对图像进行一定程度的遮挡。
通常在进行数据扩增操作的时候应该保持图像原本的标签不变,比如对于猫狗分类任务,rotate 或者 flip ,一般对标签是没有影响的,但是对于手写数字识别,比如 9 和 6 就不适用了。当然如果能相应的修改标签,对于网络训练来说是有益的,但是这将又是一个麻烦的费时费力的过程。所以通常来说,数据扩增应该在不改变标签的前提下进行。
3. 常用数据扩增方法
3.1 基于几何变换的扩增方法
基于几何变换的方法可以消除测试集和训练集的位置差异,尺度差异,视角差异等。
3.1.1 Flipping
水平翻转通常比竖直翻转更通用,但是对于字符识别任务,通常不适用。
3.1.2 Cropping
裁剪是一个比较常用,也是一个长点比较明显的数据增强的方式。
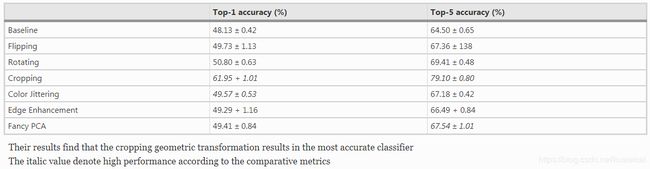
3.1.3 Rotation
旋转的角度关系到标签是否安全,比如对于 MNIST,1° 到 20° 或者 -1° 到 -20° 之间的轻微旋转是没有问题的,如果更大幅度的旋转可能会影响到标签。
3.1.4 Translation
平移(向左、向右、向上或向下移动)图像是一个非常有用的变换,可以避免数据中的位置偏差。例如,如果数据集中的所有图像都是居中的(这在人脸识别数据集中很常见),这就要求模型也要在完全居中的图像上进行测试。当原始图像被平移后造成的空白区域,可以用一个常数值填充,如 0 或 255 ,也可以用随机或高斯噪声填充。这种填充可以保留图像增强后的空间尺寸。
3.1.5 Noise injection
添加噪声一般可以应对噪声干扰,或者成像异常等特殊情况。
增加高斯噪声是比较常用的操作,增加噪声可以帮助 CNNs 学习到更 robust feature。
对于训练数据中存在的位置偏差,几何变换是非常好的解决方案。有许多潜在的偏差来源,可以将训练数据与测试数据的分布分开。如果存在位置偏差,例如在人脸识别数据集中,每个人脸都是完全居中的,几何变换是一个很好的解决方案。除了克服位置偏差的强大能力之外,几何变换也很有用,因为它们很容易实现。有很多成像处理库,可以让水平翻转和旋转等操作轻松上手。几何变换的一些缺点包括额外的内存、变换计算成本和额外的训练时间。一些几何变换,如平移或随机裁剪等几何变换必须手动观察,以确保它们没有改变图像的标签。最后,在所涉及的许多应用领域,如医学图像分析,训练数据与测试数据之间的偏差比位置偏差和平移偏差更复杂。因此,几何变换也不一定总是能带来明显的效果。
3.2 颜色空间变换
颜色空间变换一般可以消除光照、亮度及色彩差异。
- 对过亮或过暗的图像进行快速处理的方法是在图像中进行循环,并将像素值减少或增加一个恒定值。
- 另一种快速的色彩空间处理方法是拼接出单个RGB颜色矩阵。
- 另一种变换包括将像素值限制在一定的最小值或最大值。数字图像中颜色的内在表现形式,使其可以用于许多增强策略。
- 通道分离
- 亮度
- 对比度
- 饱和度
- 基于直方图
- 灰度图
转换为灰度图后,计算量减少,但是精度通常会有所降低,有人在 ImageNet 上对比 RGB 和 灰度图,发现灰度图的精度下降大约 3%。
颜色空间变换也可以从图像编辑应用程序中得到。图像中每个RGB颜色通道中的像素值被聚合成一个颜色直方图。这个直方图可以被操纵,应用滤镜来改变图像的颜色空间特性。
颜色空间变化可以帮助客服光照差异,但是如果任务对颜色的依赖性很强,比如要分辨油漆,水和血液,可能红色是一个非常重要的信息,如果进行不当的颜色空间变换,可能适得其反。
3.3 Kernel filters
- 模糊
- 锐化
直观地讲,为数据增强而对图像进行模糊化处理可能会导致测试过程中对运动模糊的抵抗力更强。此外,为数据增强而对图像进行锐化可能会导致对感兴趣对象的更多细节进行封装。另外由于 Kernel filters 的方式和 CNNs 类似,因此可以把该操作集成到 CNN 层。
3.4 Mixing images
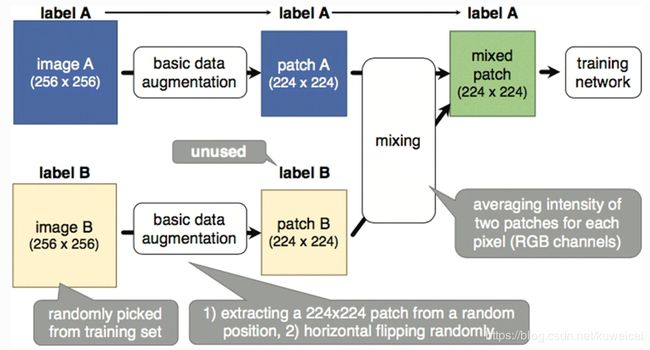
Mixing images 被证明对小的数据集作用更明显。
- 两幅图每个像素取平均
- 两幅图线性叠加
- 从两幅或多幅图中裁剪一个局部,然后将这些拼接
这种方法主要在目标检测中使用的比较多,效果比较好。
3.5 Random erasing
思想和 dropout 类似,不同的是 Random erasing 是在输入数据空间进行,而非是在网络结构中。这种方法也可以看着是在模拟遮挡的情况,以保证网络关注整个图像,而不是只关注其中的一个子集。
通常 earsing 的区域直接填充随机值效果更好。使用的时候需要注意是否标签安全,可能需要人为的加入一些限制,以保证标签的正确性。
4 总结
- 数据扩增的方式很多,但是在实际项目中通常最直接的方法是收集更多的数据,从根本上解决问题,而数据扩增更多的是锦上添花。
- 数据扩增并不是总能产生积极的作用,不当的数据扩增可能产生负面影响。而什么是适当的数据扩增,取决于具体的任务和数据集。
- 数据扩增的总体原则是让训练集的分布靠近测试集。
- crop 在多数情况下是非常有效的扩增方式。
- 基于 GAN 的扩增方式往往需要大量的数据,可是扩增的原因就是数据太少。。。
参考
- A survey on Image Data Augmentation for Deep Learning
- 使用深度学习(CNN)算法进行图像识别工作时,有哪些data augmentation 的奇技淫巧?
- Data Augmentation | How to use Deep Learning when you have Limited Data — Part 2