条件随机场——深入剖析逻辑斯蒂回归和最大熵模型、条件随机场,他们到底有啥关系?(二)
文章目录
- 线性链CRF
- 特征函数如何理解
- 1. w给定时,要找最优的y时,假设每个词m个状态,N个词,解空间是$m^N$个序列,暴力是指数级别的。
- 2. 如果给定了x,w这个p计算时有什么问题:归一化因子很麻烦
- CRF的三个问题——预测问题
- 前向得分
- CRF的三个问题——概率计算
- CRF的三个问题——参数学习
- 条件随机场和隐马尔可夫模型,哪个好?
众所周知,条件随机场在NLP中做NER和词性标注等任务是一把好手,但是条件随机场一直是很多同学心中谜一样的存在:贝叶斯网络,隐马模型,马尔科夫网络,最大熵隐马尔可夫模型,这些概率图就是都是写什么样的关系?之前写了一篇 隐马模型的文章和一篇 主题模型的文章,感兴趣的同学可以看看。是的,你会被标题吸引住的。废话不多说啦,开始。
本文则着重是从逻辑回归讲清楚条件随机场这个东西。
线性链CRF
一般我们讨论的也是线性链的CRF,如下图:
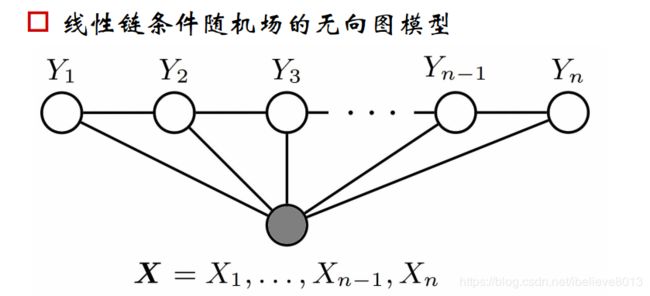
这个图的意思是y仍然还是仅和前后有关。
现在想想,如果有这样一个图,怎么样才能合适的建模???
我们的目标是P(y|x),也是一个后验概率,最终是想最大化这个后验概率,和LR是一致的。
我们看看CRF模型的形式:

怎么样,蒙了吧,脑瓜子嗡嗡的吧?看不懂没关系,我们换个写法:

注意哦,这个写法和上面是一个意思,只是形式上的区别,是不是感觉有点眼熟了,你看看那个归一化因子,看看指数函数,想起了什么吗,什么?你说还看不懂???
那行吧,继续简化:

现在呢?现在sigma都没有了,变成了 w T w^T wT,还没想起上篇文章的LR吗,这个 w T w^T wT不就是LR中的 θ T \theta^T θT吗,这里的F(y, x)不就是LR中的x吗?只是这个变成了多元softmax,而LR中是二元的。
特征函数如何理解
考虑这样一个事实,如果我们有一个多维的向量x,x的每个维度都是一个特征,然后这条样本对应了一个label,我们要分类,是不是最简单就是logistics回归?当然要做归一化更好地梯度下降我们就不说了,不是这里的重点。那么问题就是数据并不是乖乖地排列好,x的每个维度都已经取好值等着我们分类了,所以出现了这个东西:特征函数!特征函数的名字取得很好,就是为了构造特征的一个函数,符合这个特征,取值为1,不符合,输出位0。就是这么简单,那有些同学又要问了,那这个特征函数如何取才好呢,怎么学习这个特征函数呢?很遗憾,我们现在大多数是人工来设定这个特征函数的hhh。还不够清楚?我们举个例子。
比如词性标注任务里面,可以取的特征函数就是后缀等,如后缀是ed,特征 f 1 f_1 f1取1,否则是0,如后缀是ing,则 f 2 = 1 f_2=1 f2=1,否则=0。在一个高精度的词性标注里面,甚至会有10万个特征函数,这些特征函数可以做的很细很细,只要你能想到的,都可以是特征函数。这就带来了速度慢的问题,这是CRF 最大的缺点。
另外,特征函数前面为什么要有权重,这个问题应该不用说了,就类比逻辑回归的那个参数就行了。

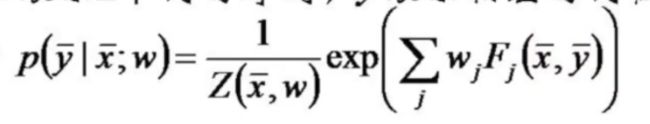
其实对于这个 F j F_j Fj,是整个句子的特征对不对?但是我们实际要操作的时候肯定是以词为粒度的,所以这里的新概念是“次特征”

就是说每个词的特征,就叫次特征,句子特征需把所有的词加起来。
这里目标函数并没有选择其他的如均方误差,直接使得预测的最大概率的那个序列等于实际的序列y*,即:
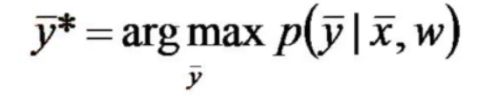
要学习这个模型,有两个难点:
1. w给定时,要找最优的y时,假设每个词m个状态,N个词,解空间是 m N m^N mN个序列,暴力是指数级别的。
2. 如果给定了x,w这个p计算时有什么问题:归一化因子很麻烦

对所有可能的y加和??excuse me?又是指数级别。
其实问题1,就类似于HMM中的解码问题,要求最大概率的序列,类似于HMM,CRF也有三个要解决的问题。
CRF的三个问题——预测问题
对问题1,转化到次特征上,对加和顺序翻转:
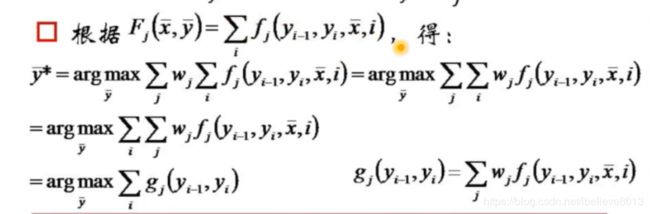
g j ( y i − 1 , y i ) g_j(y_{i-1},y_i) gj(yi−1,yi)中j是特征编号,那么就相当于是对单个词的所有的特征加和,把所有的i列举出来,就有很多个 g j g_j gj,这个g就是一个状态关系矩阵,大小为a*a。
前向得分

α k ( v ) \alpha_k(v) αk(v)是一个前向得分,表示第k个位置的y一定为v,而前面k-1个y状态不关心是什么,最后求出到达k位置为v的最大的概率(未归一化),计算这个的复杂度就是 m k − 1 m^{k-1} mk−1,因为长度是k-1,状态有m个。然后如图递推: α k ( v ) \alpha_k(v) αk(v)就是在第k-1的位置处某个状态 y k − 1 y_{k-1} yk−1的得分值,加上转移到k位置为v的转移得分值, g k g_k gk不是就转移矩阵嘛。这就得到了递推关系。
复杂度为什么是 m 2 n m^2n m2n? 这里就看那个递推公式,k-1有m个状态,k有m个状态,那要计算出k时所有状态的得分,当然就要m*m次计算了,然后有n的长度,从头递推过来就是 m 2 n m^2n m2n了。
CRF的三个问题——概率计算
对应于上面的第2个难题,概率计算问题,就是给了条件随机场p(y|x),给了观测序列x和输出序列y,问这个y出现的概率如何?这个算是三个问题中最简单的一个了吧,但是要求归一化因子却不简单。
常规思路是,我们要算归一化因子,就要知道所有的y的取值嘛,而y的取值是 m n m^n mn,那么这个归一化因子的复杂度也是这么高!所以需要我们动动脑筋。先剧透,我们的思路是用矩阵的运算来降低复杂度。
还记得我们曾定义了一个状态关系矩阵 g j g_j gj吗,这里还要用一次,我们按下图方式变换一下归一化因子Z的形式:

这里 g j g_j gj是一个关系矩阵哦。

由这张图我们惊奇地发现,连乘再连加的那个奇怪的东西,似乎就是状态转移的含义。不清楚我们再进一步:

假设我们把所有M从1到n的状态转移完成,不就是上面那个连乘又连加的怪物吗?真是有趣了,所以两条路既然都在这里会师,那么我们要求归一化因子,用上图的矩阵就能完成了鸭!我们来看看时间复杂度,一个(a,b)大小的矩阵乘以(b,c)大小的矩阵,运算是abc次,因此我们这里每两个矩阵之间运算就是 m ∗ m ∗ m m*m*m m∗m∗m次,而又有n的长度,因此复杂度是 n ∗ m 3 n*m^3 n∗m3,终于降到了多项式时间内的复杂度了!
有些人纳闷,凭什么原来是 m n m^n mn次运算,而你可以降下来?根本原因还是在于原来的运算中有大量的冗余!而矩阵运算,如第1、2个矩阵相乘了之后,我们发现后面1、2矩阵内部的元素没有再重复运算,这就是为什么能降下来复杂度的原因。
CRF的三个问题——参数学习
说了半天其实怎么把各个特征函数的权重学习到才是最重要的,怎么学呢?梯度下降,目标函数呢?总体的思路是:对目标函数取对数,然后求驻点,就是求偏导呗。
目标函数我们已经说过了,不是均方误差,直接是最大化后验概率,和逻辑回归是一样的。

以下求导,来!
对j维求偏导:


解释最后两步:根据当前迭代出的w值,求出概率值,利用这个概率再求特征的期望,然后看第j个特征真实值是多少,作差就是梯度!结论还是很符合我们的直观的。
然后就可以梯度更新了。
条件随机场和隐马尔可夫模型,哪个好?
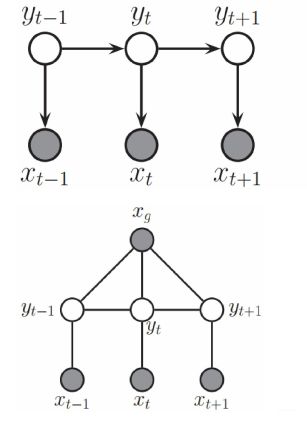
如图,上面是HMM,下面是CRF,HMM假设是当前x只和当前y有关,当前y只和前一个y有关,这个强假设带来很多局限,比如我们无法利用一些全局的信息,比如一个词的词性很可能是和它在句子中的位置有关系的,很可能和前几个词有关系的,这些特征在隐马尔可夫模型中都无法体现出来!所以条件随机场是更灵活的,可以认为添加任何你想要的特征,但是这带来的问题就是导致速度会变慢。还有一个区别,隐马模型是生成模型,条件随机场是判别模型,很多同学都没有理解清楚什么是生成模型,什么是判别模型,网上会告诉你说:区别就是生成模型是对联合概率进行建模,而判别模型则是对条件概率进行建模,这话其实没有问题,但是很多同学听不懂,个人认为还是邹博的解释最到位,就是说判别模型很好理解,给定了观测x,直接针对p(y|x)进行建模,然后输出的就是这个条件概率,而生成模型的思路就不同,生成模型认为,所有的观测反而是由某个概率分布来产生的,如hmm,认为所有的观测都是由要预测的值y来产生的,然后我们要建模的就是这种产生方式,即联合概率分布!这样说不知道大家理解了没有,那么很简单就可以把一般的模型分出来:LDA,HMM,都是生成模型,而crf, MEMM(最大熵隐马模型),LR,等等都是判别模型。
再多废话两句,其实发现了没有,隐马可以看成是特殊的CRF,就是当我们的CRF的特征只取当前x( x t x_t xt),以及前一个y( y t − 1 y_{t-1} yt−1)时,这个crf,就可以看成是一个HMM。
先到这里吧。有必要的再更新!