过拟合的解决方法:正则化、Dropout、batch normalization
1. 正则化
周志华老师的《机器学习》中写道:“正则化可理解为一种‘罚函数法’,即对不希望得到的结果施以惩罚,从而使得优化过程趋向于希望目标。从贝叶斯的角度来看,正则化项可认为是提供了模型的先验概率。”
正则化是一种回归的形式,它将系数估计(coefficient estimate)朝零的方向进行约束、调整或缩小。也就是说,正则化可以在学习过程中降低模型复杂度和不稳定程度,从而避免过拟合的危险
L2正则化:
目标函数中增加所有权重w参数的平方之和, 逼迫所有w尽可能趋向零但不为零. 因为过拟合的时候, 拟合函数需要顾忌每一个点, 最终形成的拟合函数波动很大, 在某些很小的区间里, 函数值的变化很剧烈, 也就是某些w非常大. 为此, L2正则化的加入就惩罚了权重变大的趋势.
L2 正则化公式非常简单,直接在原来的损失函数基础上加上权重参数的平方和:

其中,cost(f-y) 是未包含正则化项的训练样本误差,λ 是正则化参数,是可以调节的。但是正则化项是如何推导的?接下来,我将详细介绍其中的物理意义。
我们知道,正则化的目的是限制参数过多或者过大,避免模型更加复杂。例如,使用多项式模型,如果使用 10 阶多项式,模型可能过于复杂,容易发生过拟合。所以,为了防止过拟合,我们可以将其高阶部分的权重 w 限制为 0,这样,就相当于从高阶的形式转换为低阶。
为了达到这一目的,最直观的方法就是限制 w 的个数,但是这类条件属于 NP-hard 问题,求解非常困难。所以,只能选择另一个方法,限制参数w的大小,一般的做法是寻找更宽松的限定条件:

上式是对 w 的平方和做数值上界限定,即所有w 的平方和不超过参数 C。这时候,我们的目标就转换为:最小化训练样本误差 cost(f-y),但是要遵循 w 平方和小于 C 的条件。也可以理解为,在所有参数的平方和不超过C的前提条件下,还使得样本的训练误差最小。
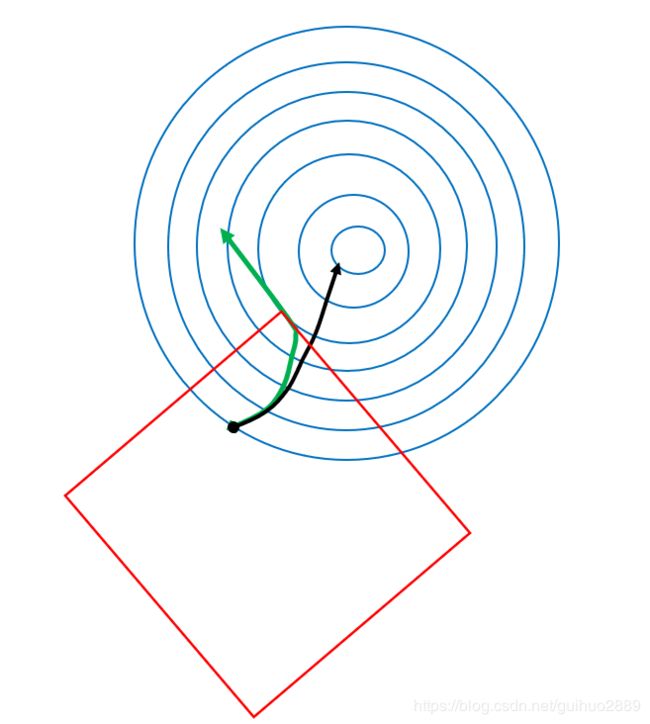
我们经常看见这样一句话:代价函数在“模型代价”和“正则化约束”两项规则的综合作用下,正则化后的模型参数应该收敛在“误差等值线”与“正则项等值线”的相切的位置。下面会解释它的含义。

红色表示的是“正则项等值线”,蓝色的表示的是cost(f-y)的等值线,不一定是圆,这里用圆表示。在没有正则化项时,黑色箭头是梯度的下降方向,在有了正则化项以后,相当于给运动的箭头施加了约束,一方面,我不能逃离红色箭头的约束范围,另一方面,又要保证箭头要向着梯度减小的方向运动,故而运动的曲线是图中的绿色剪头。当红色箭头和绿色剪头相切的时候,不能够再继续向下运动了,因为它就逃离了红色范围的约束。
现在可以解释正则化“惩罚”二字的含义了。它惩罚的是总的“成本函数”,因为从图中可以看出,黑色箭头到达终点后的“代价函数”很明显是低于绿色剪头所到达的终点处的代价函数,即增加正则化项之后,代价适当增大了,即模型收到了“惩罚”。根据方差-偏差分解原则,偏差增大,方差会减小,方差减小,防止过拟合的能力增强。
数学推导:

L1正则化:
目标函数中增加所有权重w参数的绝对值之和, 逼迫更多w为零(也就是变稀疏. L2因为其导数也趋0, 奔向零的速度不如L1给力了). 大家对稀疏规则化趋之若鹜的一个关键原因在于它能实现特征的自动选择。一般来说,xi的大部分元素(也就是特征)都是和最终的输出yi没有关系或者不提供任何信息的,在最小化目标函数的时候考虑xi这些额外的特征,虽然可以获得更小的训练误差,但在预测新的样本时,这些没用的特征权重反而会被考虑,从而干扰了对正确yi的预测。稀疏规则化算子的引入就是为了完成特征自动选择的光荣使命,它会学习地去掉这些无用的特征,也就是把这些特征对应的权重置为0。
其定义为:
根据L2的定义方式,则有,此处依然以两个参数w1,w2为例,则有
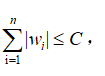
|w1|+|w2|<=C 它的图形为一个正方形,如下所示:
Cost(f-y)优化算法不变,L1 正则化限定了 w 的有效区域是一个正方形,且满足 |w| < C。空间中的点 w 沿着 cost(f-y)的方向移动。但是,与此同时w 不能离开红色正方形区域,最多只能位于正方形边缘位置。其推导过程与 L2 类似,就不再重复说明了。
2. Dropout
在训练的运行的时候,让神经元以超参数p的概率被激活(也就是1-p的概率被设置为0), 每个w因此随机参与, 使得任意w都不是不可或缺的, 效果类似于数量巨大的模型集成。
Dropout可以作为训练深度神经网络的一种trick供选择。在每个训练批次中,通过忽略一半的特征检测器(让一半的隐层节点值为0),可以明显地减少过拟合现象。这种方式可以减少特征检测器(隐层节点)间的相互作用,检测器相互作用是指某些检测器依赖其他检测器才能发挥作用。
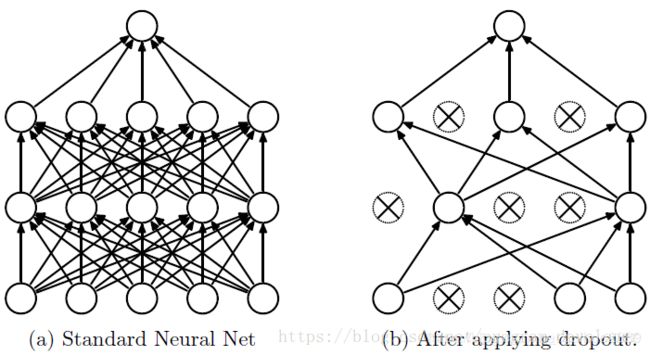
Dropout说的简单一点就是:我们在前向传播的时候,让某个神经元的激活值以一定的概率p停止工作,这样可以使模型泛化性更强,因为它不会太依赖某些局部的特征,如图1所示。
工作流程:
(1)首先随机(临时)删掉网络中一半的隐藏神经元,输入输出神经元保持不变(图3中虚线为部分临时被删除的神经元)
(2) 然后把输入x通过修改后的网络前向传播,然后把得到的损失结果通过修改的网络反向传播。一小批训练样本执行完这个过程后,在没有被删除的神经元上按照随机梯度下降法更新对应的参数(w,b)。
(3)然后继续重复这一过程:
. 恢复被删掉的神经元(此时被删除的神经元保持原样,而没有被删除的神经元已经有所更新)
. 从隐藏层神经元中随机选择一个一半大小的子集临时删除掉(备份被删除神经元的参数)。
. 对一小批训练样本,先前向传播然后反向传播损失并根据随机梯度下降法更新参数(w,b) (没有被删除的那一部分参数得到更新,删除的神经元参数保持被删除前的结果)。
不断重复这一过程。
下面,我们具体讲解一下Dropout代码层面的一些公式推导及代码实现思路。
(1)在训练模型阶段

对应的公式变化如下:
- . 没有Dropout的网络计算公式:
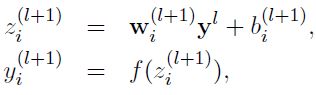
- 采用Dropout的网络计算公式:
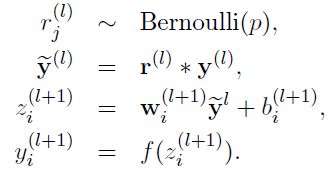
上面公式中Bernoulli函数是为了生成概率r向量,也就是随机生成一个0、1的向量。
源码分析
Keras实现源码:

# coding:utf-8
import numpy as np
# dropout函数的实现
def dropout(x, level):
if level < 0. or level >= 1: #level是概率值,必须在0~1之间
raise ValueError('Dropout level must be in interval [0, 1[.')
retain_prob = 1. - level
# 我们通过binomial函数,生成与x一样的维数向量。binomial函数就像抛硬币一样,我们可以把每个神经元当做抛硬币一样
# 硬币 正面的概率为p,n表示每个神经元试验的次数
# 因为我们每个神经元只需要抛一次就可以了所以n=1,size参数是我们有多少个硬币。
random_tensor = np.random.binomial(n=1, p=retain_prob, size=x.shape) #即将生成一个0、1分布的向量,0表示这个神经元被屏蔽,不工作了,也就是dropout了
print(random_tensor)
x *= random_tensor
print(x)
x /= retain_prob
return x
#对dropout的测试,大家可以跑一下上面的函数,了解一个输入x向量,经过dropout的结果
x=np.asarray([1,2,3,4,5,6,7,8,9,10],dtype=np.float32)
dropout(x,0.4)注意: Keras中Dropout的实现,是屏蔽掉某些神经元,使其激活值为0以后,对激活值向量x1……x1000进行放大,也就是乘以1/(1-p)。
思考:上面我们介绍了两种方法进行Dropout的缩放,那么Dropout为什么需要进行缩放呢?
因为我们训练的时候会随机的丢弃一些神经元,但是预测的时候就没办法随机丢弃了。如果丢弃一些神经元,这会带来结果不稳定的问题,也就是给定一个测试数据,有时候输出a有时候输出b,结果不稳定,这是实际系统不能接受的,用户可能认为模型预测不准。那么一种”补偿“的方案就是每个神经元的权重都乘以一个p,这样在“总体上”使得测试数据和训练数据是大致一样的。比如一个神经元的输出是x,那么在训练的时候它有p的概率参与训练,(1-p)的概率丢弃,那么它输出的期望是px+(1-p)0=px。因此测试的时候把这个神经元的权重乘以p可以得到同样的期望。
原文:https://blog.csdn.net/program_developer/article/details/80737724
3. Batch Normalization
机器学习领域有个很重要的假设:IID独立同分布假设,就是假设训练数据和测试数据是满足相同分布的,这是通过训练数据获得的模型能够在测试集获得好的效果的一个基本保障。那BatchNorm的作用是什么呢?BatchNorm就是在深度神经网络训练过程中使得每一层神经网络的输入保持相同分布的。
如果ML系统实例集合
然后提出了BatchNorm的基本思想:能不能让每个隐层节点的激活输入分布固定下来呢?
BN不是凭空拍脑袋拍出来的好点子,它是有启发来源的:之前的研究表明如果在图像处理中对输入图像进行白化(Whiten)操作的话——所谓白化,就是对输入数据分布变换到0均值,单位方差的正态分布——那么神经网络会较快收敛,那么BN作者就开始推论了:图像是深度神经网络的输入层,做白化能加快收敛,那么其实对于深度网络来说,其中某个隐层的神经元是下一层的输入,意思是其实深度神经网络的每一个隐层都是输入层,不过是相对下一层来说而已,那么能不能对每个隐层都做白化呢?这就是启发BN产生的原初想法,而BN也确实就是这么做的,可以理解为对深层神经网络每个隐层神经元的激活值做简化版本的白化操作。
本质思想
BN的基本思想其实相当直观:因为深层神经网络在做非线性变换前的激活输入值(就是那个x=WU+B,U是输入)随着网络深度加深或者在训练过程中,其分布逐渐发生偏移或者变动,之所以训练收敛慢,一般是整体分布逐渐往非线性函数的取值区间的上下限两端靠近(对于Sigmoid函数来说,意味着激活输入值WU+B是大的负值或正值),所以这导致反向传播时低层神经网络的梯度消失,这是训练深层神经网络收敛越来越慢的本质原因,而BN就是通过一定的规范化手段,把每层神经网络任意神经元这个输入值的分布强行拉回到均值为0方差为1的标准正态分布,其实就是把越来越偏的分布强制拉回比较标准的分布,这样使得激活输入值落在非线性函数对输入比较敏感的区域,这样输入的小变化就会导致损失函数较大的变化,意思是这样让梯度变大,避免梯度消失问题产生,而且梯度变大意味着学习收敛速度快,能大大加快训练速度。
其实一句话就是:对于每个隐层神经元,把逐渐向非线性函数映射后向取值区间极限饱和区靠拢的输入分布强制拉回到均值为0方差为1的比较标准的正态分布,使得非线性变换函数的输入值落入对输入比较敏感的区域,以此避免梯度消失问题。因为梯度一直都能保持比较大的状态,所以很明显对神经网络的参数调整效率比较高,就是变动大,就是说向损失函数最优值迈动的步子大,也就是说收敛地快。
训练阶段如何做BatchNorm
对于Mini-Batch SGD来说,一次训练过程里面包含m个训练实例,其具体BN操作就是对于隐层内每个神经元的激活值来说,进行如下变换:

要注意,这里t层某个神经元的x(k)不是指原始输入,就是说不是t-1层每个神经元的输出,而是t层这个神经元的线性激活x=WU+B,这里的U才是t-1层神经元的输出。变换的意思是:某个神经元对应的原始的激活x通过减去mini-Batch内m个实例获得的m个激活x求得的均值E(x)并除以求得的方差Var(x)来进行转换。
变换后某个神经元的激活x形成了均值为0,方差为1的正态分布,目的是把值往后续要进行的非线性变换的线性区拉动,增大导数值,增强反向传播信息流动性,加快训练收敛速度。但是这样会导致网络表达能力下降,为了防止这一点,每个神经元增加两个调节参数(scale和shift),这两个参数是通过训练来学习到的,用来对变换后的激活反变换,使得网络表达能力增强,即对变换后的激活进行如下的scale和shift操作,这其实是变换的反操作:

具体流程:

BatchNorm的推理(Inference)过程
BN在训练的时候可以根据Mini-Batch里的若干训练实例进行激活数值调整,但是在推理(inference)的过程中,很明显输入就只有一个实例,看不到Mini-Batch其它实例,那么这时候怎么对输入做BN呢?因为很明显一个实例是没法算实例集合求出的均值和方差的。这可如何是好?
既然没有从Mini-Batch数据里可以得到的统计量,那就想其它办法来获得这个统计量,就是均值和方差。可以用从所有训练实例中获得的统计量来代替Mini-Batch里面m个训练实例获得的均值和方差统计量,因为本来就打算用全局的统计量,只是因为计算量等太大所以才会用Mini-Batch这种简化方式的,那么在推理的时候直接用全局统计量即可。
决定了获得统计量的数据范围,那么接下来的问题是如何获得均值和方差的问题。很简单,因为每次做Mini-Batch训练时,都会有那个Mini-Batch里m个训练实例获得的均值和方差,现在要全局统计量,只要把每个Mini-Batch的均值和方差统计量记住,然后对这些均值和方差求其对应的数学期望即可得出全局统计量,即:
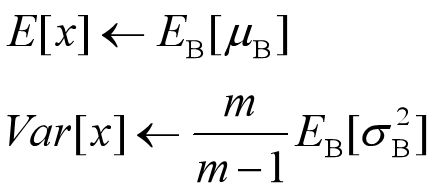
有了均值和方差,每个隐层神经元也已经有对应训练好的Scaling参数和Shift参数,就可以在推导的时候对每个神经元的激活数据计算BN进行变换了,在推理过程中进行BN采取如下方式:

这个公式其实和训练时

是等价的,通过简单的合并计算推导就可以得出这个结论。那么为啥要写成这个变换形式呢?我猜作者这么写的意思是:在实际运行的时候,按照这种变体形式可以减少计算量,为啥呢?因为对于每个隐层节点来说:

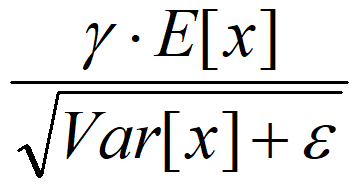
都是固定值,这样这两个值可以事先算好存起来,在推理的时候直接用就行了,这样比原始的公式每一步骤都现算少了除法的运算过程,乍一看也没少多少计算量,但是如果隐层节点个数多的话节省的计算量就比较多了。
原文:https://www.cnblogs.com/guoyaohua/p/8724433.html