Kylin的介绍及使用说明
介绍篇
Kylin是ebay开发的一套OLAP系统,与Mondrian不同的是,它是一个MOLAP系统,主要用于支持大数据生态圈的数据分析业务,它主要是通过预计算的方式将用户设定的多维立方体缓存到HBase中(目前还仅支持hbase),这段时间对mondrian和kylin都进行了使用,发现这两个系统是时间和空间的一个权衡吧,mondrian是一个ROLAP系统,所有的查询可以通过实时的数据库查询完成,而不会有任何的预计算,大大节约了存储空间的要求(但是会有查询结果的缓存,目前是缓存在程序内存中,很容易导致OOM),而kylin是一个MOLAP系统,通过预计算的方式缓存了所有需要查询的的数据结果,需要大量的存储空间(原数据量的10+倍)。一般我们要分析的数据可能存储在关系数据库(mysql、oracle,一般是程序内部写入的一些业务数据,可能存在分表甚至分库的需求)、HDFS上数据(结构化数据,一般是业务的日志信息,通过hive查询)、文本文件、excel等。kylin主要是对hive中的数据进行预计算,利用hadoop的mapreduce框架实现。而mondrian理论上可以支持任意的提供SQL接口数据,由于关系数据库一般会存在索引,所以即使使用mondrian去查询性能还是可以接受的,当前我们使用的oracle数据库,千万条级别的记录,查询可以在分钟级别完成,但是对于hive、这样的数据源查询就太慢了,慢得不可以接受。
系统架构
于是,我们开始尝试使用kylin,kylin的出现就是为了解决大数据系统中TB级别数据的数据分析需求,而对于关系数据库中的数据分析进行预计算可能有点不合适了(关系数据库一般存在索引使得即使数据量很大查询也不会慢的离谱,除非SQL写的很烂)。在使用kylin的过程中,也逐渐对kylin有了一定的认识,首先看一下kylin的系统架构
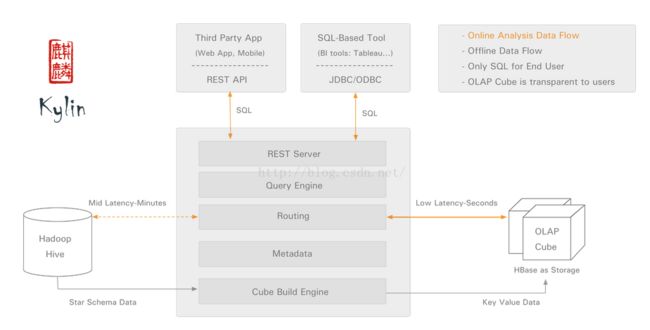
Kylin系统架构
kylin由以下几部分组成:
· REST Server:提供一些restful接口,例如创建cube、构建cube、刷新cube、合并cube等cube的操作,project、table、cube等元数据管理、用户访问权限、系统配置动态修改等。除此之外还可以通过该接口实现SQL的查询,这些接口一方面可以通过第三方程序的调用,另一方也被kylin的web界面使用。
· jdbc/odbc接口:kylin提供了jdbc的驱动,驱动的classname为org.apache.kylin.jdbc.Driver,使用的url的前缀jdbc:kylin:,使用jdbc接口的查询走的流程和使用RESTFul接口查询走的内部流程是相同的。这类接口也使得kylin很好的兼容tebleau甚至mondrian。
· Query引擎:kylin使用一个开源的Calcite框架实现SQL的解析,相当于SQL引擎层。
· Routing:该模块负责将解析SQL生成的执行计划转换成cube缓存的查询,cube是通过预计算缓存在hbase中,这部分查询是可以再秒级甚至毫秒级完成,而还有一些操作使用过查询原始数据(存储在hadoop上通过hive上查询),这部分查询的延迟比较高。
· Metadata:kylin中有大量的元数据信息,包括cube的定义,星状模型的定义、job的信息、job的输出信息、维度的directory信息等等,元数据和cube都存储在hbase中,存储的格式是json字符串,除此之外,还可以选择将元数据存储在本地文件系统。
· Cube构建引擎:这个模块是所有模块的基础,它负责预计算创建cube,创建的过程是通过hive读取原始数据然后通过一些mapreduce计算生成Htable然后load到hbase中。
Kylin的使用说明
四部分来讲解
1、创建project
2、构建model
- 3、构建cube
- 4、增量cube构建
创建project
1:创建project进入kylin操作界面,如果没有project可以创建,kylin里面可以创建多个project,有效的把各种业务数据分析隔离开来。如图:

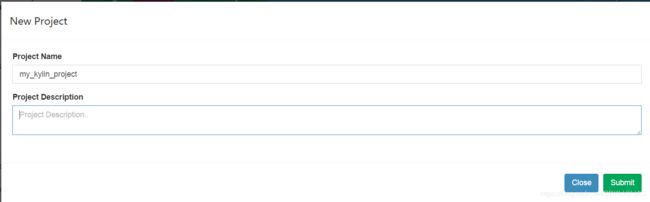
如下,填写project name,description可以不填
然后submit 提交,project创建成功。
特别注意的是项目建议建一个,太多的话,前段查询需要来回切换的。
添加数据源


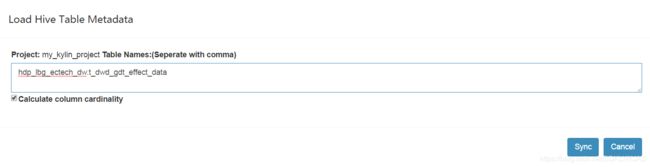
然后点击sync,导入数据源成功,可以看到如下信息:
构建model
3.创建model
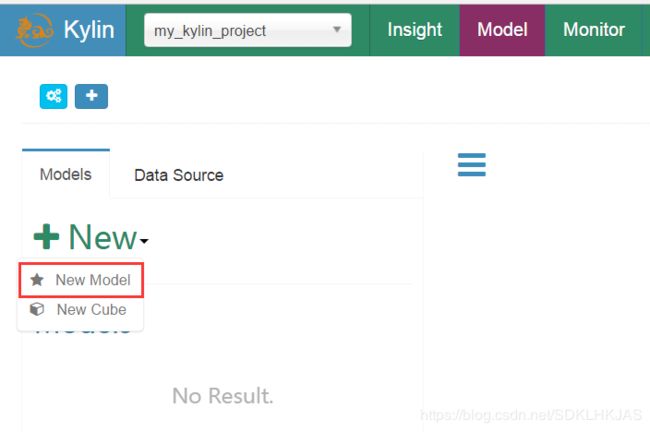
添加model name然后 next
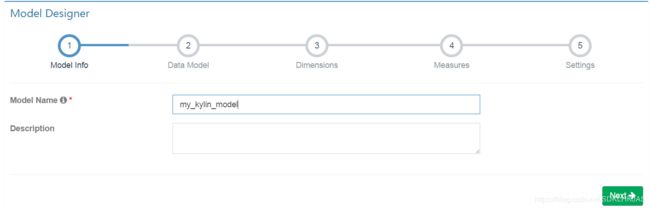
选择刚才添加到数据源中的模型表,Lookup Table类似外键表这里不要,然后next
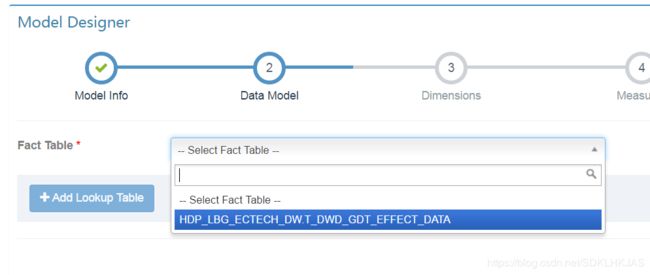
选择需要的维度

选择需要的指标
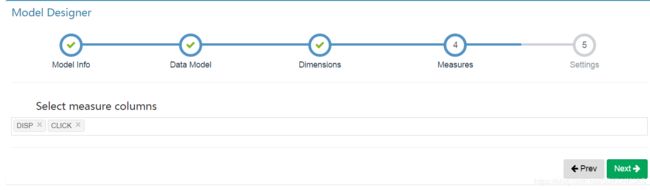
相关设置
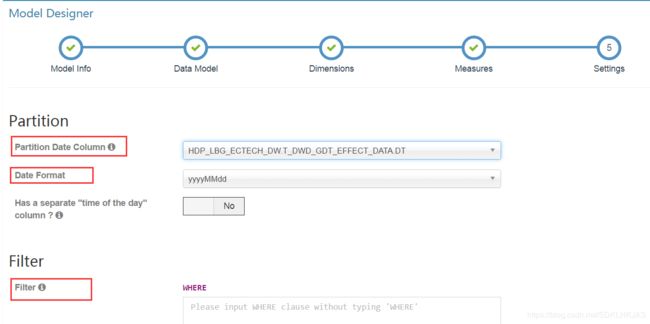
partition date colume表示分区字段,选择一个时间字段作为依据,或者选择hive表中按时间分区的字段。然后从date format中选择不同的时间格式。最下面的filter可以添加where条件对数据源中的数据做过滤。
至此,model创建完成。
创建cube
下面进入关键环节创建cube。在刚刚选择new model的下面 有new cube
类似于创建model,创建cube。选择之前创建好的model,并填入cube name。notification email list是选填项,表示报警接收人邮件地址,多个邮件地址以逗号隔开。

然后next。选择dimession,然后勾选需要的字段。


然后next,选择指标

count(1)是系统默认自带的,不要删除。
点击+号添加需要的指标,需要填入名称,选择表达式。这里选择的是sum。我们要针对disp加和求pv,在param value里面选择disp列。
需要注意的是kylin中hive表中每一列字段的类型要求比较严格。dimession字段需要为String,用来加和的指标字段须为bigint或者decimal
添加了所有需要的指标后,点击next
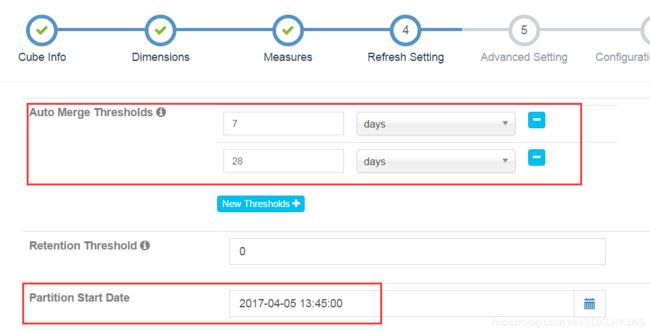
设置merge时间。Kylin每次build会生成一张hbase表,merge操作会把多天数据合并成一张新的hbase表。可加快查询。
设置partition Start Date,即数据源开始时间,默认为1970-01-01.点击Next.
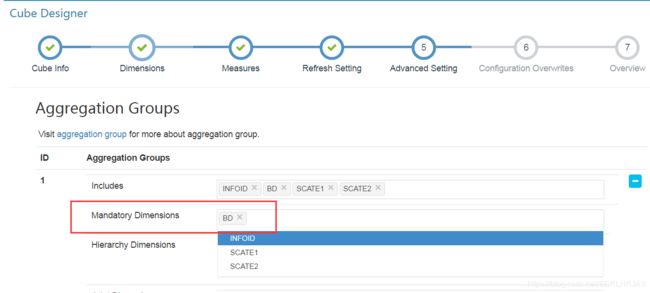
Mandatory Dimensions:每次查询均会使用的维度可添加在此。比如某些情况下的partition column.
Hierarchy Dimensions:维度列中彼此间存在层级关系的列,比如“国家-省份-市-县”
Joint Dimensions:每次查询会同时使用或不使用的维度组合。
Aggregation Group:在不同的查询中,两组维度组合之间不会产生交叉,可选择此选项,比如所有的cube维度有 [ a,b,c,d,e,f ] 6个,每次查询中只会同时查与 [ a,b,c ] 相关的信息(比如[a],[a,c]等)而不会查询 [ d,e,f ],或者相反,则可选择此选项。
以上选择均可减少build过程中的数据量,是加快build与query速度的优化点之一。
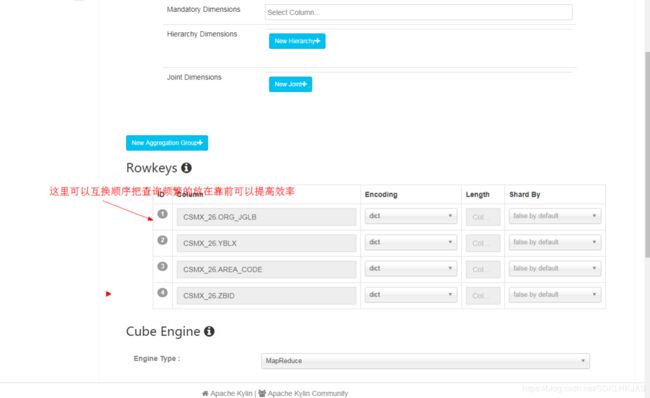

接下来基本上就是next,然后保存,如果没有报错,则证明cube创建成功,如下图

5.cube其他操作
最常用的就是build操作,它会根据我们创建的cube进行数据的预计算。
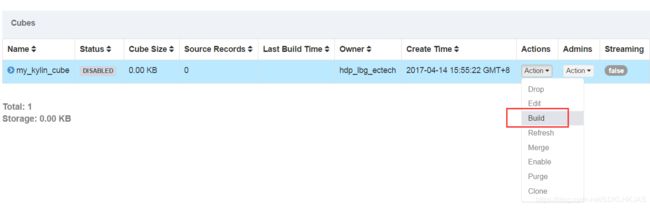
选择构建的终止时间,然后提交,之后可以在monitor中看到cube构建的状态。
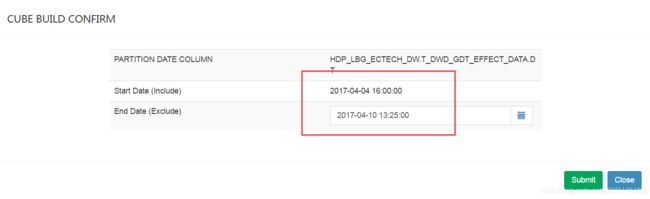
其他操作说明:
Drop:丢弃现有cube,条件:无Pending, Running, Error 状态的job.
Edit:编辑现有cube,条件:cube需处于disable状态。
Refresh:重建某已有时间段数据,针对于已build时间段的源数据发生了改变的情况。
Merge:手动触发merge操作。
Enable:使拥有至少一个有效segment的cube从disable变为enable状态。
Purge:清空所有该cube的数据。
Clone:克隆一个新的cube,可设置新的名字,其他相关配置与原cube相同。
Disable:使一个处于ready状态的cube变为Disable状态,查询不会从disable的cube中获取数据。
kylin 增量更新cube设置
前提是在构建model时选择一个时间字段作为分区 上面构建model 时有说明
Kylin 使用RESTful API进行cube的增量更新
接下来我们要处理上线之后定时任务,因为hive是以时间作为分区,每天有增量数据,所以需要再kylin每天增量写入数据:
1:Kylin的认证是basic authentication,加密算法是Base64,加密的明文为username:password;在POST的header进行用户认证:
curl -X POST -H "Authorization: Basic xxxxxxxx=" -H 'Content-Type: application/json' http://hostname:port/kylin/api/user/authentication
可以在hive或者spark-sql里面进行base64加密算法获取:
生成鉴权文件,之后每一步都需要使用cookfile.txt
curl -c cookfile.txt -X POST \-H "Authorization:Basic QURNSU46S1lMSU4=" \-H "Content-Type: application/json" \
http://hostname:7070/kylin/api/user/authentication4
2:在认证完成之后,可以复用cookie文件(不再需要重新认证),向Kylin发送GET或POST请求,比如,查询cube的信息:
curl -b cookiefile.txt -H 'Content-Type: application/json' http://hostname:port/kylin/api/cubes/cube_name
返回信息:
{"uuid":"xxxxxxxxxxxx","last_modified":1540804968611,"version":"2.5.0.20500","name":"cube_name","owner":"username","descriptor":"cube_name","display_name":"cube_name",
"cost":50,"status":"DISABLED","segments":[],"create_time_utc":1540535981140,"cuboid_bytes":null,"cuboid_bytes_recommend":null,"cuboid_last_optimized":0,"snapshots":{}}
通过RESTful API查询SQL:
curl -b cookiefile.txt --user username:password -X POST -H 'Content-Type: application/json' -d '{"sql":"select count(1) from table_name group by partition_name", "offset":0, "limit":10, "acceptPartial":false, "project":"project_name"}' http://hostname:port/kylin/api/query
其中,offset为sql中相对记录首行的偏移量,limit为限制记录条数;二者在后台处理时都会拼接到sql中去。发送sql query的curl命令:
熟悉了curlful API之后然后进行sh的定时:
#!/bin/bash
cubeName=cube_name
today=`date -d "1 days ago" +%Y-%m-%d`
tdTs=`date -d "$today 08:00:00" +%s`
endTime=$(($tdTs*1000))
curl -b cookiefile.txt --user username:password -X PUT -H 'Content-Type: application/json' -d '{"startTime":'xxxxxxx',"endTime":'$endTime',"buildType":"BUILD"}' http://hostname:port/kylin/api/cubes/$cubeName/rebuild
startTime : 做增量时,startTime 为上一次build的endTime。
endTime:时间精确到毫秒。
buildType:可选BUILD,MERGE,REDRESH
注意事项:通过RESTful API向kylin进行build和rebuild的时候一定要观察kylin的web界面下面的Montior进程,否知一不小心运行太多进程导致服务器崩掉。
当cube build过程中出错,重新执行
curl -b cookfile.txt -X PUT -H "Content-Type: application/json" http://hostname:port/kylin/api/jobs/uuid/resume
uuid:从cube提交build时返回的json格式数据中获得。
---------------------
一、生成鉴权文件,之后每一步都需要使用cookfile.txt
curl -c cookfile.txt -X POST \-H "Authorization:Basic QURNSU46S1lMSU4=" \-H "Content-Type: application/json" \
http://hostname:7070/kylin/api/user/authentication
ADMIN:KYLIN使用Base64编码后的结果为:QURNSU46S1lMSU4=。
-c : cookie写入的文件。
-H : 自定义header传递给服务器。
-X : 指定使用的请求命令。
返回json格式结果如下:
{
"userDetails": {
"accountNonExpired": true,
"accountNonLocked": true,
"authorities": [
{
"authority": "ROLE_ADMIN"
},
{
"authority": "ROLE_ANALYST"
},
{
"authority": "ROLE_MODELER"
}
],
"credentialsNonExpired": true,
"enabled": true,
"password": null,
"username": "ADMIN"
}}
二、获取project下面所有的cube
curl -b cookfile.txt \
-X GET \-H "Content-Type: application/json" \hostname:7070/kylin/api/cubes?projectName=TEST\&offset=0\&limit=1
projectName:工程名大写
projectName=TEST\&offset=0\&limit=1:在linux系统中& 会使进程系统后台运行
必须对&进行下转义才能$_GET获取到所有参数。我开始没有转义&,只获取到了第一个参数。
三、获取一个cube的详细信息
curl -b cookfile.txt \
-H "Content-Type: application/json" \hostname:7070/kylin/api/cubes/cubeName
- 3
四、获取一个model的信息
curl -b cookfile.txt \
-H "Content-Type: application/json" \hostname:7070/kylin/api/model/modelName
- 3
五、更新cube,增量更新cube
curl -b cookfile.txt \-X PUT -H "Content-Type: application/json" \-d '{"endTime":'1483977600000',"buildType":"BUILD"}' \
http://fwq-014:7070/kylin/api/cubes/ mdl_kj__cube_1/rebuild
- 4
- 5
startTime : 做增量时,startTime 为上一次build的endTime。
endTime:时间精确到毫秒。
buildType:可选BUILD,MERGE,REDRESH
六、获取cube在build过程的状态
curl -b cookfile.txt \-X GET \
http://hostname:7070/kylin/api/jobs/uuid
- 3
uuid:从cube提交build时返回的json格式数据中获得。
返回结果中job_status有FINISHED,ERROR,DISCARDED等状态。
七、当cube build过程中出错,重新执行
curl -b cookfile.txt \-X PUT -H "Content-Type: application/json" \
http://hostname:7070/kylin/api/jobs/uuid/resume
uuid:从cube提交build时返回的json格式数据中获得。
八、通过RESTful API查询SQL
curl -b cookfile.txt \
-X post \
-H "Content-Type: application/json" \
-d '{
"sql":"select part_dt,sum(price) as total_selled,count(distinct seller_id) as sellers from KYLIN_SALES group by part_dt",
"offset":0,
"limit":2,
"acceptPartial":false,
"project":"LEARN_KYLIN"
}' http://hostname:7070/kylin/api/query
- 10
先写这些,以上查询返回结果均为json格式数据。
shell调度这些命令执行可以使用jq工具解析json数据。关于jq的使用不在本篇讨论范围,下面给一个例子,获取一个工程下所有cube列表。
array_cube=()
cubeList=`curl -b cookfile.txt \
-X GET \
-H "Content-Type: application/json" \
http://hostname:7070/kylin/api/cubes?projectName=${projectName}`
cube=`echo ${cubeList} | jq -r '.'[0]'.name'`
i=0while [ "$cube" != "null" ]; do
status=`echo ${cubeList} | jq -r '.'[${i}]'.status'`
if [ "$status" = "READY" ]; then
array_cube[ ${i} ]=${cube}
fi
let i++
cube=`echo ${cubeList}|jq -r '.'[${i}]'.name'`done#echo ${array_cube[@]}
完整脚本,亲测没有问题
#!/bin/bash -
cubeName=daily_monthly_alive
today=`date +%Y-%m-%d`
tdTs=`date -d "$today 08:00:00" +%s`
endTime=$(($tdTs*1000))
curl --user ADMIN:KYLIN -X PUT -H 'Content-Type: application/json' -d '{"endTime":'$endTime', "buildType":"BUILD"}' http://hostip:port/kylin/api/cubes/$cubeName/rebuild
-----分割线----------------------
ps:
1、官网给出的批量更新是
http://kylin.apache.org/docs21/howto/howto_use_restapi.html
由于没有成功授权,还用的是用户名密码的形式--user ADMIN:KYLIN
( 后期通过java调用Http post请求,授权成功)
http://kylin.apache.org/docs21/howto/howto_build_cube_with_restapi.html
2、指定startTime和endtime也可以直接创建cube
curl --user ADMIN:KYLIN -X PUT -H 'Content-Type: application/json' -d '{"endTime":'$endTime', "buildType":"BUILD"}' http://hostip:port/kylin/api/cubes/$cubeName/build
注意model和cube构建名应让其有唯一性
定期清理临时表一些垃圾文件
清理命令
# 查看需要清理的数据
./bin/kylin.sh org.apache.kylin.tool.StorageCleanupJob --delete false
# 清理
./bin/kylin.sh org.apache.kylin.tool.StorageCleanupJob --delete true