
ResNet 在2015年被提出,在 ImageNet 比赛分类任务上获得第一名,因为其简单与实用完美结合,被广泛应用在物体检测、分割和识别等领域。

说到 ResNet 不能不提及一下学术明星何凯明、在这里让我们仰视一下这位大神。
ResNet是解决了深度 CNN 模型难训练的问题,2014 年的的冠军 VGGNet 才只能做到 19 层,而 15 年的ResNet 就可以达到152层。远远超过其对手。

深度网络的退化问题
-
网络的深度对模型的性能至关重要,当增加网络层数后,网络就可以进行提取更复杂的特征,所以当模型更深时理论上可以取得更好的结果。但是事实证明更深的网络并不能提高训练精度,这是加深网络层次后出现了退化线性。
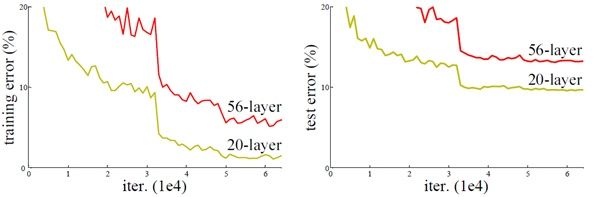 退化问题
退化问题 网络深度增加一定时候,可能出现准确度饱和,甚至出现下降。这个现象可以在下图中直观看出来:50 多层的网络比 20 多层网络效果还要差。这不会是过拟合问题,因为 50 多层网络的训练误差同样高。知道深层网络存在着梯度消失或者梯度爆炸的问题,这使得深度学习模型很难训练。
梯度消失或者梯度爆炸的问题
由于神经网络经过激活函数变为非线性,
这是因为 sigmoid 和 tanh 可能会发生梯度消失。这是因为他们导数都是小于 0 的,在反向传播时候,因为经过多层后小于 0 数连续
模型在使用梯度下降法对误差进行反向传播时会出现梯度消失和梯度爆炸问题。随着神经网络层数增加,梯度消失问题和梯度爆炸问题一般会随着网络层数的增加变得越来越明显。
残差学习
深度网络的退化问题至少说明深度网络不容易训练。但是考虑这样一个事实:现在你有一个浅层网络,通过向上堆积新层来建立深层网络,一个极端情况是这些增加的层什么也不学习,仅仅复制浅层网络的特征,即这样新层是恒等映射。在这种情况下,深层网络应该至少和浅层网络性能一样,也不应该出现退化现象。
何博士提出了残差学习来解决退化问题。对于一个堆积层结构(几层堆积而成)当输入为X 时其学习到的特征记为 ,现在希望其可以学习到残差,这样其实原始的学习特征是
当残差为 0 时,此时堆积层仅仅做了恒等映射,至少网络性能不会下降,实际上残差不会为 0,这也会使得堆积层在输入特征基础上学习到新的特征,从而拥有更好的性能。残差学习的结构如图4所示。这有点类似与电路中的短路,所以是一种短路连接(shortcut connection)。
残差学习是如何学习
从直观上看残差学习需要学习的内容少,因为残差一般会比较小,学习难度小点,但这样的理由太不严谨了,下面尝试用数学方法对其进行说明:
其中 和 分别表示 l 个残差块层输入和输出,注意么一个残差块一般都包含多层结构 F 是残差函数,表示学习到的残差,而 表示恒等的映射,f 是 ReLu 激活函数,基本上我们从浅层 l 网络学习到深层 L 的学习特征为:
表示损失函数到达 L 的梯度,小括号中的 1 表示短路机制可以无损地传播梯度,而另外一项残差梯度则需要经过带有 weights 的层,梯度不是直接传递过来的。残差梯度不会那么巧全为 -1 而且就算是比较小,有 1 的存在也不会导致梯度消失。所以残差学习会更容易,注意上面的推导并不是严格的证明。
也就是说,某种程度上看,残差学习解决了由于网络深度增加引起的梯度爆炸和梯度消失问题,因此能够有效加深网络的深度,使得结果更好。
Resnet 网络结构
ResNet网络是参考了VGG19 网络,在其基础上进行了修改,并通过短路机制加入了残差单元。
变化主要体现在 ResNet 直接使用stride=2的卷积做下采样,并且用global average pool 层替换了全连接层。ResNet的一个重要设计原则是:当 feature map大小降低一半时,feature map的数量增加一倍,这保持了网络层的复杂度。
ResNet 相比普通网络每两层间增加了短路机制,这就形成了残差学习,其中虚线表示 feature map 数量发生了改变。图5展示的 34-layer 的ResNet,还可以构建更深的网络如表1所示。从表中可以看到,对于18-layer和34-layer的ResNet,其进行的两层间的残差学习,当网络更深时,其进行的是三层间的残差学习,三层卷积核分别是1x1,3x3 和1x1,一个值得注意的是隐含层的 feature map 数量是比较小的,并且是输出feature map数量的1/4
对于短路连接,当输入和输出维度一致时,可以直接将输入加到输出上。但是当维度不一致时(对应的是维度增加一倍),这就不能直接相加。有两种策略:
- 采用补零增加维度,此时一般要先做一个降采样,可以采用strde=2 的池化层,这样不会增加参数
- 采用新的映射,一般采用 1x1 的卷积,这样会增加参数,也会增加计算量。短路连接除了直接使用恒等映射,当然都可以采用projection shortcut。
不同的残差结构
import tensorflow as tf
# print(tf.__version__)
import numpy as np
import cPickle
import os
import utils
from utils import CifarData
# save file format as numpy
# file format as cPickle
CIFAR_DIR = "./cifar-10-batches"
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
# print(os.listdir(CIFAR_DIR))
train_filenames = [os.path.join(CIFAR_DIR, 'data_batch_%d' % i)
for i in range(1, 6)]
test_filenames = [os.path.join(CIFAR_DIR, 'test_batch')]
train_data = CifarData(train_filenames, True)
test_data = CifarData(test_filenames, False)
# None present confirm count of smaples
# reduce size of smapling
def residual_block(x,output_channel):
""" residual connection implementation """
#
input_channel = x.get_shape().as_list()[-1]
if input_channel * 2 == output_channel:
increase_dim = True
strides = (2,2)
elif input_channel == output_channel:
increase_dim = False
strides = (1,1)
else:
raise Exception("input channel can't match output channel")
conv1 = tf.layers.conv2d(x,
output_channel,
(3,3),
strides = strides,
padding= 'same',
activation = tf.nn.relu,
name='conv1')
conv2 = tf.layers.conv2d(conv1,
output_channel,
(3,3),
strides = (1,1),
padding= 'same',
activation = tf.nn.relu,
name='conv2')
if increase_dim:
# [None,image_width,image_height,channel]
pooled_x = tf.layers.average_pooling2d(x,(2,2),(2,2),padding='valid')
padded_x = tf.pad(pooled_x,
[[0,0],[0,0],[0,0],[input_channel // 2,input_channel // 2]])
else:
padded_x = x
output_x = conv2 + padded_x
return output_x
def res_net(x,
num_residual_blocks,
num_filter_base,
class_num):
""" residual network implementation """
"""
x
num_residual_blocks: eg:[3,4,6,3] define block
num_filter_base:
class_num:
"""
num_subsampling = len(num_residual_blocks)
layers = []
# X: [None, width, height, channel ] -> width height channel
input_size = x.get_shape().as_list()[1:]
with tf.variable_scope('conv0'):
conv0 = tf.layers.conv2d(x,num_filter_base,(3,3),strides=(1,1),padding='same',activation=tf.nn.relu,name='conv0')
layers.append(conv0)
# num_subsampling = 4 sample_id = [0,1,2,3]
for sample_id in range(num_subsampling):
for i in range(num_residual_blocks[sample_id]):
with tf.variable_scope('conv%d_%d' % (sample_id,i)):
conv = residual_block(layers[-1],num_filter_base*(2 ** sample_id))
layers.append(conv)
multiplier = 2 ** (num_subsampling - 1 )
assert layers[-1].get_shape().as_list()[1:] == [input_size[0] / multiplier, input_size[1] / multiplier, num_filter_base * multiplier]
with tf.variable_scope('fc'):
# layer[-1].shape : [None, width, height, channel]
global_pool = tf.reduce_mean(layers[-1],[1,2])
logits = tf.layers.dense(global_pool,class_num)
layers.append(logits)
return layers[-1]
x = tf.placeholder(tf.float32,[None,3072])
y = tf.placeholder(tf.int64,[None])
x_image = tf.reshape(x,[-1,3,32,32])
# 32 * 32
x_image = tf.transpose(x_image,perm=[0,2,3,1])
# y_ = tf.layers.dense(flatten,10)
y_ = res_net(x_image, [2,3,2],32,10)
# simplify with tensorflow api
# y_ = tf.layers.dense(hidden3,10)
loss = tf.losses.sparse_softmax_cross_entropy(labels=y,logits=y_)
# indices
predict = tf.argmax(y_,1)
# equal
correct_prediction = tf.equal(predict,y)
# [1,0,0,1,1,]
accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float64))
train_data = CifarData(train_filenames,True)
# test_data = CifarData(test_filenames,False)
batch_size = 20
train_steps = 1000
test_steps = 100
with tf.name_scope('train_op'):
# learning rate le-3
train_op = tf.train.AdamOptimizer(1e-3).minimize(loss)
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
for i in range(train_steps):
batch_data,batch_labels = train_data.next_batch(batch_size)
loss_val, accu_val,_ = sess.run([loss,accuracy,train_op],feed_dict={x: batch_data,y: batch_labels})
if (i+1) % 500 == 0:
print '[Train] Step: %d, loss: %4.5f, acc: %4.5f' % (i, loss_val, accu_val)
if (i+1) % 1000 == 0:
test_data = CifarData(test_filenames,False)
all_test_acc_val = []
for j in range(test_steps):
test_batch_data,test_batch_labels = test_data.next_batch(batch_size)
test_acc_val = sess.run([accuracy],
feed_dict={x: test_batch_data,y: test_batch_labels })
all_test_acc_val.append(test_acc_val)
test_acc = np.mean(all_test_acc_val)
print '[Test ] Step: %d, acc: %4.5f ' % (i+1,test_acc)