最近一直对测试覆盖率方面的内容比较感兴趣,虽然很多项目都早已经用上了Jacoco来实现测试覆盖率的统计,但是很少看到实际项目中基于覆盖率统计来指导测试的实践。这篇文章是我近期基于代码变更风险(CR)平台 (http://cr.qa.netease.com/)对猛犸大数据系统的后台调度组件Azakban的一个小版本的测试实践。
个人认为,代码覆盖率应该是对一个版本测试情况的一个重要考量。不能说代码覆盖率高,就是没有风险。但是,相反,我觉得如果代码覆盖率很低,那就是客观地存在较大风险,说明我们测试的充分度不够。CR平台,其实是基于jacoco覆盖率统计的结果之上,将提测版本与基准版本(通常是上一个线上稳定版本)的代码库进行比对,统计出一个版本提测后开发变更代码的覆盖情况。另外,借助了其他开源工具(ckjm、javancss等)展示了代码中类之间的相互调用关系以及复杂度信息等等。
下面是我在猛犸4.8.5版本中,借助CR平台对Azkaban相关需求的测试实践:
例子一:
1. 看需求和JIRA
开发写的需求:
“ 补数据优化,增强顺序性,优化实例生成数量:原来有的逻辑是Trigger每个一分钟触发一次,然后产生一个补数据实例到分发队列,分发队列每次分发前,先检查有没有正在运行的实例,如果没有就随机选择一个实例分发下去执行。如果有,重新放回队列。这个逻辑存在的问题是,会产生大量的实例在分发队列,耗费内存和CPU时间。现在做的优化是:Trigger每次触发前,先检查分发队列以及已经分发下去的实例里边是否有相关的补数据实例。如果有,则跳过这次触发。另外可以通过
az.backfill.concurrent.num 指定补数据实例产生的并发度(范围1~100,缺失默认值 1)。”
看着可能有点晕,我稍微将它简化一下就是:
a. 补数据调度,原本可能会产生大量并发执行的实例,现在限制并发实例数只能是1。即:前一次实例执行完成后,后一次调度实例才会生成。
b. 提供参数, az.backfill.concurrent.num来控制允许的并发实例数量,该参数的范围是1-100。
至于JIRA,我这边就不重复添图了,大致跟需求内容差不多。
2. 查看Gitlab:
开发提交gitlab代码时与jira做了关联,点击链接可以直接跳转到gitlab:
可以看到该jira影响的类有两个,分别是:GlobleAttribute.java (只添加了一行常量定义)和 TriggerManager.java
3. 查看CR:
开始测试该功能前,先看一眼CR的覆盖情况(CR之前执行过自动化测试用例和其他手工测试用例):

可以看到,在表格里没有出现GlobleAttribute.java(不知是否是因为该类只添加了一行常量定义,改动太小的缘故),而TriggerManager.java类的改动部分覆盖率为63.6%。点进去再仔细看下新修改的行的覆盖情况:
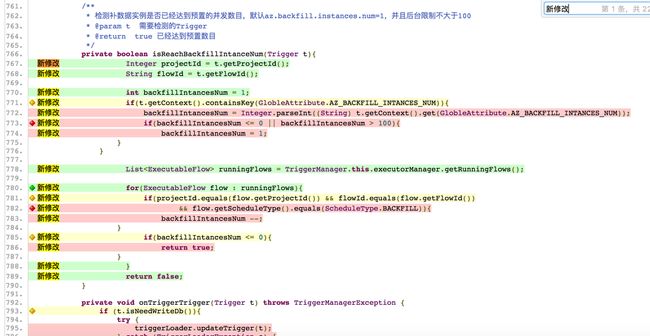
可以看到“新修改”的未覆盖部分(红色)主要是因为 if (t.getContext().containsKey(GlobleAttribute.AZ_BACKFILL_INSTANCES_NUM))判断没有命中,因为该需求引入了新的参数az.backfill.concurrent.num 指定补数据实例产生的并发度 。而该参数我们还并没有设置过。
此外,下面的未覆盖部分,
if 判断的后半段 flow.getScheduleType().equals(ScheduleType.BACKFILL)未命中的原因是因为我们还并没有执行过补数据的调度。
4. 执行手工测试
对一个作业流设置补数据调度100次,指定补数据实例产生的并发度为5(设置参数az.backfill.concurrent.num 的值为5),验证补数据调度按照既定场景正确执行。
5. 测试结果
查数据库显示,补数据调度按照顺序执行, 但是实例个数始终为1。
显然,该需求的基本功能生效了(从以前的并发实例数不受限,现在实例个数为1),但是并发度参数并没有生效。
6. 结果分析排查
重新执行覆盖率统计,再来看一眼CR平台的新的结果:

可以看到,覆盖率有一定的提升。但是为什么并发参数设置没有生效呢? 来看一眼服务器上的执行日志,拉到日志的最后,看到有一条频繁打印的日志:“backfill trigger 3959, .......”:

再对照一下CR平台上变更的代码:
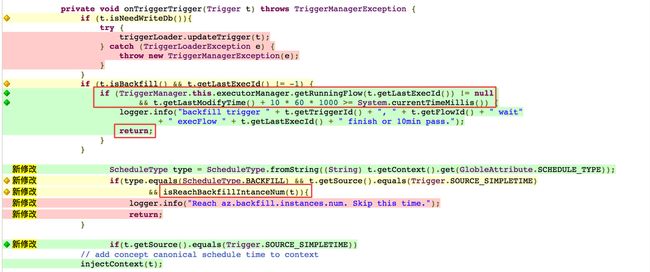
可以看到,下面这部分“新修改”的代码应该打印的日志还处于“未覆盖”的状态。往上看,发现红框中圈出的代码段里打印的日志刚好就是服务器上后台的日志。看一眼判断条件:
“判断该作业流是否已经有执行实例正在执行中,且该正在执行中的作业流实例的开始时间距离现在不到10分钟
” 。
这样就初步解释了 目前阶段为什么我们没看到“新修改”日志打印,以及实例没有生成的直接原因。即: 被之前的判断条件错误拦截了。
等待10分钟,我们继续查看数据库的结果,发现并发的实例数仍为1。 再看一眼CR的覆盖情况:

可以看到,刚才未覆盖的这段日志打印,在10分钟过去后被执行了。为了确认该数据的准确性,再看一眼日志,这次我们直接搜索“Reach az.backfill.instances.num ......”这条日志:

可以看到,日志确实出现了变化。也就是说,服务器执行的代码进入了判断: “到达了补数据实例个数的上限 isReachBackfillInstanceNum(t)” 。
然而,我们设置的上限明明是5,为什么却显示已经达到上限,而数据库里的实际并发数还是1呢?
再看一眼,变更代码中未覆盖的变更行:

可以发现,在isReachBackfillInstanceNum(t)方法中,刚好找到了我们想要的内容:默认的补数据实例个数backfillInstancesNum为1,当调度t的上下文信息context中包含参数GlobalAttribute.AZ_BACKFILL_INSTANCES_NUM时,就用该对应的值赋值给backfillInstancesNum。且会对该范围进行1-100的判断。
而这段代码正好没有被执行。
再次进入源码查看,发现了个惊人的事情:

这个AZ_BACKFILL_INSTANCES_NUM参数的实际key值,应该是az.backfill. instances.num,而开发兄弟在需求和jira中写的都是“az.backfill. concurrent.num”。
此时,我的心情是复杂的。此处需要省略1000字。
如你所知,后续修改参数key后,重新测试,成功测试通过。通过后的覆盖率统计情况:

唯一没有覆盖的行,是因为设置的并发参数的值是5,在该1-100范围内,所以没有进入该判断。
例子二:
篇幅有限,再来简单介绍另外个利用CR平台完善测试的例子。
需求:
将执行节点的流实例并发数量的值写进db,在节点服务启动时,优先从db中读取加载进内存。如果db中不包含,再从配置文件读取。
简单测试后, 看下CR平台的覆盖情况:
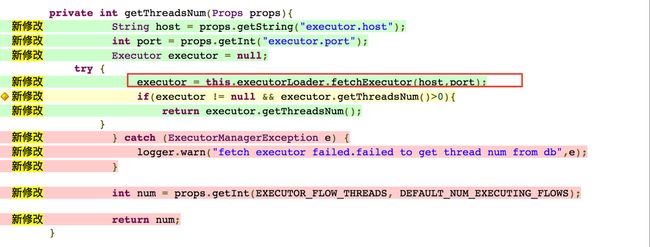
可以看到,对于基本的正常功能,我们还是覆盖到了。 但是仍有大部分语句没有覆盖,而这部分未覆盖的内容其实就是查询数据库时发生异常情况。
知道未覆盖的原因,就好办了,我们只要制造数据库查询异常就可以模拟该场景。
测试方式:
执行数据库语句alter table executors drop column threads_num; 将mysql中executor表的threads_num字段给删掉。然后重新启动executor。并确保executor可以正常工作。
再次执行覆盖率统计,查看CR平台的结果:
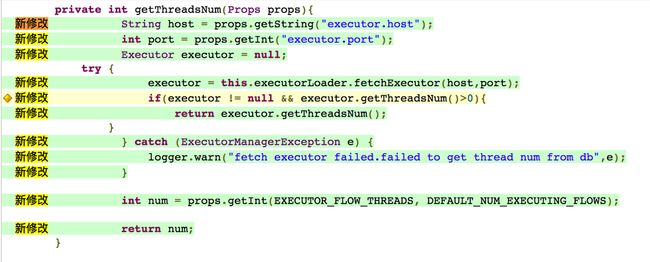
可以看到,这下“新修改”的代码全部覆盖了。可以妥妥地在jira上标上这功能测试通过。
总结
最近看了一些业界的测试方法,发现基于覆盖率统计的白盒测试的热度正在逐渐提升,包括腾讯、去哪儿等一些公司都有基于覆盖率统计指导测试的不少实践。包括分析代码增量覆盖率,分析每条用例对覆盖率的贡献来精简测试用例集、剔除无效用例,基于执行覆盖统计将每条用例与代码模块相对应等等。所幸,我们也有CR平台,基于CR平台,我们后续可以做的事情应该还有很多。