一. 论文解读
特征交互对许多预测任务有非常重要的作用,特别是对于稀疏数据。Factorization Machines (FMs) 是一种非常有效的二阶特征交互方法,但是其只是捕捉到了特征间的线性关系,对于特征间的非线性关系及真实数据的内在结构是无效的。Neural Factorization Machine (NFM) 结合了 FM 的二阶特征构建能力及神经网络的非线性特征构建能力。
1. NFM 的预测函数:
其中, 和 表征的是 FM 的线性部分, 主要表征 NFM 的特征交互部分。
2. 模型结构:
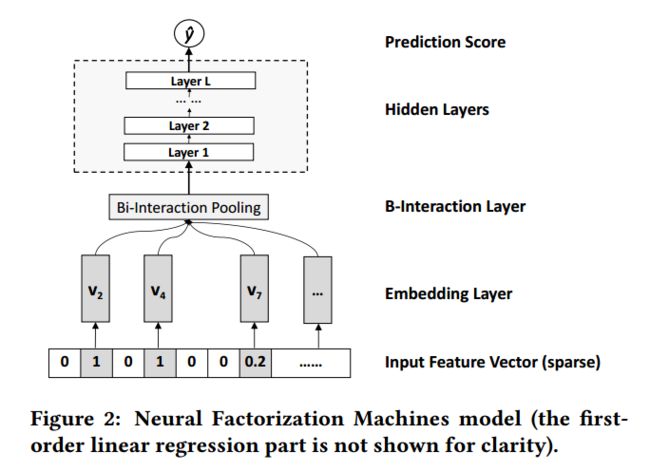
NFM.png
Bi-Interaction Layer 主要是对 embedding 后的 向量组做了一次池化操作转换成一个向量:
计算中其等价于:
对 Bi-Interaction Layer 的输出再传入 MLP 进行高阶特征组合。
完整的预测公式如下:
3. 损失函数:
论文中采用的 RMSE;当然对于分类问题,可以采用 logloss。
其公布的代码中定义为:
from sklearn.metrics import mean_squared_error
from sklearn.metrics import log_loss
RMSE = math.sqrt(mean_squared_error(y_true, predictions_bounded))
logloss = log_loss(y_true, y_pred)
二. 代码实现
1. 系统环境
- tensorflow 2.0
- python 3.6.8
2. 自定义 NFM layer.
class NFMLayer(tf.keras.layers.Layer):
"""
包含了 Embedding layer 和 Bi-interaction layer.
"""
def __init__(self, feature_size, field_size, embedding_size=32, l2_reg=0.01, **kwargs):
super().__init__(**kwargs)
self.feature_size = feature_size
self.field_size = field_size
self.embedding_size = embedding_size
self.l2_reg = l2_reg
self.embeddings = None
def build(self, input_shape):
self.embeddings = tf.keras.layers.Embedding(input_dim=self.feature_size,
output_dim=self.embedding_size,
embeddings_regularizer=tf.keras.regularizers.l2(self.l2_reg),
input_length=self.field_size)
def call(self, feature_ids, feature_vals):
# feature_ids = inputs['feature_ids'] # [batch_size, field_size]
# feature_vals = inputs['feature_vals'] # [batch_size, field_size]
feature_vals = tf.expand_dims(feature_vals, axis=-1) # [batch_size, field_size, 1]
feature_embeddings = self.embeddings(feature_ids) # [batch_size, field_size, embedding_size]
feature_embeddings = tf.multiply(feature_vals, feature_embeddings)
sum_square = tf.square(tf.reduce_sum(feature_embeddings, axis=1)) # [batch_size, embedding_size]
square_sum = tf.reduce_sum(tf.square(feature_embeddings), axis=1)
outputs = 0.5 * sum_square - square_sum
return outputs
3. model 部分
class NFM(tf.keras.Model):
def __init__(self, feature_size, field_size, embedding_size, hidden_units, activation='relu',
l2_reg=0.01, dropout_rate=0.5, use_bn=True, seed=1024, **kwargs):
super().__init__(**kwargs)
self.nfm_layer = NFMLayer(feature_size, field_size, embedding_size, l2_reg)
self.dnn_layer = DNN(hidden_units, activation, use_bn, dropout_rate, l2_reg, seed)
self.dense = tf.keras.layers.Dense(units=1, activation=None, use_bias=False)
self.fm = tf.keras.layers.Dense(units=1, activation=None, use_bias=True)
# @ tf.function(input_signature=[tf.TensorSpec(shape=(None, 196), dtype=tf.int32),
# tf.TensorSpec(shape=(None, 196), dtype=tf.float32)])
def call(self, feature_ids, feature_vals):
x = self.nfm_layer(feature_ids, feature_vals)
x = self.dnn_layer(x, training=None)
x = self.dense(x)
outputs = self.fm(feature_vals) + x
return outputs
【参考】
1 . https://arxiv.org/abs/1708.05027