Oracle sql查询语法详解
Oracle sql查询语法详解
一、查询数据
select
语法:
SELECT
column_1,
column_2,
...
FROM
table_name;select要求
-
首先,指定要从中查询数据的表名(必须有from子句)。
-
其次,指示要从中返回数据的列。如果您有多个列,则需要用逗号(,)分隔每个列。
查询单列
从customers表中获取名称
select name
from customers;
查询多列
dual
虚表
在Oracle中,SELECT语句必须有一个FROM子句。但是,某些查询不需要任何表格,例如:
SELECT
UPPER('love')
FROM
table)name为了符合语法要求,Oracle为您提供了DUAL一个表,该表是一个特殊的表,它是为快速访问而设计的。
除了调用内置函数之外,您还可以在SELECT访问DUAL表的查询子句中使用表达式:
SELECT
(10+ 3)/2
FROM
dual;
二、排序
语法:
SELECT
column_1,
column_2,
column_3,
...
FROM
table_name
ORDER BY
column_1 [ASC | DESC] [NULLS FIRST | NULLS LAST],
column_1 [ASC | DESC] [NULLS FIRST | NULLS LAST],
单列排序
顾客表根据名字升序排列
SELECT
name,
address,
credit_limit
FROM
customers
ORDER BY
name ;
多列排序
联系表根据first_name升序排列,根据last_name降序排列。
SELECT
first_name,
last_name
FROM
contacts
ORDER BY
first_name,
last_name DESC;
null值排序问题
查询position表根据 city state排序并观察结果
SELECT
country_id,
city,
state
FROM
locations
ORDER BY
state;
oracle允许描述null值与非null值在排序当中到底谁先出现。比如我们期望这个null优先
SELECT
country_id,
city,
state
FROM
locations
ORDER BY
state nulls first;大家可以猜想一下first有,那么?
根据列的位置排序
SELECT
name,
credit_limit
FROM
customers
ORDER BY
2 DESC,
1;注意这里的2代表了credit_limit, 1代表name
根据函数或者表达式排序
根据顾客表名字(转换为大写之后排序)
SELECT
customer_id,
name
FROM
customers
ORDER BY
UPPER( name );
三、去除重复数据
语法
-- 单列
SELECT DISTINCT
column_1
FROM
table;
-- 多列
SELECT
DISTINCT column_1,
column_2,
...
FROM
table_name;
单列去除重复
SELECT DISTINCT
first_name
FROM
contacts
ORDER BY
first_name;
多列去除重复
SELECT
DISTINCT product_id,
quantity
FROM
ORDER_ITEMS
ORDER BY
product_id;
去除重复关于null
DISTINCT将NULL值视为彼此重复。如果使用该SELECT DISTINCT语句从具有许多NULL值的列查询数据,则结果集将仅包含一个NULL值。
SELECT
DISTINCT state
FROM
locations;
四 、条件查询
语法
SELECT
column_1,
column_2,
...
FROM
table_name
WHERE
search_condition
ORDER BY
column_1,
column_2;
简单等值判断
SELECT
product_name,
description,
list_price,
category_id
FROM
products
WHERE
product_name = 'Kingston';
使用比较符号判断
除了相等运算符之外,Oracle还为您提供了下表中说明的许多其他比较运算符:
| *操作符 | 描述 |
|---|---|
| = | 平等 |
| !=,<> | 不等式 |
| > | 比...更棒 |
| < | 少于 |
| > = | 大于或等于 |
| <= | 小于或等于 |
| in | 等于值列表中的任何值 |
| any/some/all | 将值与列表或子查询进行比较。它必须在另一个运算符之后,例如=,>,<。 |
| not in | 不等于值列表中的任何值 |
| not between x and y | 相当于[Not]> = n and <= y。 |
| [not] exists | 如果子查询返回至少一行,则返回true |
| IS [NOT] null | NULL测试 |
比如
SELECT
product_name,
list_price
FROM
products
WHERE
list_price > 500;
多条件组合
使用 and or not
比如
SELECT
product_name,
list_price
FROM
products
WHERE
list_price > 500
AND category_id = 4;
五、别名
当你[从一个表中查询数据,Oracle使用的表的列名显示的列标题,有时候列明本身可能含义并不明确,需要使用一个别的名字表达更清晰点,就可以通过使用别名来完成。有时,你希望简化这些列明显示也可以这么做
别名可以使用在列名和表名上
列别名
比如
SELECT
first_name AS fname,
last_name AS lname
FROM
employees;as 关键字可以省略。此外如果列名别名要包含空格,则别名必须使用""引起来,否则无法通过。
比如
SELECT
first_name "First Name",
last_name "Family Name"
FROM
employees;
表别名
语法
table_name AS table_alias
table_name table_alias
在不使用表别名的情况下列的限定如下
table_name.column_name
但是,在为表分配表别名后,必须使用别名而不是表名:
table_alias.column_name
六、抓取
mysql和postgresql具有LIMIT允许您检索查询生成的行的一部分的子句。但是oracle并没有limit子句,在12c之前, 可以通过子查询的方式完成这种部分提取功能,这也就是我们的分页sql
。自12c发布以来,它提供了一个类似但更灵活的子句,称为行限制子句。
需求:取库存级别最高的前5个产品
这里需要使用到两个表
-
inventories 库存
-
products
指定多少行
SELECT
product_name,
quantity
FROM
inventories
INNER JOIN products
USING(product_id)
ORDER BY
quantity DESC
FETCH NEXT 5 ROWS ONLY;fetch子句的语法
[ OFFSET offset ROWS]
FETCH NEXT [ row_count | percent PERCENT ] ROWS [ ONLY | WITH TIES ]
指定起始行
所以加入,我要6到10 的数据
SELECT
product_name,
quantity
FROM
inventories
INNER JOIN products
USING(product_id)
ORDER BY
quantity DESC
offset 6 rows
FETCH NEXT 5 ROWS ONLY;
使用百分比
SELECT
product_name,
quantity
FROM
inventories
INNER JOIN products
USING(product_id)
ORDER BY
quantity DESC
FETCH NEXT 5 percent rows ONLY;详情参考:https://docs.oracle.com/database/121/SQLRF/statements_10002.htm#SQLRF01702
https://docs.oracle.com/database/121/SQLRF/statements_10002.htm#BABEAACC
七、模糊查询
语法
expresion [NOT] LIKE pattern [ ESCAPE escape_characters ]
expression:
这expression是一个列名或要对其进行测试的表达式pattern。
pattern:
是一个要搜索的字符串expression。该pattern包括以下通配符:
-
%(百分比)匹配零个或多个字符的任何字符串。
-
_(下划线)匹配任何单个字符。
escape_character:
是出现在通配符的前面指定通配符不应该被解释为一个通配符
通配符%使用
SELECT
first_name,
last_name,
phone
FROM
contacts
WHERE
last_name LIKE 'St%'
ORDER BY
last_name;
通配符_使用
SELECT
first_name,
last_name,
email,
phone
FROM
contacts
WHERE
first_name LIKE 'Je_i'
ORDER BY
first_name;escape使用
SELECT
product_id,
discount_message
FROM
discounts
WHERE
discount_message LIKE '%25!%%' ESCAPE '!';这里25后面的第一个%期望他就是一个%不要再解释为通配符,这个时候就要无视通配的含义
一、连接查询
-
内链接
-
外连接
-
左外连接
-
右外连接
-
-
自连接
1 内连接
inner join
销售订单数据主要存储在两个表orders和order_items表中,二者通过order_id进行关联
语法
SELECT
*
FROM
T1
INNER JOIN T2 ON join_predicate;
解释
-
form后面跟主表
-
Inner join 后面跟连接表
-
连接谓词指定连接条件
SELECT
*
FROM
orders
INNER JOIN order_items ON
order_items.order_id = orders.order_id
ORDER BY
order_date DESC;
除了可以使用on子句之外,还可以使用using,USING子句中列出的列 必须在表T1和T2表中都可用
SELECT
*
FROM
orders
INNER JOIN order_items USING( order_id )
ORDER BY
order_date DESC;
如果更多的表,使用方式也是一样的,但是要注意连接表的数量,否则很容易让性能成为瓶颈。
2 左外连接
语法
SELECT
column_list
FROM
T1
LEFT JOIN T2 ON
join_predicate;
T1是左表并且T2是右表。
该查询将T1表中的每一行与表中的行进行比较T2。
如果来自两个T1和T2表的一对行满足连接谓词,则查询将两个表中的行的列值组合在一起,并在结果集中包含此行。
如果T1表中的行在表中没有任何匹配的行T2,则查询将表中行的列值T1与SELECT子句中出现的右表中每列的NULL值组合在一起。
观察
orders和employees表:
该orders表存储销售订单表头数据。它具有salesman_id引用表中employee_id列的列employees。
该salesman_id列无效,这意味着并非所有订单都有销售员工负责订单。
SELECT
order_id,
status,
first_name,
last_name
FROM
orders
LEFT JOIN employees ON employee_id = salesman_id
ORDER BY
order_date DESC;连接查询均可以使用using来描述关联条件。
思考
ONvs WHERE子句中的条件
SELECT
order_id,
status,
employee_id,
last_name
FROM
orders
LEFT JOIN employees ON
employee_id = salesman_id
WHERE
order_id = 58;
SELECT
order_id,
status,
employee_id,
last_name
FROM
orders
LEFT JOIN employees ON
employee_id = salesman_id
AND order_id = 58;二者一样吗?
3 右连接
右外连接返回右表中的所有行以及左表中的匹配行。与左连接相反,
SELECT
name,
order_id,
status
FROM
orders
RIGHT JOIN customers
USING(customer_id)
ORDER BY
name;这个不赘述了。
4 自连接
自联接是一种将表连接到自身的连接。
语法
SELECT
column_list
FROM
T t1
INNER JOIN T t2 ON
join_predicate;
eg
SELECT
(e.first_name || ' ' || e.last_name) employee,
(m.first_name || ' ' || m.last_name) manager,
e.job_title
FROM
employees e
LEFT JOIN employees m ON
m.employee_id = e.manager_id
ORDER BY
manager;
二、笛卡儿积
select
from t1 ,t2
crosss join在数学,给定两个组 A和B,的笛卡尔乘积 A x B是该组的所有有序对(A,B),其中a属于A与b属于B。
偶尔使用。当希望某些表里面的数据和另外一个表里面的数据一一合并以显示的时候可以使用。
三、分组
GROUP BY子句在SELECT语句中用于按行或表达式的值将行分组为一组摘要行。该GROUP BY子句每组返回一行。
该GROUP BY子句通常与使用的 聚合函数如AVG(),COUNT(),MAX(),MIN()和SUM()。在这种情况下,聚合函数返回每个组的摘要信息。例如,给定几个类别的产品组,该AVG()函数返回每个类别中产品的平均价格。
语法
SELECT
column_list
FROM
T
GROUP BY
c1,
c2,
c3;
该GROUP BY条款出现在该FROM 之后。如果出现caseWHERE子句,则该GROUP BY子句必须放在该WHERE`子句之前。
select后面的列只能出现group by 后面的列以及聚合函数。
下面的语句使用GROUP BY条款,以找到独特的订单状态,从 该orders表:
SELECT
status
FROM
orders
GROUP BY
status;思考
请问还有其它办法吗?
如果要得到客户的订单数量:
SELECT
customer_id,
COUNT( order_id )
FROM
orders
GROUP BY
customer_id
ORDER BY
customer_id;
rollup
下面的语句计算销售额,并通过他们组customer_id,status和(customer_id,status):
SELECT
customer_id,
status,
SUM( quantity * unit_price ) sales
FROM
orders
INNER JOIN order_items
USING(order_id)
GROUP BY
ROLLUP(
customer_id,
status
);
四、having
HAVING子句是SELECT声明的可选子句。它用于过滤 group by 子句返回的行组。这就是该HAVING 与该GROUP BY 一起使用的原因。
语法
SELECT
column_list
FROM
T
GROUP BY
c1
HAVING
group_condition;
eg
从order_items表中检索订单及其值
SELECT
order_id,
SUM( unit_price * quantity ) order_value
FROM
order_items
GROUP BY
order_id
ORDER BY
order_value DESC;
要查找值大于1百万的订单,请HAVING按如下方式添加子句
SELECT
order_id,
SUM( unit_price * quantity ) order_value
FROM
order_items
GROUP BY
order_id
HAVING
SUM( unit_price * quantity ) > 1000000
ORDER BY
order_value DESC;
having后面的条件也可以是复杂条件
查找值大于500,000且每个订单中的产品数量在10到12之间的订单:
SELECT
order_id,
COUNT( item_id ) item_count,
SUM( unit_price * quantity ) total
FROM
order_items
GROUP BY
order_id
HAVING
SUM( unit_price * quantity ) > 500000 AND
COUNT( item_id ) BETWEEN 10 AND 12
ORDER BY
total DESC,
item_count DESC;
五、联合查询
一组操作相结合的结果集
语法
SELECT
column_list_1
FROM
T1
UNION
SELECT
column_list_1
FROM
T2;默认情况下,UNION运算符返回两个结果集中的唯一行。如果要保留重复的行,请明确使用UNION ALL 如下:
SELECT
column_list
FROM
T1
UNION ALL
SELECT
column_list
FROM
T2;
union查询
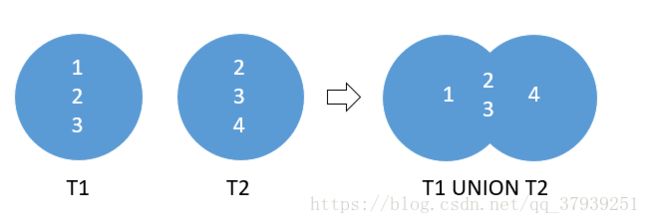
union all
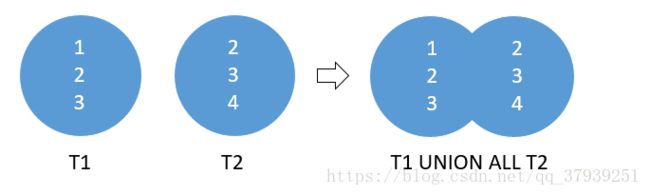
假设您必须从两个表employees和contacts表中发送电子邮件到电子邮件地址 。要实现此目的,首先,您需要撰写员工和联系人的电子邮件地址列表。然后将电子邮件发送到列表
SELECT
first_name,
last_name,
email,
'contact'
FROM
contacts
UNION SELECT
first_name,
last_name,
email,
'employee'
FROM
employees;
返回员工和联系人的唯一姓氏:
SELECT
last_name
FROM
employees
UNION SELECT
last_name
FROM
contacts
ORDER BY
last_name;
如果您在查询中使用UNION ALL而不是UNION如下:
SELECT
last_name
FROM
employees
UNION ALL SELECT
last_name
FROM
contacts
ORDER BY
last_name;
观察和上面的结果有何区别?
思考?
1 UNION vs. JOIN
UNION将结果集放在另一个上面,这意味着它会垂直附加结果集。但是,水平连接如结果集inner join 或LEFT JOIN组合结果集。


六、交集查询
INTERSECT运算符比较两个 查询的结果
SELECT
column_list_1
FROM
T1
INTERSECT
SELECT
column_list_2
FROM
T2;
使用运算符时必须遵循以下规则INTERSECT:
-
两个查询中列的数量和顺序必须相同。
-
相应列的 数据类型必须位于相同的数据类型组中,例如数字或字符。
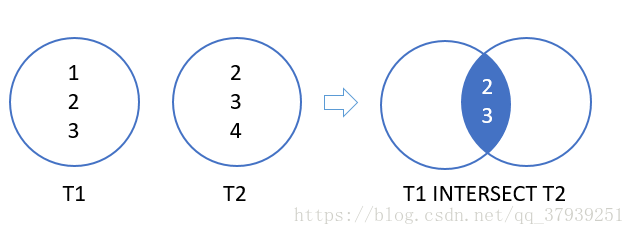
假设我们有两个返回T1和T2结果集的查询。
-
T1结果集包括1,2,3。
-
T2结果集包括2,3,4。
T1和T2结果的交叉返回2和3.因为这些是两个查询输出的可以相同的值
七、差集查询
Oracle MINUS运算符比较两个查询并返回第一个查询中不是由第二个查询输出的不同行。换句话说,运算符从另一个结果集中减去一个结果集。
语法
SELECT
column_list_1
FROM
T1
MINUS
SELECT
column_list_2
FROM
T2;
查询必须遵守下列规则相符:
-
列数及其顺序必须匹配。
-
相应列的数据必须位于相同的数据类型组中,例如数字或字符。
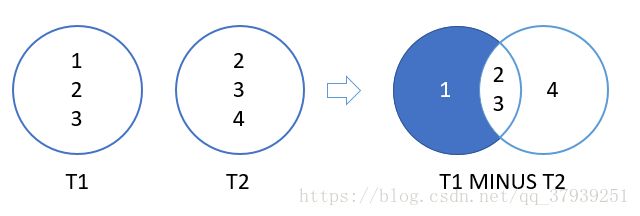
观察contacts和employees表
从contact中找出哪些不存在于employees中 的last_name
SELECT
last_name
FROM
contacts
MINUS
SELECT
last_name
FROM
employees
ORDER BY
last_name;
八、子查询
子查询是一个SELECT嵌套在另一语句内诸如语句SELECT,INSERT,UPDATE,或DELETE。通常,您可以在使用表达式的任何位置使用子查询。
以下查询使用该MAX()函数从products表中返回最高的定价:
SELECT
MAX( list_price )
FROM
products;要选择最昂贵产品的详细信息
SELECT
product_id,
product_name,
list_price
FROM
products
WHERE
list_price = 8867.99;
-- 这个数字通过上面的查询得到
分别执行两个查询以获取最昂贵的产品信息。通过使用子查询,我们可以将第一个查询嵌套在第二个查询中,如以下查询所示
SELECT
product_id,
product_name,
list_price
FROM
products
WHERE
list_price = (
SELECT
MAX( list_price )
FROM
products
);
请注意,子查询必须出现在括号内。
Oracle通过两个步骤评估上面的整个查询:
-
首先,执行子查询。
-
其次,在外部查询中使用子查询的结果。
嵌套在语句FROM子句中的子查询SELECT称为 内联视图。请注意,其他RDBMS(如MySQL和PostgreSQL)使用术语派生表而不是内联视图。
嵌套在语句WHERE子句中的子查询SELECT称为 嵌套子查询。
Oracle子查询的优点
这些是子查询的主要优点:
-
提供另一种查询需要复杂连接和联合数据的方法。
-
使复杂查询更具可读性。
-
允许以可以隔离每个部分的方式构造复杂查询。
1 select子查询
根据类别返回产品名称,清单价格和产品的平均清单价格:
SELECT
product_name,
list_price,
ROUND(
(
SELECT
AVG( list_price )
FROM
products p1
WHERE
p1. category_id = p2.category_id
),
2
) avg_list_price
FROM
products p2
ORDER BY
product_name;在此示例中,我们在SELECT子句中使用子查询来获取平均产品的定价。Oracle评估外部查询选择的每一行的子查询。
此子查询称为相关子查询,后面展开。
2 FROM子句示例中的Oracle子查询
语句FROM子句中的子查询SELECT称为内联视图,其语法如下:
SELECT
*
FROM
(subquery) [AS] inline_view;例如,以下语句返回具有最高值的前10个订单:
SELECT
order_id,
order_value
FROM
(
SELECT
order_id,
SUM( quantity * unit_price ) order_value
FROM
order_items
GROUP BY
order_id
ORDER BY
order_value DESC
)
WHERE
rownum
执行逻辑
-
首先,子查询返回的列表
order_id,并order_value通过排序order_value降序排列。 -
然后,外部查询从列表顶部检索前10行。
3 带有比较运算符的Oracle子查询示例
使用比较运算符e..g,>,> =,<,<=,<>,=的子查询通常包含聚合函数,因为聚合函数返回一个可用于WHERE在外部子句中进行比较的值查询。
例如,以下查询查找列表价格高于平均清单价格的产品。
SELECT
product_id,
product_name,
list_price
FROM
products
WHERE
list_price > (
SELECT
AVG( list_price )
FROM
products
)
ORDER BY
product_name;执行流程
-
首先,子查询返回所有产品的平均定价。
-
其次,外部查询获取其列表价格大于子查询返回的平均列表价格的产品。
4 Oracle子查询与IN和NOT IN运算符
使用IN 运算符的子查询 通常返回零个或多个值的列表。子查询返回结果集后,外部查询将使用它们
例如,以下查询查找2017年销售额超过100K的销售人员:
SELECT
employee_id,
first_name,
last_name
FROM
employees
WHERE
employee_id IN(
SELECT
salesman_id
FROM
orders
INNER JOIN order_items
USING(order_id)
WHERE
status = 'Shipped'
GROUP BY
salesman_id,
EXTRACT(
YEAR
FROM
order_date
)
HAVING
SUM( quantity * unit_price ) >= 1000000
AND EXTRACT(
YEAR
FROM
order_date) = 2017
AND salesman_id IS NOT NULL
)
ORDER BY
first_name,
last_name;
执行逻辑
-
首先,子查询返回销售额大于或等于100万的销售人员列表。
-
其次,外部查询使用salesman id列表来查询
employees表中的数据。
再例如
查找尚未在2017年下订单的所有客户:
SELECT
name
FROM
customers
WHERE
customer_id NOT IN(
SELECT
customer_id
FROM
orders
WHERE
EXTRACT(
YEAR
FROM
order_date) = 2017
)
ORDER BY
name;
执行逻辑
-
首先,子查询返回2017年下达一个或多个订单的客户ID列表。
-
其次,外部查询返回id不在子查询返回的列表中的客户。
5 相关子查询
看一个例子
SELECT
product_id,
product_name,
list_price
FROM
products
WHERE
list_price =(
SELECT
MIN( list_price )
FROM
products
);
首先,我们可以独立执行子查询
SELECT
MIN( list_price )
FROM
products;
其次,Oracle仅对子查询进行一次评估。
第三,在子查询返回结果集之后,外部查询使用它们。换句话说,外部查询取决于子查询。但是,子查询是隔离的,不依赖于外部查询的值。
与上面的子查询不同,相关子查询是使用外部查询中的值的子查询。此外,可以针对外部查询选择的每一行评估相关子查询一次。因此,使用相关子查询的查询可能会很慢。相关子查询也称为重复子查询或同步子查询。
接下来我们就来研究一下它。
1 WHERE子句示例中的Oracle相关子查询
查找其列表价格高于其类别的平均值的所有产品。
SELECT
product_id,
product_name,
list_price
FROM
products p
WHERE
list_price > (
SELECT
AVG( list_price )
FROM
products
WHERE
category_id = p.category_id
);在上面的查询中,外部查询是:
SELECT
product_id,
product_name,
list_price
FROM
products p
WHERE
list_price >
相关子查询是:
SELECT
AVG( list_price )
FROM
products
WHERE
category_id = p.category_id对于products表中的每个产品,Oracle必须执行相关子查询以按类别计算平均价格。
2 SELECT子句示例中的Oracle相关子查询
以下查询根据产品类别返回所有产品和平均标准成本:
SELECT
product_id,
product_name,
standard_cost,
ROUND(
(
SELECT
AVG( standard_cost )
FROM
products
WHERE
category_id = p.category_id
),
2
) avg_standard_cost
FROM
products p
ORDER BY
product_name;对于products表中的每个产品,Oracle执行相关子查询以计算产品类别的平均成本标准。
请注意,上面的查询使用该ROUND()函数将平均标准成本舍入为两位小数。
3 Oracle将子查询与EXISTS运算符示例相关联
我们通常使用与EXISTS运算符相关的子查询。例如,以下语句将返回所有没有订单的客户:
SELECT
customer_id,
name
FROM
customers
WHERE
NOT EXISTS (
SELECT
*
FROM
orders
WHERE
orders.customer_id = customers.customer_id
)
ORDER BY
name;
九、exists vs in
Oracle EXISTS运算符是一个返回true或false的布尔运算符。的EXISTS操作者通常与用于 子查询,以测试行是否存在:
EXISTS如果子查询返回任何行返回true,否则,返回false。此外,EXISTS一旦子查询返回第一行,操作符就会终止子查询的处理。
EXISTS一旦子查询返回第一行,就会停止扫描行,因为它可以确定结果,而IN操作员必须扫描子查询返回的所有行以结束结果。
此外,该IN子句不能将任何NULL 值与值进行比较,但该EXISTS子句可以将所有内容与NULL值进行比较。例如,第一个语句不返回任何行,而第二个语句返回表中的所有行customers:
SELECT
*
FROM
customers
WHERE
customer_id IN(NULL);
SELECT
*
FROM
customers
WHERE
EXISTS (
SELECT
NULL
FROM
dual
);
通常,当子查询的结果集很大时,EXISTS运算符比IN运算符更快。相反,当子查询的结果集较小时,IN运算符比EXISTS运算符更快。
持续完善中ow