nlp分享
NLP 分享:
Section 1:
本节主要内容:
- 1.中文分词技术原理解析
- 2.机器学习与神经网络模型基础概念
- 3.关键字提取
- 4.词向量解析
本节期望:
- 能使用jieba做基础的中文分词与常用算法进行关键字提取
- 能使用word2vec训练得到基础的模型与词向量
NLP是啥?
zh-wiki: 自然語言處理(英语:Natural Language Processing,缩写作 NLP)是人工智慧和語言學領域的分支學科
中文分词技术原理解析:
- 1.基于字符串匹配的分词方法
- 2.基于理解的分词方法
- 3.基于统计的分词方法
1.基于字符串匹配的分词方法:
基于字符串匹配的分词方法又称机械分词方法,它是按照一定的策略将待分析的汉字串与一个“充分大的”机器词典中的词条进行配,若在词典中找到某个字符串,则匹配成功
2.基于理解的分词方法:
通过让计算机模拟人对句子的理解,达到识别词的效果。其基本思想就是在分词的同时进行句法、语义分析,利用句法信息和语义信息来处理歧义现象。它通常包括三个部分:分词子系统、句法语义子系统、总控部分。在总控部分的协调下,分词子系统可以获得有关词、句子等的句法和语义信息来对分词歧义进行判断,即它模拟了人对句子的理解过程。这种分词方法需要使用大量的语言知识和信息。由于汉语语言知识的笼统、复杂性,难以将各种语言信息组织成机器可直接读取的形式,因此目前基于理解的分词系统还处在试验阶段。
3.基于统计的分词方法
基于统计的分词方法是在给定大量已经分词的文本的前提下,利用统计机器学习模型学习词语切分的规律(称为训练),从而实现对未知文本的切分。例如最大概率分词方法和最大熵分词方法等。随着大规模语料库的建立,统计机器学习方法的研究和发展,基于统计的中文分词方法渐渐成为了主流方法
主要的统计模型有:N元文法模型(N-gram),隐马尔可夫模型(Hidden Markov Model ,HMM),最大熵模型(ME),条件随机场模型(Conditional Random Fields,CRF)等。
1.马尔科夫模型
- 不知道哪个老大的总结:今天的事情只取决于昨天,而明天的事情只取决于今天,与历史毫无关联
随机过程中各个状态 S t S_t St的概率分布,只与它的前一个状态 S t − 1 S_{t-1} St−1有关,即 P ( S t ∣ S 1 , S 2 , S 3 , ⋯ , S t − 1 ) = P ( S t ∣ S t − 1 ) P_(S_t|S_1,S_2,S_3,\cdots,S_{t-1}) = P(S_t|S_{t-1}) P(St∣S1,S2,S3,⋯,St−1)=P(St∣St−1)
公式:
马尔科夫过程:
p ( q t = s j ∣ q t − 1 = s i , q t − 2 = s k , ⋯ ) ≈ p ( q t = s j ∣ q t − 1 = s i ) p_(q_t = s_j|q_{t-1}=s_i,q_{t-2}=s_k,\cdots)\approx p_({q_t=s_j|q_{t-1}=s_i}) p(qt=sj∣qt−1=si,qt−2=sk,⋯)≈p(qt=sj∣qt−1=si)
马尔科夫模型:
( q t = s j ∣ q t − 1 = s i ) = a i j , 1 ≤ i , j ≤ N _({q_t=s_j|q_{t-1}=s_i}) = a_{ij} \quad,\quad 1\leq i,j\leq N (qt=sj∣qt−1=si)=aij,1≤i,j≤N
a i j ≥ 0 a_{ij} \geq 0 aij≥0
∑ i = 0 N a i j = 1 \sum_{i=0}^N a_{ij} =1 i=0∑Naij=1
)
重要性质:
- 马尔科夫链模型的状态转移矩阵收敛到的稳定概率分布于我们的初始状态概率分布无关
- 非周期性
- 任何两个状态是连通的: 从任意一个状态可以通过有限步到达其他的任意一个状态,不会出现条件概率为0不可达的情况
- 状态数是可以是有限的,也可以是无限的。因此可以用于连续概率分布和离散型概率分布

2.隐马尔科夫模型(Hidden Markov Model,HMM)
####它用来描述一个含有隐含未知参数的马尔可夫过程。其难点是从可观察的参数中确定该过程的隐含参数。
- 维基百科上的例子——通过朋友的行为去预测当地天气的变化


算法结果:
根据状态序列得到分词结果
算法过程:
- 输入:
模 型 λ = ( A , B , π ) 和 观 察 序 列 O = ( O 1 , O 2 , ⋯ , O T ) 模型 \lambda = (A,B,\pi) 和观察序列 O =(O_1,O_2,\cdots,O_T) 模型λ=(A,B,π)和观察序列O=(O1,O2,⋯,OT) - 输出:
最 优 路 径 : I ∗ = ( i 1 , i 2 , ⋯ , i t ) 最优路径:I^*=(i_1,i_2,\cdots,i_t) 最优路径:I∗=(i1,i2,⋯,it)
####n元模型算法 (n-gram)
-
语言模型联合概率:
p ( W ) = p ( w 1 T ) = p ( w 1 , w 2 , ⋯ , w T ) p(W) = p(w^T_1)=p(w_1,w_2,\cdots,w_T) p(W)=p(w1T)=p(w1,w2,⋯,wT) -
Bayes公式链式分解:
p ( w 1 T ) = p ( w 1 ) ⋅ ( w 2 ∣ w 1 ) ⋯ p ( w T ∣ w 1 T − 1 ) p(w^T_1)=p(w_1)\cdotp(w_2|w_1)\cdots p(w_T|w^{T-1}_1) p(w1T)=p(w1)⋅(w2∣w1)⋯p(wT∣w1T−1) -
当n=1:(unigram model)
p ( w 1 , w 2 , ⋯ , w m ) = p ( w 1 ) p ( w 2 ) ⋯ p ( w m ) p(w_1,w_2,\cdots,w_m) = p(w_1)p(w_2)\cdots p(w_m) p(w1,w2,⋯,wm)=p(w1)p(w2)⋯p(wm)
句子的概率等于每个词的概率的乘积,即每个词之间都是相互独立的
-
当n=2:(bigram model)
p ( w i ∣ w 1 , w 2 , ⋯ , w i − 1 ) = p ( w i ∣ w i − 1 ) p(w_i|w_1,w_2,\cdots,w_i-1) = p(w_i|w_{i-1}) p(wi∣w1,w2,⋯,wi−1)=p(wi∣wi−1) -
当n=3:(trigram model)
p ( w i ∣ w 1 , w 2 , ⋯ , w i − 1 ) = p ( w i ∣ w i − 2 , w i − 1 ) p(w_i|w_1,w_2,\cdots,w_i-1) = p(w_i|w_{i-2},w_{i-1}) p(wi∣w1,w2,⋯,wi−1)=p(wi∣wi−2,wi−1) -
当 n → + ∞ n\rightarrow+\infty n→+∞
P ( w i ∣ w i − ( n − 1 ) , ⋯ , w i − 1 ) = p ( w i ∣ w i − ( n − 1 ) , ⋯ , w i − 1 , w i ) = c o u n t ( w i − ( n − 1 ) , ⋯ , w i − 1 , w i ) c o u n t ( w i − ( n − 1 ) , ⋯ , w i − 1 ) P(w_i | w_{i-(n-1)},\cdots,w_{i-1})= p(wi|w_{i-(n-1)},\cdots,w_{i-1},w_i) = \frac{count(w_{i-(n-1)},\cdots,w_{i-1},w_i)}{count(w_{i-(n-1)},\cdots,w_{i-1})} P(wi∣wi−(n−1),⋯,wi−1)=p(wi∣wi−(n−1),⋯,wi−1,wi)=count(wi−(n−1),⋯,wi−1)count(wi−(n−1),⋯,wi−1,wi)
-
齐次马尔科夫假设:
p ( w k ∣ w 1 k ) ≈ p ( w k ∣ w k − n + 1 k − 1 ) p(w_k|w^k_1)\approx p(w_k|w^{k-1}_{k-n+1}) p(wk∣w1k)≈p(wk∣wk−n+1k−1)每个输出仅仅与上一个输出有关
#3.jieba分词:
github: https://github.com/fxsjy/jieba
算法
- 基于前缀词典实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图 (DAG)
- 采用了动态规划查找最大概率路径, 找出基于词频的最大切分组合
- 对于未登录词,采用了基于汉字成词能力的 HMM 模型,使用了 Viterbi 算法
机器学习与神经网络模型基础:
机器学习基本概念:
必要元素:
- 1.数据
- 2.转换数据的模型
- 3.衡量模型好坏的损失函数
- 4.调整模型权重以便最小化损失函数的算法
机器学习分类:
- 1.监督学习
- 2.无监督学习:
区别:数据集是否有人工分类标签
神经网络模型基础概念:
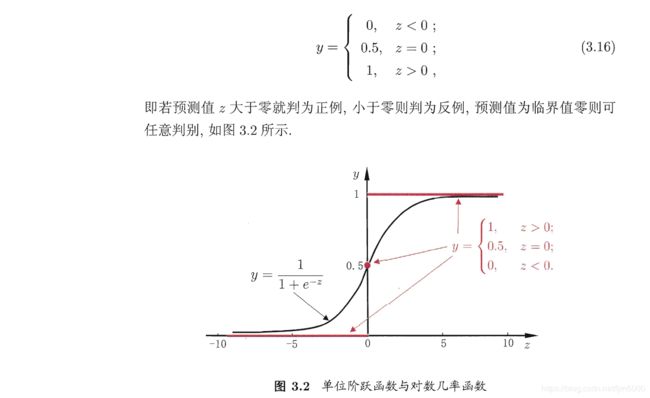
- 1.激活函数:
- 2.损失函数(代价函数) :
- 3.反向传播:
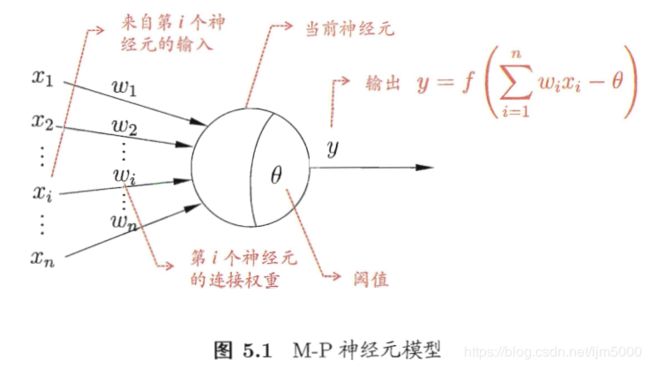
###激活函数: 跃阶函数 与 Sigmoid函数
###神经网络发展史

神经网络类型
https://36kr.com/p/5115489.html
27种神经网络

-
泛化(generalization) : 机器学习模型学习到的概念在它处于学习的过程中时模型没有遇见过的样本时候的表现, 好的机器学习模型的模板目标是从问题领域内的训练数据到任意的数据上泛化性能良好。 在机器学习领域中, 当我们讨论一个机器学习模型学习和泛化的好坏时, 我们通常使用术语: 过拟合和欠拟合。
-
过拟合(over-fitted) : 过拟合指的是 referstoa 模型对于训练数据拟合程度过当的情况。当某个模型过度的学习训练数据中的细节和噪音, 以至于模型在新的数据上表现很差, 我们称过拟合发生了。 这意味着训练数据中的噪音或者随机波动也被当做概念被模型学习了。 而问题就在于这些概念不适用于新的数据, 从而导致模型泛化性能的变差。
-
欠拟合(under-fitted) : 欠拟合指的是模型在训练和预测时表现都不好的情况。 一个欠拟合的机器学习模型不是一个良好的模型并且由于在训练数据上表现不好这是显然的。
关键字提取:
#常用算法:
- TF/IDF算法: (Term Frequency - Inverse Document Frequency)
- 基于统计学原理,统计词频数
- 表达式为:
t f ∗ i d f ( i , j ) = t f i j ∗ i d f i = n i j ∑ k n k j ∗ l o g ( ∣ D ∣ 1 + ∣ D i ∣ ) tf*idf(i,j) = tf_{ij} * idf_i = \frac{n_{ij}}{\sum_k{n_{kj}}} * log\left (\frac{|D|}{1+|D_i|}\right) tf∗idf(i,j)=tfij∗idfi=∑knkjnij∗log(1+∣Di∣∣D∣)
- 表达式为:
- 基于统计学原理,统计词频数
为啥要取对数和相乘?答先辈在实验室得出来的结论,不接受反驳!!!!!
-
TextRank(源于PageRank算法)
-
基本思想是:
- 连接数量,一个网页被越多的其他网页连接,说明这个网页越重要
- 连接质量,一个网页被越高权值的网页连接,说明这个网页越重要
-
表达式为:
W S ( V i ) = ( 1 − d ) + d ∗ ∑ j ( 1 ∣ O u t ( V j ∈ I n ( V j ) ) ∣ ∗ W S ( V j ) ) WS(V_i) = (1-d) + d * \sum_{j}\left(\frac{1}{|Out(V_j\in In(V_j))|}*WS(V_j)\right) WS(Vi)=(1−d)+d∗j∑(∣Out(Vj∈In(Vj))∣1∗WS(Vj))
-
-
LSA/LSI 算法:
- LSA 主要采用 SVD(奇异值分解) 【Latent Semanitc Analysis,潜在语义分析】
- LSI 主要采用 贝叶斯学派的方法对分布信息进行拟合[I for index,潜在语以索引]
-
LDA算法:
- 根据此的共现信息的分析,拟合出词-文档-主题的分布,进而将词,文本都映射到一个予以上面
实验代码:KeywordExtract.py
词表示:
- one-hot表示法:
- 词嵌入
// One-hot Representation 向量的维度是词表的大小,比如有10w个词,该向量的维度就是10w
v('足球') = [0 1 0 0 0 0 0 ......]
v('篮球') = [0 0 0 0 0 1 0 ......]
// Distributed Representation 向量的维度是某个具体的值如50
v('足球') = [0.26 0.49 -0.54 -0.08 0.16 0.76 0.33 ......]
v('篮球') = [0.31 0.54 -0.48 -0.01 0.28 0.94 0.38 ......]
word2vec基本介绍:
###Word2Vec就是把单词转换成向量。它本质上是一种单词聚类的方法,是实现单词语义推测、句子情感分析等目的一种手段。
算法核心

word2vec = CBOW + Skip-Gram
#CBOW (Continue bags of word)
CBOW(Continuous Bag-of-Words Model)是一种根据上下文的词语预测当前词语的出现概率的模型,其图示如上图左。CBOW是已知上下文,估算当前词语的语言模型;
#skip-Gram
而Skip-gram只是逆转了CBOW的因果关系而已,即已知当前词语,预测上下文,其图示如上图右;

#####实验过程:
- 1.数据集 中文维基百科数据集
- 2.分词,jieba
- 3.模型训练,gensim
######code:w2v.py
//通过一系列复杂的运算以后结果为:
res1:[('小孩', 0.8762074112892151), ('子女', 0.838797926902771),
('女儿', 0.8185409903526306), ('弟妹', 0.7953422665596008),
('兄弟姐妹', 0.7813134789466858), ('第二胎', 0.7718782424926758),
('妻子', 0.7622642517089844), ('女兒', 0.7622190713882446),
('私生女', 0.7616469264030457), ('女孩', 0.7608779668807983)]
res2:[('女人', 0.5232132077217102), ('王后', 0.4952596426010132),
('太后', 0.4879013001918793), ('妃子', 0.47403064370155334),
('王妃', 0.46553662419319153), ('皇太后', 0.45517897605895996),
('侍女', 0.45335230231285095), ('太子妃', 0.45140954852104187),
('王太后', 0.4455147683620453), ('太皇太后', 0.44461196660995483)]
res3: 西瓜
res4: 香蕉
参考链接:
- 中文分词概述:https://blog.csdn.net/flysky1991/article/details/73948971
- Word2Vec介绍:直观理解skip-gram模型 https://zhuanlan.zhihu.com/p/29305464
- 白话Word2Vec: https://www.jianshu.com/p/f58c08ae44a6
- word2vec学习小记: https://www.jianshu.com/p/418f27df3968
- https://www.leiphone.com/news/201705/vyn9xgep9uQLIf6d.html
- https://blog.csdn.net/Irving_zhang/article/details/69396923 3. https://zhuanlan.zhihu.com/p/26306795
- 激活函数解释: https://blog.csdn.net/qrlhl/article/details/60883604
- 偏置项:https://blog.csdn.net/xwd18280820053/article/details/70681750
- 正则化:https://blog.csdn.net/u012162613/article/details/44261657 7. 结巴分词:https://www.cnblogs.com/zhbzz2007/p/6092313.html