数据存储text转parquet及引发的OOM问题
1.数据转parquet的后效果
table1为textfile格式存储的表,分区20161122转换之前大小约400M,分别以parquet无压缩,parquet snappy压缩和parquet gzip压缩,转换到parquet格式的表table1_parquet的20161122,20161123,20161124三个分区。
Java代码
![]()
- (1)insert into table1_parquet partition (dt=20161122) select a,b,c from table1 where dt=20161122;
- (2)set parquet.compression=snappy;
- insert into table1_pa;rquet partition (dt=20161123) select a,b,c from table1 where dt=20161122
- (3)set parquet.compression=gzip;
- insert into table1_parquet partition (dt=20161124) select a,b,c from table1 where dt=20161122
转换结果:Sql代码
![]()
- (1) 416.2 M 1.2 G /table1_parquet/dt=20161122 -hive-e
- 查询:29s,28s,39s
- (2) 133.6 M 400.7 M /table1_parquet/dt=20161123 -hive-e "set parquet.compression=snappy"
- 查询:35s,28s,39s
- (3) 69.9 M 209.6 M /table1_parquet/dt=20161124 -hive-e "set parquet.compression=gzip"
- 查询:31s,35s,38s
(1)转parquet无压缩大小为400M,大小基本不变,
(2)转parquet并使用snappy压缩后,大小为133.6M
(3)转parquet并使用gzip压缩后,大小为69.9M,约压缩至原大小的85%
查询耗时基本不变。
参考理论:转parquet后空间节省约75%
列式存储和行式存储相比有哪些优势呢?
- 可以跳过不符合条件的数据,只读取需要的数据,降低IO数据量。(谓词下推)
- 压缩编码可以降低磁盘存储空间。由于同一列的数据类型是一样的,可以使用更高效的压缩编码(例如Run Length Encoding和Delta Encoding)进一步节约存储空间。
- 只读取需要的列,支持向量运算,能够获取更好的扫描性能。
注:曾发生转换之后数据量没下来的问题,结果发现为参数设置错误,设置成了impala的参数。
2.转化parquet后引起的OOM问题
问题:将表table1历史数据转成parquet表table_parquet(表按天分区,转换之前每个分区约10m数据,转换之后每个分区约1m数据),对近10天的数据做join操作,发生map side 内存溢出问题。
join操作:
Sql代码
![]()
- 当前时间:20161130
- 查询一:查询历史全量数据(查询正常)
- select count(*) from(
- select a.* from tmp.table1_parquet a
- left join
- (select * from tmp.table1_parquet where dt>=20160601) b
- on a.logtime=b.logtime and a.order_id=b.order_id and
- where a.dt>=20160601
- ) as t;
- 查询二:查询约近10天的数据(map side OOM)
- select count(*) from(
- select a.* from tmp.table1_parquet a
- left join
- (select * from tmp.table1_parquet where dt>=20161118) b
- on a.logtime=b.logtime and a.order_id=b.order_id and
- where a.dt>=20161118
- ) as t;
- 查询三:查询近5天的数据(查询正常)
- select count(*) from(
- select a.* from tmp.table1_parquet a
- left join
- (select * from tmp.table1_parquet where dt>=20161128) b
- on a.logtime=b.logtime and a.order_id=b.order_id and
- where a.dt>=20161128
- ) as t;
查询二的异常信息:
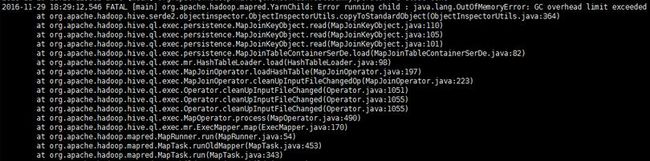
跟踪发现,hive默认小表小于20m会走map side join,结果查询二近十天的数据大小为10m(parquet,gzip压缩),hive默认走map side join,但由于10m数据为parquet gzip压缩格式,解压后大小约为100m,导致map side join溢出。
解决方案:
将参数hive.auto.convert.join.noconditionaltask.size的值由20m调整为5m,问题解决。
其中未找到hive.mapjoin.smalltable.filesize这个参数。
附一:与map side join相关的参数如下:
- hive.auto.convert.join : 是否自动转换为mapjoin
- hive.mapjoin.smalltable.filesize : 小表的最大文件大小,默认为25000000,即25M
- hive.auto.convert.join.noconditionaltask : 是否将多个mapjoin合并为一个
- hive.auto.convert.join.noconditionaltask.size : 多个mapjoin转换为1个时,所有小表的文件大小总和的最大值。
解释:hive.auto.convert.join.noconditionaltask.size表明可以转化为MapJoin的表的大小总合。例如有A、B两个表,他们的大小都小于该属性值,那么他们都会都会分别被转化为MapJoin,如果两个表大小总和加起来也小于该属性值,那么这两个表会被合并为一个MapJoin。
例如,一个大表顺序关联3个小表a(10M), b(8M),c(12M),如果hive.auto.convert.join.noconditionaltask.size的值:
1. 小于18M,则无法合并mapjoin,必须执行3个mapjoin;
2. 大于18M小于30M,则可以合并a和b表的mapjoin,所以只需要执行2个mapjoin;
3. 大于30M,则可以将3个mapjoin都合并为1个。
附二:谓词下推
谓词一般就是指where后面的那些过滤条件
映射下推[projectoin pushdown]和谓词下推[predicates pushdown]包括一个执行引擎,用来将映射和谓词推送到存储格式中以便于在底层尽可能来优化操作。结果就是提高了时间和空间上的效率,由于与查询无关的列都会被摒弃,并且不需要提供给执行引擎。
这对柱状存储无疑是非常有效的,因为 Pushdown 允许存储格式跳过整个与查询无关的列组,并且柱状存储格式操作起来也更加高效。
接下来我们将看看如果在 Hadoop 管道中使用 Pushdown。
在编码之前,你需要在 Hive 和 Pig 中启动对 Parquet 提供的开箱即用的投影/映射下推。在 MapReduce 程序中,有些手动操作你需要加入到 Driver 代码中来启动下推操作。从下面的高亮部分可以看到具体操作。
Hive --> Predicates [set hive.optimize.ppd = true; ]
Pig --> Projectoin [ 以后补充]