国产的数据库新增一员,华为携GaussDB入局
原文:http://www.enmotech.com/web/detail/1/724/1.html
导读:日前,华为公司在京面向全球发布了人工智能原生(AI-Native)数据库GaussDB和业界性能的分布式存储FusionStorage 8.0,将多年的AI技术和能力以及数据库经验融入到新品,实现很多创新性突破,比如人工智能技术融入分布式数据库的全生命周期、一套存储可同时支持块、文件、对象、HDFS协议等。
其中,最为标杆性的场景应用实属招商银行,在实践中:
华为GaussDB管理数据容量提升10倍,AZ内故障恢复速度提升30倍。以故障恢复为例,GaussDB的RTO时间小于1秒,而其他厂商则需要30秒;
FusionStorage 8.0在招行,部署渠道接入、开发测试、VDI以及大数据系统,一套存储替代原有4种存储设备,节省40%的TCO,业务上线速度提升9倍。其次,将人工智能技术融入存储全生命周期管理,从资源规划、业务发放、系统调优、风险预测和故障定位等方面实现智能运维管理,实现云上云下协同。再者,分布式存储性能业界第一,单节点性能高达16.8万每秒读写速度(IOPS)和1毫秒以内延时。基于ARM的算力,IOPS提升20%,基于AI Fabric网络,时延降低15%。招行和华为早在2017年就成立分布式数据库联合创新实验室,上面的情况无疑是最大的进展,也是金融机构对金融科技转型发力后的真实表现。
如果你想了解金融和科技如何更好地结合,知名金融机构招行的数据库选型和演进思路及对未来的判断,招行分布式数据库最佳实践、招行数据库架构的设计及发展方向、PostgreSQL开源数据库在平安的应用实践,以及金融行业PaaS云数据库平台的解决方案与实践,欢迎参加由招商银行和云和恩墨联合主办的2019数据技术嘉年华 · 金融峰会,6月28日让我们相约深圳,听金融科技的一线技术大佬们聊聊如何让科技助推金融业务创新。
报名地址:https://cs.enmotech.com/event/24
(余票不足50张,有意者尽快报名,以邮件门票为准)为了让大家了解华为新推出的产品,在官方新闻稿之外,笔者转载了资深媒体人老鱼的一篇文章,一窥华为如何在12年里,历经坎特,最终在被誉为基础软件“皇冠上明珠”的数据库领域中一举突围,破茧成蝶。
近期,美国下令封杀华为,不仅将华为列上“实体名单”,限制其在美贸易,还给华为的美国供应商下发禁令,要求中断与华为的各项合作,这在全球范围内掀起了滔天巨浪。
愤慨之余,我们不得不开始思考,当面临核心技术被卡脖子的时候,当中国成本优势在逐渐消失的今天,我们应该如何突围?
5月15日,华为在数据库领域投下了一颗重磅炸弹,引发了高度关注。华为常务董事、ICT战略与Marketing总裁汪涛在众多国内外媒体见证下,正式面向全球推出了GaussDB数据库。

历时9年的研发和打磨,低调谨慎的华为终于掀开了GaussDB数据库的神秘面纱,让之走到了台前。
华为做GaussDB的真正原因是什么?GaussDB是个怎样的数据库?又是怎样炼成的? 近日,GaussDB研发团队的多位骨干成员与笔者展开了深入的交流,介绍了GaussDB的来龙去脉,以及背后艰辛的研发故事。
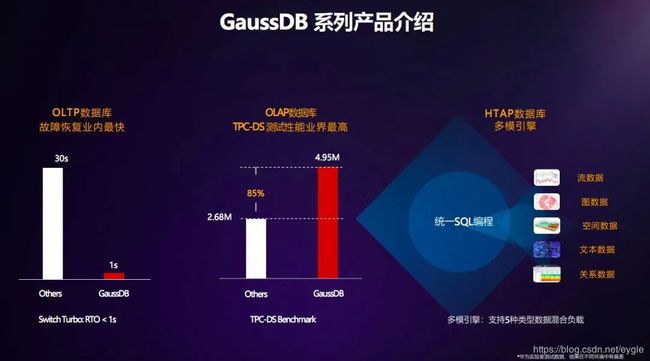
其实,GaussDB并非是一个产品,而是系列产品的统称,目前GaussDB至少包含有3款产品,有面向OLTP的数据库,面向OLAP的数据仓库,还有面向事务和分析混合处理的HTAP数据库。
01
数据库内核开发如刀尖上跳舞
做数据库内核开发如在刀尖上跳舞,压力很大,但凡在内核架构与机制制定上有一丝一毫没考虑清楚,那么,上线就一定会出问题,后果严重。因为,一旦确定的方向进行不下去,就会导致推倒重来。一位核心研发工程师对笔者说。

2007年,因为电信实时计费项目困境,华为开始组织人手研发内存数据库,项目代号GMDB,这是可追溯华为最早的数据库研发记录。
当时,华为决定自研内存数据库的想法并不高大上,而是很单纯,完全不是外界所猜想的搞个数据库去售卖并干掉谁,纯粹只是因为在电信计费领域,华为解决方案找不到能与之很好契合的数据库,仅此而已。
众所周知,电信行业对数据库要求较高,尤其是可用性,定制化需求较多,涉及改动工作量大,而采用国外数据库,让原厂来配合改动,人家未必会配合。因此,无奈下,华为被迫走上了自研数据库的道路,以此来提升自身解决方案的竞争力。
不过,2007年的GMDB并没有取得大规模商用,只在小范围内进行试用,但这个版本却锻炼了一大批人。当时,国内对数据库内核开发知之甚少,有经验者寥寥,都是摸着石头过河。
但有苗不愁长,到了2010年,华为数据库研发团队开始对2007年版本进行全面重构,并写下了重构版本的第一行代码:
“typedef struct st_database{...}database_t;”
数据库对象的定义。
从这个版本开始,华为数据库的定位已经不再仅局限于内存数据库,而是在向通用关系型数据库逐渐转变,重构过程中,开始融入大量非内存数据库的特性,这就是Gauss OLTP数据库的前身。
重构后的版本,质量上取得了显著提升,2012年,GMDB开始大规模商用,主要应用于电信计费领域,同时,在华为内部,众多配套的解决方案也开始使用GMDB。
对于每一个刚诞生的新产品,华为都不会先让客户当“小白鼠”,“狗粮” 华为一定是自己先吃,一位核心研发工程师对笔者说。
GaussDB对外输出之前,华为也是从服务内部开始。但在华为,内部客户远比外部客户更苛刻更残酷。“往往只要有一点不满意,内部客户就会直接一个邮件捅到总裁或副总裁那里,连个喘息的机会都不给你,那是真的要命啊!”,一位核心研发工程师心有余悸的回忆说。因此,在服务内部客户的过程中,GaussDB研发团队总是胆战心惊。
为了让Gauss OLTP数据库的内核变得更稳定,研发团队创造了最暴力的测试方法,并立下规矩,谁发现的问题,用例就用谁的名字来命名。在暴力测试方法及命名规则的双重刺激下,从刚开始几乎每半天就能测出问题,到之后一个周甚至一个月才能发现一个问题。正是这样一步步的积累下来,让Gauss OLTP数据库的内核变得越来越强壮和稳健。因此,从2013年规模上线到2019年,6年的时间里,Gauss OLTP数据库没出过任何问题,这一点让团队成员极为自豪。
华为强大的研发平台一直是外界所公认的,而正是基于强大的研发平台为Gauss OLTP数据库的产品质量提供了强有力的保障。在软硬件基础设施方面,华为过去几十年的积累非常深厚,有着整套完整的标准流程和研发支撑体系。Gauss OLTP数据库首席架构师告诉笔者,高手毕竟是少数,一个产品的开发不能完全依赖编码高手,在团队作战的时候,一个大的研发平台至关重要,这就是华为数据库的最大优势。
2017年,华为与招商银行开始就GaussDB进行联合创新;2018年3月,Gauss OLTP数据库开始在招商银行综合支付交易系统成功上线投产,顺利承接招商银行 “手机银行”和“掌上生活”两大App交易流水流量,日均请求量高达8500万,峰值TPS达到3500,截至目前,系统稳定运行。
如今招商银行的信用卡风警系统、零售实时风险警示系统、手机银行收支账单系统、一网通用户日志系统、客户经理平台系统、供应链金融服务平台系统、分布式交易链路追踪系统等多套业务系统已进入对接开发阶段,预计2019年底前将有17套系统采用GaussDB并投产上线。
02
MPP分布式并行踩过的坑
华为真正想做数据库,把数据库作为一个完整的产品来做,其实是始于2011年底。当时,华为成立了2012实验室,也有了高斯实验室和Gauss DB。

就在这年,华为同时启动了面向OLAP数据库的研发预演,并足足用了3年的时间来预演代码和验证架构的可行性。研发团队分析了业界数据库相关理论和技术,在基于传统关系型数据库的SQL引擎和事务强一致性等基础上,进行了分布式、并行计算的改造。2014年,孵化出Gauss OLAP数据库第一个产品版本。
2015年,华为与工商银行一起联合创新,Gauss OLAP数据库也开始在工商银行内上线,并逐渐取代某国外品牌数据仓库。从一开始的十几个节点到现在的单个集群超过二百个节点,这大概是目前国内数据仓库中最大的。事实上Gauss OLAP数据库的产品交付过程也并非一帆风顺,也是经历了诸多磨难,尤其是在MPP大规模通信上踩过不少坑。
“最初,Gauss OLAP数据库采用的是SCTP通信协议。当时,工商银行的EDW数据仓库已经有上百个节点,再往上扩容,通信就面临很大的挑战”,Gauss OLAP数据库的一位核心研发工程师说。
因为,研发团队在实验室测试发现,随着集群的扩大,SCTP协议存在BUG,问题严重,一方面是稳定性,通信变得很不稳定,丢包严重,其次是性能,在大压力下,性能变得非常不稳定,而且存储空间已经达到70%了,照这样下去, 再有几个月集群空间肯定就不够用了,业务就会停摆责任之大,谁也承担不起。怎么办?
经过与客户沟通,工行要求华为Gauss OLAP数据库团队必须尽快扩容一倍以上的节点。
此时,整个研发团队的压力可想而知,团队内部经过了无数次激烈的讨论后,最终决定采用自研的多流代理通信技术重构解决该问题。而这一重构,前后就花了半年多时间,最终扩容成功,确保了工行业务的稳定运行。
这样的故事,在Gauss OLAP数据库产品化的过程中不胜枚举。“没有以客户为中心的理念,没有像工行这样优质客户的积极反馈与配合,就不会有今天成熟可靠的Gauss OLAP数据库”,这位工程师说。
而在内核研发过程中,对研发团队而言,最大的痛苦莫过于完全无法预知外部客户会怎样去使用GaussDB,客户并不会像内部客户严格按照规范来,因此,当出现问题时,定位问题复现问题就显得尤为重要,因为,只有定位到问题才能对症下药,如果连故障原因都找不到,解决问题也就无从谈起。
华为在数据库内核构建中,有着非常严格的要求,一旦发现的问题被解决后,一定要复盘,解决问题一定是经过严格推导出来的,如果问题解决过程含糊不清,或稀里糊涂的把问题解决了,这在华为是绝对不行的。
在所有测试中发现的问题,规范要求都必须要放入CI(数据库用例全集)里,这样CI就会被不断补充。“CI就像一道‘门禁’,数据库每一个版本的发布,必须要通过十年所积累的所有用例,只要一个没通过,就甭想发布。”
让工程师们印象最为深刻的是一次定位分布式事务一致性问题, 各种DDL, DML 高并发执行, 每隔几分钟,随机Kill 数据节点进程,验证实时校验数据的一致性长期稳定运行。
开始一切正常,但就在第17天的时候,测试发现有瞬间数据不一致问题,Log里并没有足够定位信息,也无法复现,定位了好几天没有进展,存储引擎团队的核心开发人员都很沮丧。
于是团队自行封闭会议,开始对MVCC机制,CSN可见性判断逻辑, Prune清理记录历史版本的逻辑做了逐行代码排查分析,结合log, 模拟并行执行的时序,最终找到了根因,Prune记录的历史版本过早导致的问题。
也正是基于此,促使Gauss OLAP数据库团队开始思考并发场景测试方法如何才能更有效,因为是并发时序问题,出问题的时间窗口是很难卡到的,要在代码里模拟触发随机异常且控制其他线程的时序,才能让测试覆盖更全面,而这种测试方法帮助研发团队发现和解决了很多问题。
2017年,华为又启动了面向事务和分析混合处理的数据库研发。2018年,华为第一个Gauss HATP数据库问世,并成功落地中国民生银行。据悉,民生银行采用了GaussDB分布式数据库+ARM服务器的全栈解决方案,从数据库层面解决了可扩展性问题,降低了应用分布式改造的难度,已应用于一卡通、贵金属模拟交易等交易类系统,是国产数据库在银行交易类系统的首次商用。
03
逻辑集群差点与GaussDB失之交臂
GaussDB有一个特性,叫逻辑集群,可以实现多个业务系统的统一管理,计算弹性共享。这是个对客户非常有价值的特性,也符合客户云化多租户的业务演进趋势。但就是这样一个非常有价值的特性,前期的规划也是一路坎坷。
这一个特性最初由某个核心工程师提出,起初并不为团队一些成员所认可,认为这个特性并没有什么价值。
后来,GaussDB产品管理团队经过大量客户的走访,对客户业务系统的痛点、需求、以及未来发展趋势进行了详细的梳理,发现随着海量数据的爆炸式增长,数据分析的诉求越来越旺盛,客户分析系统也越来越多,面临的运维管理复杂性也就越来越高。同时,云化也是一个趋势,很多客户希望能够基于云化模式建设数据分析系统,能够实现资源弹性共享,而逻辑集群的特性恰好可以完美的解决客户的业务诉求。
最终,产品管理团队内部达成一致。如今,这个特性已经成为GaussDB的一个非常有差异化竞争力的特性。
04
搞数据库,华为是认真的
不过,华为将GaussDB定位于AI-Native数据库而非Cloud-Native数据库,这不仅是一种升维,更是源于GaussDB实现的两大革命性突破:其一,AI in DB,首次将 AI 技术引入了GaussDB全系列产品内核中,实现自运维、自管理、自调优、故障自诊断和自愈,调优性能比业界提升60%以上。其二,DB for AI,GaussDB数据库适配AI的运行。用户可以通过数据库语言来方便地使用AI,降低AI使用门槛,实现普惠AI。同时,GaussDB 通过异构计算创新框架,充分发挥了x86、ARM、GPU、NPU多种算力优势,在权威标准测试集TPC-DS上,性能比业界提升50%。
华为GaussDB希望通过智能、异构、融合这三个方面,重新定义数据处理平台。
华为以硬件闻名,因此,很多人会质疑华为的软件研发能力,事实上,在华为8万多研发工程师中,有70%是从事软件研发人员。这是汪涛在发布会上,接受媒体采访时给出的数据。
华为在数据库领域已经投入了千人左右的研发工程师,这一规模是很多数据库厂商难忘项背的。不过,华为做数据库并不是为替代谁,目前华为内部也在使用其他的数据库,比如Oracle,SQL Server,MySQL等,以后也依然会继续用。华为做GaussDB数据库的目的,一方面是对华为AI战略的承接,一方面是为了构筑硬件+软件+生态的战略布局。
截止目前,华为GaussDB数据库和FusionInsight大数据平台已经应用于全球60个国家及地区,服务于1500多个客户,拥有500多家商业合作伙伴,并广泛应用于金融、运营商、政府、能源、医疗、制造、交通等多个行业。
GaussDB也具有云上的版本。目前华为云已经发布了13款数据库服务,其中DWS数据仓库服务就是GaussDB OLAP数据库的云化版本,为行业客户提供云上数据仓库服务。华为还将继续培养基于GaussDB数据库的生态环境,让更多的IT公司可以基于新数据库开发相应的产品,让GaussDB数据库在更大范围内得到应用。
05
写在最后
还记得华为GaussDB发布视频中的一行文字:向数学致敬、向科学家致敬。GaussDB,不仅蕴含着华为对数学和科学的敬畏,也承载着华为对基础软件的坚持和梦想。
从GaussDB工程师身上,我看到了一种“轴”,这是对技术的精益求精和偏执。这正是这种“轴”,才能让这群工程师们坚持12年,历经坎坷,最终在被誉为基础软件“皇冠上明珠”的数据库领域中一举突围,破茧成蝶。
出处:公众号老鱼笔记
想了解更多关于数据库、云技术吗?
快来关注”数据和云“公众号,”云和恩墨“官方网站,我们期待与大家一同学习和进步。
(扫描上方二维码,关注“数据和云”公众号,即可查看更多科技文章)