亚马逊商品抓取 爬虫
今天搞了下亚马逊的商品爬虫,需求是设置关键词,爬取前100个商品的图片和描述。实际做了才发现是真的坑2333。
一开始,尝试用python+requests正常处理。结果一路顺风,啥问题没有。我还很开心的嘞,而且第一遍测试都很靠谱的。但是后面修bug的时候测试跑不通了,而且是访问第一个商品就报错了。报错有两种,一种是网络错误,另一种是显示Type the characters you see 就是出验证码的情况。
于是,我开始各种搜索解决方法,试了换useragent,保存cookie,都没用。另外据说就算破解验证码,次数过多之后也会挂掉,而且破解验证码不管是人工打码还是机器学习,对于我来说成本都太高了。最后我用了selenium调用chrome来访问,至少短时间是不会被封了。
其他的问题就是如何excel插入图片,excel的宽度要换算成像素
附部分代码
# -*- coding: utf-8 -*-
"""
File Name: amzone
Description :
Author : meng_zhihao
mail : [email protected]
date: 2019/5/8
"""
# 美国amazon
import requests,urllib
import datetime
from urllib import quote,unquote
from selenium_operate import ChromeOperate
import re
import time
from crawl_tool import crawlerTool as ct
import os,base64
import xlsxwriter
from PIL import Image
HEADERS = { 'User-Agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 10_1_1 like Mac OS X) AppleWebKit/602.2.14 (KHTML, like Gecko) Mobile/14B100 MicroMessenger/6.3.22 NetType/WIFI Language/zh_CN'
}
se = requests.session()
def img_resize(infile,outfile):
im = Image.open(infile)
# (x, y) = im.size # read image size
x_s = 120 # define standard width
y_s = 160 # calc height based on standard width
out = im.resize((x_s, y_s), Image.ANTIALIAS) # resize image with high-quality
out.save(outfile)
def gen_xls(item_infos):
timestamp = datetime.datetime.now().strftime("%Y%m%d%H%M%S")
book = xlsxwriter.Workbook('amazon%s.xlsx'%timestamp)
worksheet = book.add_worksheet('demo')
worksheet.write_row(0,0, ['关键词','排名','宝贝图片','价格','宝贝类目','宝贝描述','宝贝链接'])
worksheet.set_column('A:D', 15) # 列宽约等于8像素 行高约等于1.37像素
worksheet.set_column('C:C', 20)
worksheet.set_column('B:B', 10)
worksheet.set_column('F:F', 50)
for i in range(len(item_infos)):
col = i+1
try:
item_info = item_infos[i]
row = [item_info['keyword'],item_info['rank'],'',item_info['price'],item_info['cat'],item_info['descriptions'],item_info['item_url']]
worksheet.write_row(col,0, row)
worksheet.set_row(col, 120)
if 'item_pic_base64' in item_info:
item_pic_base64 = item_info["item_pic_base64"]
try:
if 'https:' in item_pic_base64:
data = ct.get(item_pic_base64)
else:
data = base64.b64decode(item_pic_base64)
with open('test.png', 'wb') as f:
f.write(data)
img_resize('test.png', 'img/tmp%s.png'%i)
worksheet.insert_image( col,2, 'img/tmp%s.png'%i) # 名字必须不同
except Exception,e:
print str(e)
except Exception,e:
print e,item_info
print '完成结果数,%s'%col
book.close()
def extractor_page(page): # 解析宝贝页
item_info = {"descriptions":""}
descriptions = ct.getXpath('//div[@id="productDescription"]/p/text()',page)
if not descriptions:
descriptions = ct.getXpath( '//div[@id="aplus"]/div//p//text()', page)
descriptions= ''.join([description.strip() for description in descriptions])
item_info["descriptions"] = descriptions
item_pic_base64 = ct.getXpath1( '//div[@id="imgTagWrapperId"]/img/@src', page).split('base64,')[-1]
item_info["item_pic_base64"] = item_pic_base64
price = ct.getXpath1( '//span[@id="priceblock_ourprice"]/text()', page)
item_info["price"] = price
cats = ct.getXpath( '//div[@id="wayfinding-breadcrumbs_container"]//a/text()', page)
item_info["cat"] = '/'.join([cat.strip() for cat in cats])
for k,v in item_info.items():
print k,v
return item_info
if __name__ == '__main__':
#start_url = 'https://xueqiu.com/v4/statuses/public_timeline_by_category.json?since_id=-1&count=15&category=105'
csv_rows=[]
cookie = {}
item_infos = []
cop = ChromeOperate(executable_path=r'chromedriver.exe')
cop.get('https://www.amazon.com/')
with open('keywords','r') as keyword_file:
for line in keyword_file:
line = line.strip()
if not line:
continue
urls = ['https://www.amazon.com/s?k=%s&ref=nb_sb_noss_2'%quote(line),
# 'https://www.amazon.com/s?k=%s&ref=nb_sb_noss_2&page=2 ' % quote(line)
]
rank = 0
for url in urls:
# HEADERS.update({"Referer":url,"User-Agent":random.choice(USER_AGENT_POOL)})
cop.get(url)
page = cop.get_page()
item_urls = ct.getXpath('//div[@class="sg-row"]//div[@class="sg-col-inner"]//h2/a/@href',page)
if not item_urls:
print page
for item_url in item_urls:
rank += 1
try:
if not 'qid' in item_url:
continue
else:
item_url = 'https://www.amazon.com'+item_url
cop.get(item_url)
page = cop.driver.page_source
if 'Kindle Edition' in page:
continue
item_info = extractor_page(page)
if 'Type the characters you see' in page :
print 'IP被封了',url
time.sleep(10)
# print page
break
item_info['keyword'] = line
item_info['rank'] = rank
item_info['item_url'] = item_url.split('?')[0]
item_infos.append(item_info)
except Exception,e:
print str(e)
gen_xls(item_infos)
cop.quit()
#15:29
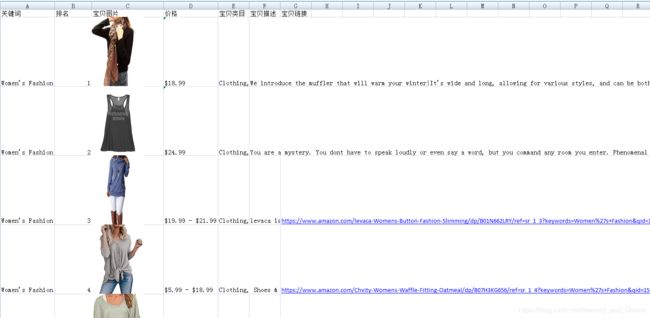
实际数据效果