相关缓存面试问题总结(二)
目录
1.怎么保证redis重启后数据进行恢复(持久化)
1.1redis的持久化的意义
1.2解析RDB和AOF持久化的机制的工作原理
1.3RDB和AOF各自的优缺点
2.redis cluster集群模式的原理
2.1redis单master架构的容量瓶颈
2.2分布式数据存储的核心算法
2.2.1hash算法
2.2.2一致性hash算法
2.2.3hash slot算法
2.3redis的通信原理
3.缓存雪崩和缓存穿透的问题
3.1缓存雪崩
3.2缓存穿透及解决方案
4.如何保证高并发数据库和缓存双写的一致性
4.1最初级的数据库+缓存双写不一致的情景
4.2读写并发数据库+缓存双写不一致的场景
1.怎么保证redis重启后数据进行恢复(持久化)
1.1redis的持久化的意义
缓存,当然也可以保存一些较为重要的数据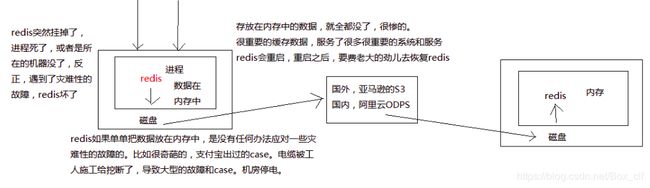
1.2解析RDB和AOF持久化的机制的工作原理
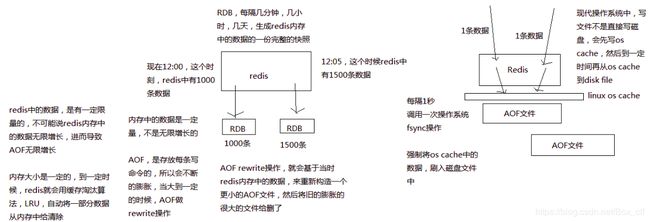
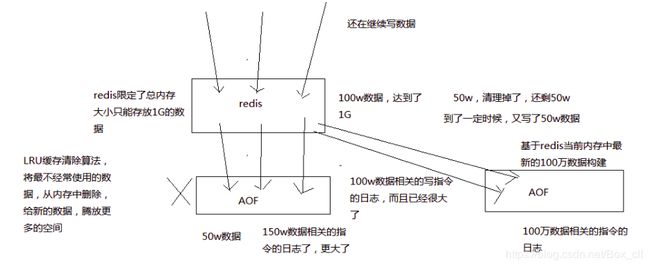
- redis只会写一个AOF文件,所以AOF会越写越大
- 当AOF大到一定程度,会创建一个新的AOF文件
- rewirte的新的AOF文件会根据当前内存中数据生成
- 而旧的AOF会被删除
AOF的rewrite的原理剖析:
如果说redis挂了,服务器上的内存和磁盘上的数据都丢了,可以从云服务上的拷贝回来之前的数据,放到指定的目录中,然后重启redis,redis就会自动根据持久化的数据文件中的数据,去恢复内存中的数据,继续对外提供服务。
1.3RDB和AOF各自的优缺点
RDB的优点:
- RDB做冷备优势:由redis去控制固定时长生成快照文件的事情,比较方便,
- RDB对redis对外提供的读写服务,影响非常小,可以让redis保持高性能
- 相对于AOF持久化机制来说,直接基于RDB数据文件来重启和恢复redis进程,更加快速
注意:AOF,存放的指令日志,做数据恢复的时候,其实是要回放和执行所有的指令日志,来恢复出来内存中的所有数据的
RDB,就是一份数据文件,恢复的时候,直接加载到内存中即可
RDB的缺点:
- 如果想要在redis故障时,尽可能少的丢失数据,那么RDB没有AOF好。一般来说,RDB数据快照文件,都是每隔5分钟,或者更长时间生成一次,这个时候就得接受一旦redis进程宕机,那么会丢失最近5分钟的数据
- RDB每次在fork子进程来执行RDB快照数据文件生成的时候,如果数据文件特别大,可能会导致对客户端提供的服务暂停数毫秒,或者甚至数秒
AOF的优点:
- AOF可以更好的保护数据不丢失,一般AOF会每隔1秒,通过一个后台线程执行一次fsync操作,最多丢失1秒钟的数据,每隔1秒,就执行一次fsync操作,保证os cache中的数据写入磁盘中
- AOF日志文件以append-only模式写入,所以没有任何磁盘寻址的开销,写入性能非常高,而且文件不容易破损,即使文件尾部破损,也很容易修复
- AOF日志文件即使过大的时候,出现后台重写操作,也不会影响客户端的读写
- AOF日志文件的命令通过非常可读的方式进行记录,这个特性非常适合做灾难性的误删除的紧急恢复。
AOF的缺点:
- 对于同一份数据来说,AOF日志文件通常比RDB数据快照文件更大
- AOF开启后,支持的写QPS会比RDB支持的写QPS低,因为AOF一般会配置成每秒fsync一次日志文件,当然,每秒一次fsync,性能也还是很高的
- 唯一的比较大的缺点,其实就是做数据恢复的时候,会比较慢
2.redis cluster集群模式的原理
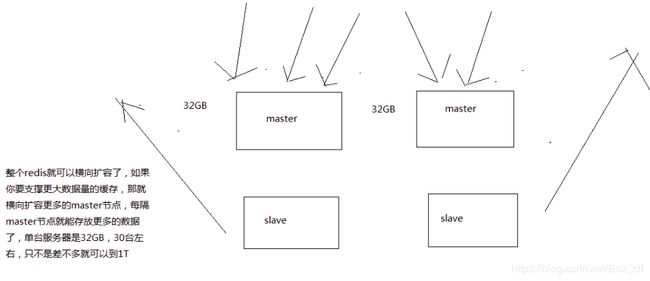
2.1redis单master架构的容量瓶颈
因为slave节点和master节点的数据完全一致,所以master节点的容量大小就是最多能存放数据的大小。
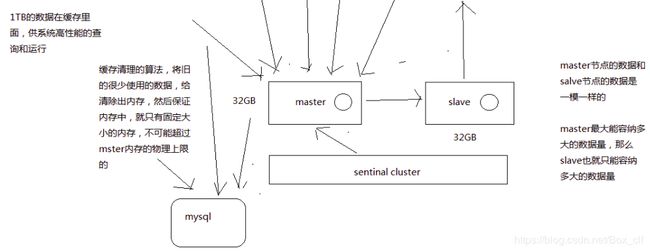
解决方案:横向扩展master,通过redis cluster实现横向扩展,仍然可以保证读写分离。如果master挂掉,redis cluster这套机制会自动将某个slave切换成master。
简而言之:redis cluster(多个master + 读写分离 + 高可用),主要针对海量数据 + 高并发 + 高可用的场景
2.2分布式数据存储的核心算法
hash算法--》 一致性hash算法(memcached)---》 redis cluster,hash slot算法
解决的问题:主要解决当存在多个master的节点时,数据如何分布到这些节点上去。
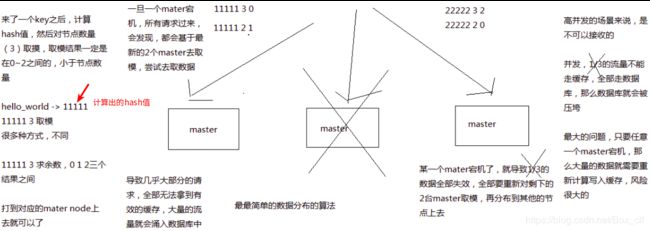
2.2.1hash算法
先根据缓存数据的key进行hash,再对hash值进行取模,注:模为机器数。取得的余数就为对应的需要缓存进的master。
存在问题:当取模后的余数对应的机器挂掉后数据将无法写入到缓存,最主要的问题是当有一个master宕机,会重新按照新的模(机器数)去取数据从而导致取出大量的错误数据。
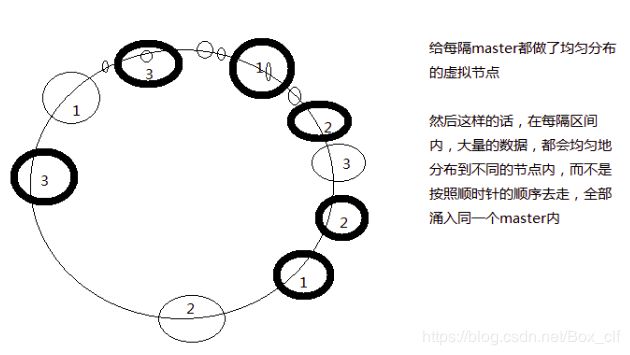
2.2.2一致性hash算法
主要存在的问题:1/3的流量无法取得数据从而直接涌入数据库。(相对于hash算法而言,就算有master宕机取数据也不会出错)

一致性hash算法的虚拟节点解决负载均衡
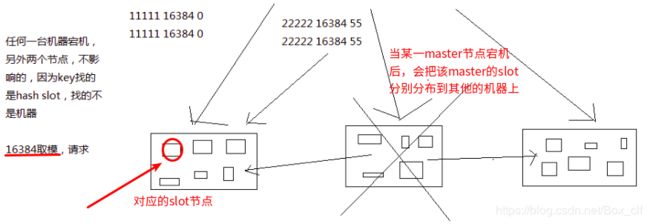
2.2.3hash slot算法
2.3redis的通信原理
对元数据的维护有下面两种方式:
1.集中式的方式进行元数据的维护
优点:元数据的更新和读取,实效性非常好,一旦元数据进行更新,立即会更新到集中式的存储中哦哦嗯,其他节点读取的时候就立即可以感知到了。
缺点:所有的元数据的更新压力全部集中在一个地方,可能会导致元数据的存储压力
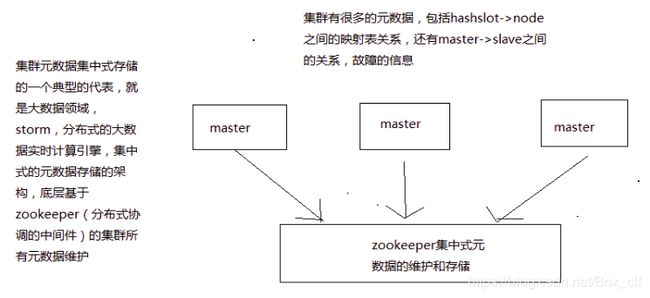
2.redis cluster节点采用gossip协议进行通信对元数据进行维护
优点:元数据的更新比较分散,不是集中在一个地方,更新请求会陆陆续续打入其他节点进行更新,有一定的延时降低压力
缺点:元数据更新的延时,可能会导致集群操作有一些滞后。

3.缓存雪崩和缓存穿透的问题
3.1缓存雪崩
发生的现象:
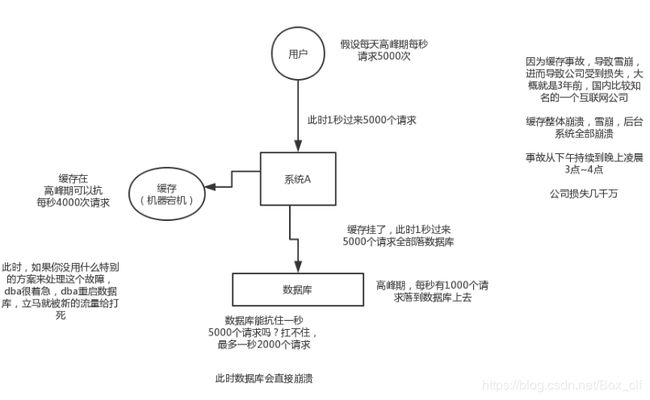
解决方案:
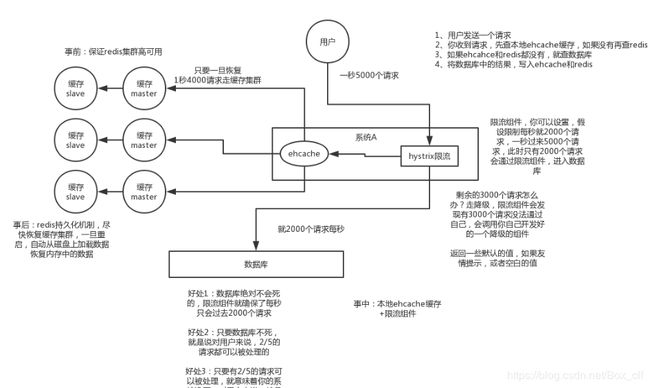
3.2缓存穿透及解决方案
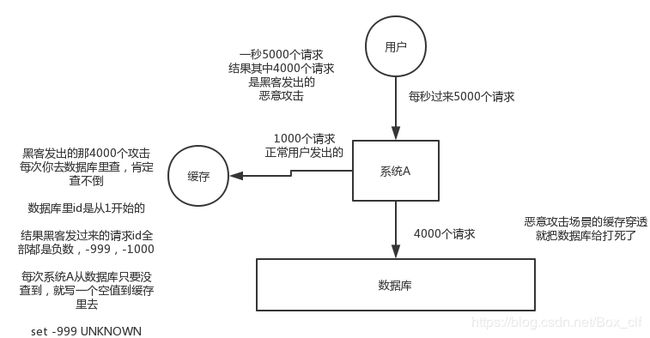
4.如何保证高并发数据库和缓存双写的一致性
4.1最初级的数据库+缓存双写不一致的情景
当请求过来对库存进行修改时,若先对数据库进行更新操作再进行缓存数据的更新,这时如果缓存更新的请求发送出现失败,则导致缓存数据不一致。
解决方案:先对缓存数据删除,删除成功再更新数据库,最后再重新写入缓存。
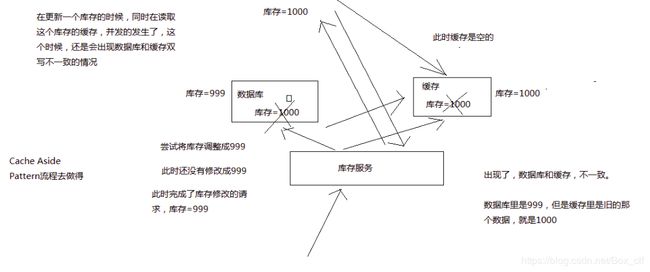
4.2读写并发数据库+缓存双写不一致的场景
当更新数据库的请求过来时,同时过来了一个查询请求,这是查询请求没有从缓存中获取数据就会去数据库中进行查询并写入到缓存;但此时对缓存进行更新后数据库的数据也进行了修改导致实际的缓存数据和数据库数据不一致。

消息队列解决:每一个请求都进行入队,进行异步处理,同时需要注意当大量的写请求入队导致读请求的延时问题,如果有一定的延时过长设置特定的返回值。
28-1