python爬取饿了么数据(2)
上一节我们去到了关键字 查询得到的附近商圈地点,
这一节我们查询地点附近的所有商家的月销售情况
1、网页信息
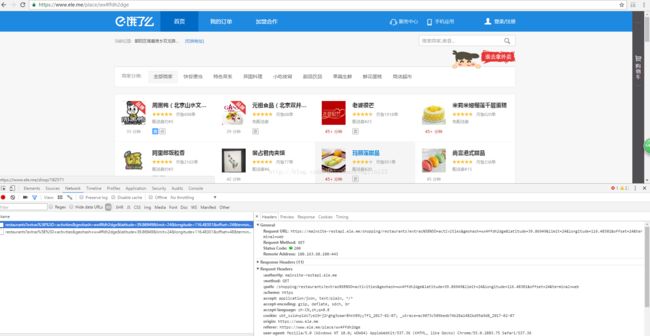
在上一节展现的那个网页随便选取一处地点,就会跳转到上面的页面,
我们向下滑动鼠标的时候,网页是动态加载数据的,我们打开这个网页的时候,首先清空所有的页面请求,然后滑动鼠标,可以看到网页会自动去请求数据,
分析url可以发现,
url请求是:
https://mainsite-restapi.ele.me/shopping/restaurants?extras%5B%5D=activities&geohash=wx4ffdh2dge&latitude=39.86949&limit=24&longitude=116.48301&offset=24&terminal=web
header:
url请求参数:
分析url请求和请求参数 也可以发现,“?”后面的内容是编码之后的请求参数,
limit参数 可以理解成,每次加载的数据条数是24条
至于offset,我们滚动几次鼠标滑轮,就会发现,offset 是以24为基础递增的,0,24,48,72,96.....
这样我们需要循环取数据,直到该商圈地点附近没有外卖商家信息,进行下一个商圈地点的数据爬取
所以我们的策略是
构造header请求,
根据上一节存储到excel 的数据,构造请求参数,
循环发送请求,每次设定不同的偏移量(offset),取得数据,写入新的excel 中
2、代码如下
#爬饿了么外卖数据--区域下各个地点的商家集合
#https://mainsite-restapi.ele.me/v2/pois?
#extras%5B%5D=count&geohash=wx4g0bmjetr7&keyword=%E6%9C%9D%E9%98%B3&limit=20&type=nearby
import urllib.request
import os
import json
import time
from openpyxl import Workbook
from openpyxl import load_workbook
keywordExcel="D:\worksapce\python\爬虫饿了么\\keyword.xlsx"
keywords=[]
targetDir ="D:\worksapce\python\爬虫饿了么" #文件保存路径
def excelName():#根据日期生成文件
if not os.path.isdir(targetDir):
os.mkdir(targetDir)
excelName=str(time.strftime ("%Y-%m-%d")+".xlsx")
completePath=targetDir+"\\"+excelName
return completePath
def reqsetting():#初始化url请求,需要实时替换的是extral 和 header里的referer
weburl = "https://mainsite-restapi.ele.me/shopping/restaurants?"
extra1="extras%5B%5D=activities&geohash=wx4g56v1d2m&latitude=39.91771&limit=24&longitude=116.51698&offset=0&terminal=web"
webheaders={
"Accept":"application/json, text/plain, */*",
"Accept-Language":"zh-CN,zh;q=0.8",
"Connection":"keep-alive",
"Cookie":"ubt_ssid=plds7ye19rj2rghg3oaar8hkt89yy7f1_2017-02-07; _utrace=ac9073c509bedb74b28a1482bd95a9d8_2017-02-07",
"Host":"mainsite-restapi.ele.me",
"Origin":"https://www.ele.me",
#"Referer":"https://www.ele.me/place/wx4g56v1d2m",
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.75 Safari/537.36"
}
req=urllib.request.Request(url=weburl,headers=webheaders)
return req
def write2Excel(jsondata,title):#根据不同的商圈地点写入数据,每个商圈地点占用excel 的一个sheet
fileName=excelName()
isexit="false"
if(os.path.exists(fileName)):
wb=load_workbook(fileName)
isexit="true"
else :
wb=Workbook()
if(wb.__contains__(title)):
ws=wb[title]
ws.append([])
else:
ws=wb.create_sheet(title)
ws.column_dimensions["A"].width =10.0
ws.column_dimensions["B"].width =40.0
ws.column_dimensions["C"].width =60.0
ws.column_dimensions["D"].width =10.0
ws.column_dimensions["E"].width =18.0
ws.column_dimensions["F"].width =10.0
ws.append(["ID","店名","地址","距离","人均消费","月销售额"])
for i in range(len(jsondata)):
row=jsondata[i]
#print(type(row))
if("average_cost" not in row.keys()):
row["average_cost"]="无人均消费数据"
ws.append([row["id"],row["name"],row["address"],row["distance"],row["average_cost"],row["recent_order_num"]])
wb.save(fileName)
def readKeyWordFromExcel():#从上一节生成的keywordExcel 中加载商圈地点
fileName=keywordExcel
if(os.path.exists(fileName)):
wb=load_workbook(fileName)
else:
return
for title in wb.sheetnames:
ws=wb[title]
for i in range(2,ws.max_row):
infos={}#商圈地点数据,为生成请求参数做准备
infos["name"]=ws.cell(row=i,column=4).value
print("正在爬取 %s 附近外卖商家的数据..." % infos["name"])
infos["ID"]=ws.cell(row=i,column=1).value
infos["geohash"]=ws.cell(row=i,column=3).value
infos["longitude"]=ws.cell(row=i,column=7).value
infos["latitude"]=ws.cell(row=i,column=8).value
if(infos["geohash"]):
req=reqsetting()
req.add_header("Refer","https://www.ele.me/place/%s" % infos["geohash"])#修改请求头的refer
newUrl=req.get_full_url()
offset=0
contentBytes=""
while(contentBytes!="[]"):#构造请求参数,基本上只修改offset 偏移量数据
params={
"extras[]":"activities",
"geohash":"%s" % infos["geohash"],
"latitude":"%s" % infos["latitude"],
"longitude":"%s" % infos["longitude"],
"terminal":"web",
"limit":24,
"offset":offset
}
params=urllib.parse.urlencode(params)#请求参数编码
req.full_url=newUrl+params #重新生成url请求
webpage=urllib.request.urlopen(req)
contentBytes = webpage.read().decode("utf-8")
if(contentBytes!="[]"):
jsondata=json.loads(contentBytes)
write2Excel(jsondata,infos["name"])#将请求数据写入excel中
offset+=24 #便宜
else :
break
if __name__ == '__main__': #程序运行入口
offset=0;
readKeyWordFromExcel()