基础自我总结
一、集合容器
1、为什么需要容器?
《thinking in java》书中说:“如果一个程序只包含固定数量的且生命周期都已知的对象,那么这是一个非常简单的数据。”但是事实上,我们平时接触的程序都不是如此简单的,很多程序都是在运行时才知道需要创建什么对象、创建多少对象,因此很可能我们需要在任意时刻任意位置创建任意数量的对象。因此,不能依靠创建命名的引用持有每一个对象,因为不确定性,我们必须要动态的创建对象,保存对象(其实是对象的引用)。
2、集合框架图:
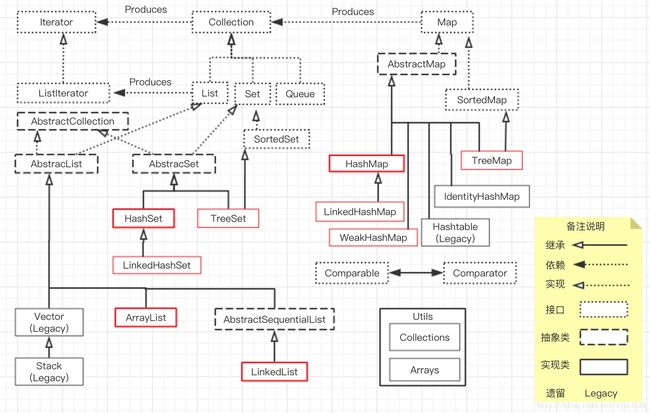
3、具体框架内容分析:
3.1:ArrayList
3.1.1是顺序容器,底层通过数组实现,允许放入null值;grow()方法扩容,1.5倍扩容;
3.1.2对于ArrayList而言,size(),isEmpty(),get(),set()方法的时间复杂度是常数时间,add()方法开销和插入的位置有关,addAll()方法开销和添加的元素数量成正比,其余方法都是线性时间完成。
3.1.3 ArrayList删除目标索引位置,之后该位置是为null,还是后面补上;测试结果:后面元素补上!
3.2LinkedList
3.2.1实现了List接口,因此它也是一个顺序容器,但是同时也可以将其用作栈、队列或双端队列(实现了Deque接口)。LinkedList底层通过双向链表实现;
3.2.2Node(item,next,prev);
3.2.3LinkedList的first和last引用分别指向链表的第一个和最后一个元素,链表为空时,first和last指向null。
3.3.4测试LinkedList删除目标索引位置,之后该位置是为null,还是后面补上;测试结果:后面元素补上!
3.3HashMap
3.3.1实现了Map接口,该容器不保证元素顺序,会根据需要对元素进行重新hash,不同时间对同一个HashMap迭代元素顺序可能会不同。
3.3.2HashMap的底层实现是数组+单向链表/红黑树,借助hash表,处理hash冲突使用的是冲突链表方式(另一种解决冲突方法为开放地址法)
(ps:jdk1.8对hashmap进行了很多优化,当冲突链表长度大于8时使用红黑树解决冲突,从而在链表过长是提高查找效率)
3.3.3这里的两个关键方法时hashCode()和equals(), hashCode方法决定了对象会被放到哪个bucket,超过一个对象放入相同的bucket时即为冲突,equals方法用于区别冲突链表中的对象是否是同一个
3.3.4HashMap有连个关键参数,初始容量(inital capacity)、负载因子(load factor),初始容量指定了table的大小,这个参数和哈希函数会影响到冲突的频繁性,负载因子用来指定自动扩容的临界值,当entry(存放键值对的对象)的数量超过capacity*load_factor时,会进行自动扩容和重新哈希。
3.3.5如何确保key的唯一性的?根据key.hash和key.equals(https://cloud.tencent.com/developer/article/1490411)
HashMap-putVal() 方法分析 (https://blog.csdn.net/AJ1101/article/details/79413939)
3.4HashSet
3.4.1借助HashMap实现了无重复元素的集合,对HashSet的函数调用本质上是对HashMap调用
3.4.2我们知道HashMap中的key是肯定唯一的不会重复的,因此HashSet利用了这一特点,在add的时候调用HashMap的put方法,map.put(e, PRESENT)如果有返回值说明HashMap中已经存在该元素,插入失败,如果返回null表明HashMap还没有要插入的元素,因此插入才会成功
3.5LinkedHashMap
3.5.1LinkedHashMap是HashMap的子类,二者区别在于LinkedHashMap在HashMap的基础上采用双向链表将冲突链表的entry联系起来,这样保证了元素的迭代顺序跟插入顺序相同
3.5.2冲突链表加入了双向链表的元素(before、after、next,其中next用于保证entry的链表结构,before、after用于完成双向链表的定义),同时引入了header指向双向链表的头部(哑元)。这样LinkedHashMap在遍历的时候不同于HashMap需要先遍历整个table,LinkedHashMap只需要遍历header指向的双向链表即可,因此LinkedHashMap的迭代时间只和entry数量相关。其他的包括初始容量、负载因子以及hashCode、equals方法基本和HashMap一致。
3.6LinkedHashSet
实现也是借助LinkedHashMap使用适配器模式实现
3.7WeakHashMap
是基于弱引用的HashMap,它里面的entry随时可能呗GC,使用主要集中在缓存场景
3.8TreeMap
TreeMap实现了SortedMap接口,会根据key的大小对Map中的元素进行排序。key的大小判断在没有传入比较器Comparator的情况下通过自身的自然顺序比较。TreeMap底层通过红黑树实现;目前还没搞深入研究
3.9TreeSet
借助TreeMap使用适配器模式实现
参数:https://blog.csdn.net/starlh35/article/details/79262472
https://my.oschina.net/90888/blog/1626065
二、IO
1、从硬盘已有的数据读取出来放内存里面的这个过程就是输入流。
外部--------->内存 输入流 读
把内存中的数据存储到硬盘中的这个过程就是输出流。
内存--------->外部 输出流 写
简单理解就是:以内存为中心。
2、Java Io流的概念
java的io是实现输入和输出的基础,可以方便的实现数据的输入和输出操作
3、Io流的分类:按照不同的分类方式,可以把流分为不同的类型。常用的分类有三种;
3.1按照流的流向分,可以分为输入流和输出流。(java的输入流主要是InputStream和Reader作为基类,而输出流则是主要由outputStream和Writer作为基类。它们都是一些抽象基类,无法直接创建实例。)
3.2按照操作单元划分,可以划分为字节流和字符流。
(字节流和字符流的用法几乎完成全一样,区别在于字节流和字符流所操作的数据单元不同,字节流操作的单元是数据单元是8位的字节,字符流操作的是数据单元为16位的字符)
(字节流主要是由InputStream和outPutStream作为基类,而字符流则主要有Reader和Writer作为基类。)
3.3按照流的角色划分为节点流和处理流
可以从/向一个特定的IO设备(如磁盘,网络)读/写数据的流,称为节点流。节点流也被称为低级流。
处理流则用于对一个已存在的流进行连接和封装,通过封装后的流来实现数据的读/写功能。处理流也被称为高级流。
(处理流可以“嫁接”在任何已存在的流的基础之上,这就允许Java应用程序采用相同的代码,透明的方式来访问不同的输入和输出设备的数据流)
处理流的功能主要体现在以下两个方面:
性能的提高:主要以增加缓冲的方式来提供输入和输出的效率。
操作的便捷:处理流可能提供了一系列便捷的方法来一次输入和输出大批量的内容,而不是输入/输出一个或者多个“水滴”。
4、常见流用法
Io体系的基类(InputStream/Reader,OutputStream/Writer)
Io体系的基类文件流的使用(FileInputStream/FileReader ,FileOutputStream/FileWriter)
转换流的使用(InputStreamReader/OutputStreamWriter)
对象流的使用(ObjectInputStream/ObjectOutputStream)的使用
5、使用原则:
2点原则:
如果是操作二进制文件那我们就使用字节流,如果操作的是文本文件那我们就使用字符流。
尽可能的多使用处理流,这会使我们的代码更加灵活,复用性更好。
6、面试题汇总
https://blog.csdn.net/chengyuqiang/article/details/79183748
https://blog.csdn.net/qq_36962144/article/details/79815457
https://blog.csdn.net/qq_37875585/article/details/89385688
7、总结图

8、Java NIO与IO
IO NIO 面向流 面向缓冲 阻塞IO 非阻塞IO 无 选择器
参考:http://ifeve.com/java-nio-vs-io/
参考:https://blog.csdn.net/nightcurtis/article/details/51324105
https://blog.csdn.net/panhaixin1988/article/details/42711075
https://blog.csdn.net/L1585931143/article/details/56686328
https://blog.csdn.net/L1585931143/article/details/54994897
三、反射
参考:https://www.jianshu.com/p/f4b49e5fa443
https://blog.csdn.net/maizi1045/article/details/53258551
https://blog.csdn.net/snn1410/article/details/44978457
四、设计模式
五、多线程