hadoop SequenceFile
SequenceFile是专为mapreduce设计的,是可分割的二进制格式,以key/value对的形式存储。在存储日志文件时,每一行文本代表一条日志记录。纯文本不合适记录二进制类型的数据。SequenceFile可以作为小文件的容器。
write
先看下 在hadoop中如何写SequenceFile。
private static final String[] DATA = {
"One, two, buckle my shoe",
"Three, four, shut the door",
"Five, six, pick up sticks",
"Seven, eight, lay them straight",
"Nine, ten, a big fat hen"
};
public static void main(String[] args) throws IOException {
Configuration configuration = new Configuration();
configuration.set("fs.defaultFS", "hdfs://hadoop:9000");
FileSystem fs = FileSystem.get(configuration);
Path path = new Path("hdfs://hadoop:9000/hadoop/seq/numbers.seq");
IntWritable key = new IntWritable();
Text value = new Text();
SequenceFile.Writer.Option valueOption = SequenceFile.Writer.valueClass(value.getClass());
SequenceFile.Writer.Option keyOption = SequenceFile.Writer.keyClass(key.getClass());
SequenceFile.Writer.Option file = SequenceFile.Writer.file(path);
//指定了 file optiona 就不需要指定 stream
// SequenceFile.Writer.Option stream = SequenceFile.Writer.stream(fs.create(path));
SequenceFile.Writer writer = SequenceFile.createWriter(configuration,file,keyOption,valueOption);
for (int i = 0; i <100; i++) {
key.set(100 -i);
value.set(DATA[i % DATA.length]);
System.out.printf("[%s]\t%s\t%s\n", writer.getLength(), key, value);
writer.append(key, value);
}
IOUtils.closeStream(writer);
}上面的代码基于hadoop 2.6.4,指定了 file option 就不能指定 stream option,否则会抛出异常。原因如下:
// check consistency of options
if ((fileOption == null) == (streamOption == null)) {
throw new IllegalArgumentException("file or stream must be specified");
}read
Configuration configuration = new Configuration();
configuration.set("fs.defaultFS", "hdfs://hadoop:9000");
FileSystem fs = FileSystem.get(configuration);
Path path = new Path("hdfs://hadoop:9000/hadoop/seq/numbers.seq");
SequenceFile.Reader.Option file = SequenceFile.Reader.file(path);
SequenceFile.Reader reader = new SequenceFile.Reader(configuration,file);
Writable key = (Writable) ReflectionUtils.newInstance(reader.getKeyClass(),configuration);
Writable value = (Writable)ReflectionUtils.newInstance(reader.getValueClass(),configuration);
long position = reader.getPosition();
while (reader.next(key,value)){
String syncSeen = reader.syncSeen() ? "*" : "";
System.out.printf("[%s%s]\t%s\t%s\n", position, syncSeen, key, value);
position = reader.getPosition(); // beginning of next record
}
IOUtils.closeStream(reader);输出内容如下:
[128] 100 One, two, buckle my shoe
[173] 99 Three, four, shut the door
[220] 98 Five, six, pick up sticks
[264] 97 Seven, eight, lay them straight
[314] 96 Nine, ten, a big fat hen
[359] 95 One, two, buckle my shoe
[404] 94 Three, four, shut the door
[451] 93 Five, six, pick up sticks
[495] 92 Seven, eight, lay them straight
[545] 91 Nine, ten, a big fat hen
[590] 90 One, two, buckle my shoe
[635] 89 Three, four, shut the door
[682] 88 Five, six, pick up sticks
[726] 87 Seven, eight, lay them straight
[776] 86 Nine, ten, a big fat hen
[821] 85 One, two, buckle my shoe
[866] 84 Three, four, shut the door
[913] 83 Five, six, pick up sticks
[957] 82 Seven, eight, lay them straight
[1007] 81 Nine, ten, a big fat hen
The SequenceFile format
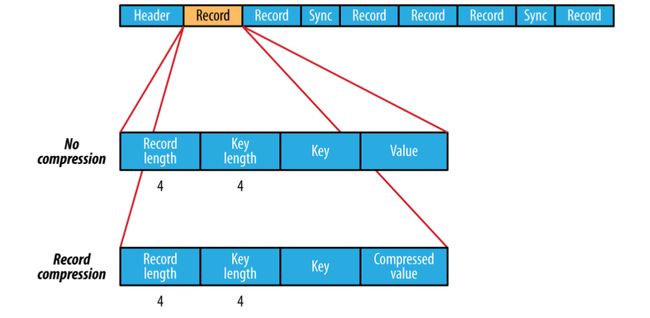
一个SequenceFile是由一个head和 一条或者多条record组成。
SequenceFile头三个字节是SEQ ,用数字表示;其后是version number,如下图,Header也包括其他字段,key/value class,compress等信息。Sync 标志是否允许用户从文件的任何position同步的读取记录。

SequenceFile 的record的格式化依赖于 是否开启压缩,如果压缩,是record compression还是block compression。使用record compression的key不会被压缩。
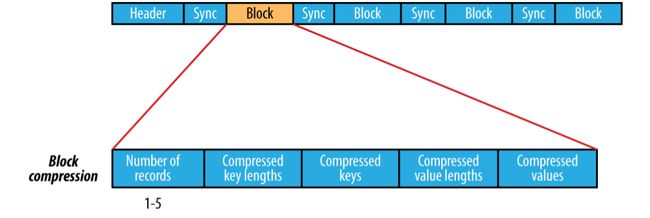
block 压缩的有点是高效,整个块被压缩,而不是在记录层进行压缩。数据直到达到块的大小时才被压缩,在某一点上整个块被压缩,从而形成整体压缩。默认情况下block的大小与HDFS的block的大小相同,可以使用 io.seqfile.compress.blocksize 设置。

使用压缩,只要在write中添加 一行代码就可以,read 代码可以不变
SequenceFile.Writer.Option compression = SequenceFile.Writer.compression(SequenceFile.CompressionType.BLOCK,new DefaultCodec());