RocketMQ-消息发送源码分析(三)消息重试及Broker故障延迟机制
文章目录
- 问题点
- 消息重试
- 消息队列选择
- 默认机制
- Broker故障转移机制
问题点
上篇文章已经介绍了消息发送时,topic的路由信息是如何获取的,最终路由结果是一个TopicPublishInfo对象,其中messageQueueList就是本次消息发送的topic对应的消息队列,再看下TopicPublishInfo属性图加深印象

问题又来了,拿到了消息队列后,就进入到了具体消息队列选择、发送的流程,所以有如下问题
1、消息队列是如何选择的,即producer向哪个消息队列里发送消息?
2、消息发送失败了怎么办(网络原因,broker挂掉)?发送端如何实现的高可用?
具体消息发送的实现在org.apache.rocketmq.client.impl.producer.DefaultMQProducerImpl#sendKernelImpl中,下篇文章再做介绍,本文主要关注于消息发送时的队列选择、重试机制、及Broker故障延迟机制
消息重试
看下获取到了路由信息后的发送代码

可以看到timesTotal(发送次数)在同步模式下被设为1+this.defaultMQProducer.getRetryTimesWhenSendFailed()=3次,异步或者oneway模式为1次
即消息发送失败后,同步模式会重试2次,for循环内部的逻辑代码如下

基本步骤如下
- 选择消息队列
- 发送消息,成功直接返回
- 失败时,若异常为RemotingException、MQClientException,进行重试。若异常为MQBrokerException、InterruptedException,退出循环并抛异常
每个异常处理方法里都调用了一个updateFaultItem更新broker异常信息的方法,这里具体逻辑在broker容错机制里介绍
正常的消息发送失败后,会进行重试发送,这是MQ发送端实现高可用的关键之一
消息队列选择
默认机制
消息队列选择实现在selectOneMessageQueue中,最终调用的是org.apache.rocketmq.client.latency.MQFaultStrategy#selectOneMessageQueue,看下具体实现
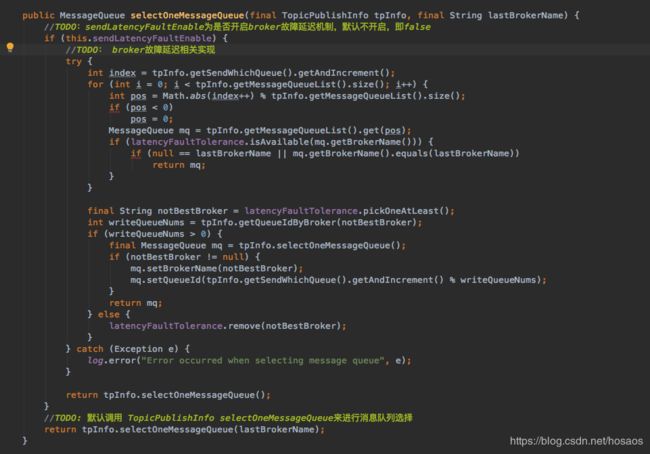
默认是不启用故障延迟机制的,所以走的是默认机制,即调用TopicPublishInfo#selectOneMessageQueue(java.lang.String)来进行队列选择,看下实现

其逻辑比较简单,核心就是每次选择队列,对sendWhichQueue本地线程变量进行+1,然后取模获取对应消息队列,在某次发送失败时,会传入上次发送失败的brokerName,取模时,如果取到的消息队列还是上次发送失败的broker,则重新对sendWhichQueue+1,重新选择消息队列
既然这里有了broker的剔除机制,又为什么要单独设计一个broker故障延迟机制呢?
大家可以想想,在一次消息发送过程中,该方案能够规避上次发送失败的broker,重新对消息队列进行选择。但是如果是N次消息发送呢?N次发送都有可能会选择到故障broker的消息队列。
所以broker故障转移机制能够在一定时间范围内,规避选择到故障的broker
那么如果开启了broker故障转移机制,又是如何做到在一定时间内避免选择到故障broker的消息队列呢?
Broker故障转移机制
回想到Mq在消息发送异常时会调用updateFaultItem来更新broker异常信息,我们以此为切入点来分析故障容错机制,先看下org.apache.rocketmq.client.latency.MQFaultStrategy#updateFaultItem的实现

分为两步
- 根据消息发送时长(currentLatency),计算broker不可用时长(duration),即如果消息发送时间越久,mq会认为broker不可用的时长越久,broker不可用时长是个经验值,如果传入isolation为true,表示默认当前发送时长为30000L,即broker不可用时长为600000L
- 调用latencyFaultTolerance.updateFaultItem更新broker异常容错信息
Broker故障转移机制的关键类LatencyFaultTolerance,其中有四个方法,如图所示

看下updateFaultItem的实现,一个broker对应一个faultItem,faultItem内容包含broker名称、消息发送时长、broker恢复正常的时间startTimestamp

其关键点在于设置startTimestamp(意味broker预计可用的时间),什么意思呢,假设某次消息发送时长为4000毫秒,则mq预计broker的不可用时长为18000L(根据latencyMax数组,notAvailableDuration数组对应关系得到),则broker的预计恢复正常时间为:当前时间+不可用时长,即System.currentTimeMillis() + notAvailableDuration
因此LatencyFaultToleranceImpl#isAvailable判断broker是否预计可用的实现也很清晰了,只要当前时间>startTimestamp,即表示该broker正常了(逻辑意义上的正常,预计broker会在这个时间点后恢复正常)

在回到org.apache.rocketmq.client.latency.MQFaultStrategy#selectOneMessageQueue中,看下开启容错机制后的实现

现在整理下broker容错机制的思路及实现步骤
- 在消息发送失败,mq根据消息发送耗时来预测该broker不可用的时长,并将broker名称,及”预计恢复时长“,存储于ConcurrentHashMap
- 在开启消息容错后,选择消息队列时,会根据当前时间与FaultItem中该broker的预计恢复时间做比较,若(System.currentTimeMillis() - startTimestamp) >= 0,则预计该broker恢复正常,选择该broker的消息队列
- 若所有的broker都预计不可用,随机选择一个不可用的broker,从路由信息中选择下一个消息队列,重置其brokerName,queueId,进行消息发送
介绍到这里,再回顾下开头提出的两个问题,可以一并回答
1、消息队列是如何选择的,即producer向哪个消息队列里发送消息?
2、消息发送失败了怎么办(网络原因,broker挂掉)?发送端如何实现的高可用?
在默认队列选择机制下,会随机选择一个MessageQueue,若发送失败,轮询队列重新进行重试发送(屏蔽单次发送中不可用的broker),同步模式下默认失败时重试发送2次
在开启容错机制后,消息队列选择时,会在一段时间内过滤掉mq认为不可用的broker,以此来避免不断向宕机的broker发送消息,从而实现消息发送高可用