TensorRT使用笔记
一、简介
1.官网
https://docs.nvidia.com/deeplearning/sdk/tensorrt-install-guide/index.html
NVIDIA TensorRT是一个C ++库,可以促进NVIDIA GPU的高性能推断。
TensorRT专注于在GPU上快速有效地运行已经训练过的网络,并生成高度优化的运行时引擎,对该网络进行推理。
TensorRT通过C ++和Python提供API,通过 API或解析器加载预定义模型。
TensorRT允许在NVIDIA GPU上优化和运行模型。
TensorRT提供了一个runtime,可在开普勒一代以上的所有NVIDIA GPU上执行此网络。
2.网上博客
《高性能深度学习支持引擎实战——TensorRT》:https://yq.aliyun.com/articles/580307
TensorRT项目立项的时候名字叫做GPU Inference Engine(简称GIE),Tensor表示数据流动以张量的形式。
所谓张量大家可以理解为更加复杂的高维数组,一般一维数组叫做Vector(即向量),二维数组叫做Matrix,再高纬度的就叫Tensor,Matrix其实是二维的Tensor。
在TensoRT中,所有的数据都被组成最高四维的数组,如果对应到CNN中其实就是{N, C, H, W},N表示batch size,即多少张图片或者多少个推断(Inference)的实例;C表示channel数目;H和W表示图像或feature maps的高度和宽度。
TR表示的是Runtime。
2.1 深度学习分为训练和部署两部分。
训练部分首先也是最重要的是构建网络结构,准备数据集,使用各种框架进行训练,训练要包含validation和test的过程。在线下有大规模的集群开始对数据或模型进行更新,这样的训练需要消耗大量的GPU,相对而言一般会给一个比较大的batchsize,因为它的实时性要求相对较低,一般训练模型给的是128,甚至有些极端的1024,大的batch的好处是可以充分的利用GPU设备。
但是到推断(Inference)的时候就是不同的概念了,推断(Inference)的时候只需要做一个前向计算,将输入通过神经网络得出预测的结果。而推断(Inference)的实际部署有多种可能,可能部署在Data Center(云端数据中心),还可能部署在嵌入端,对实时性要求很高。
训练(Training)这个阶段如果模型比较慢,其实是一个砸钱可以解决的问题,我们可以用更大的集群、更多的机器,做更大的数据并行甚至是模型并行来训练它,重要的是成本的投入。
而部署端不只是成本的问题,如果方法不得当,即使使用目前最先进的GPU,也无法满足推断(Inference)的实时性要求。因为模型如果做得不好,没有做优化,可能需要二三百毫秒才能做完一次推断(Inference),再加上来回的网络传输,用户可能一秒后才能得到结果。在语音识别的场景之下,用户可以等待;但是在驾驶的场景之下,可能会有性命之庾。
在部署阶段,latency是非常重要的点,而TensorRT是专门针对部署端进行优化的,目前TensorRT支持大部分主流的深度学习应用,当然最擅长的是CNN(卷积神经网络)领域,但是的TensorRT 3.0也是有RNN的API,也就是说我们可以在里面做RNN的推断(Inference)。
总结一下推断(Inference)和训练(Training)的不同:
- 1.推断(Inference)的网络权值已经固定下来,无后向传播过程,因此可以
1)模型固定,可以对计算图进行优化
2)输入输出大小固定,可以做memory优化 - 2.推断(Inference)的batch size要小很多。
- 3.推断(Inference)可以使用低精度的技术,研究结果表明没有特别大的精度损失,尤其对CNN。
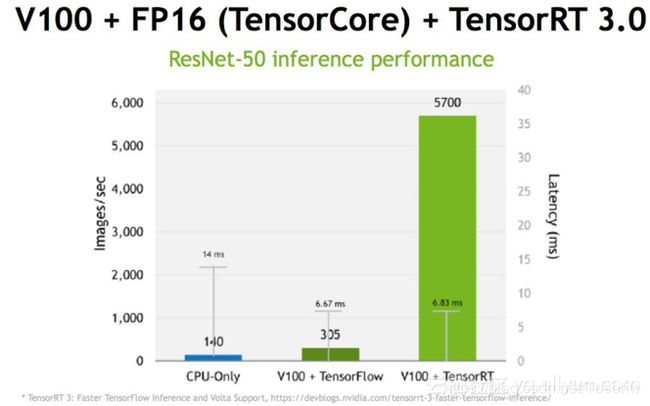
在训练过程中可以使用不同的框架,为什么推断(Inference)不能用各种框架?
当然是可以用的,但是问题是灵活性和性能是一种trade-off权衡的关系,这是在做深度学习或训练过程中经常会遇到的一个问题。比如像TensorFlow的设计初衷是为各种各样的操作来做准备的,在早期的框架,例如Caffe中很多前后处理并不在框架里面完成,而是通过额外的程序或脚本处理,但是TensorFlow支持将所有的操作放入框架之中来完成,它提供了操作(Operation)级别的支持,使得灵活性大大提高,但是灵活性可能是以牺牲效率为代价的。TensorFlow在实现神经网络的过程中可以选择各种各样的高级库,但是其对计算图和GPU都没有做优化,甚至在中间卷积算法的选择上也没有做优化,而TensorRT在这方面做了很多工作。
2.2 TensorRT的流程?
TensorRT整个过程可以分三个步骤,即模型的解析(Parser),Engine优化和执行(Execution)。
2.2.1 模型的解析(Parser)
目前TensorRT支持两种输入方式:
- 一种是Parser的方式。Parser是模型解析器,输入一个caffe的模型或者TensorFlow转换成的uff模型,可以解析出其中的网络层及网络层之间的连接关系,然后将其输入到TensorRT中。
- API接口可以添加一个convolution或pooling。将Parser解析出来的模型文件,使用API添加到TensorRT中构建网络。
Parser目前有三个:
- 一个是caffe Parser,这个是最古老的也是支持最完善的;
- 另一个是uff,这个是NV定义的网络模型的一种文件结构,现在TensorFlow可以直接转成uff;
- 另外下一个版本3.5或4.0会支持的onnx。
目前API支持两种接口实现方式:
- C++
- Python
如果有一个网络层不支持?
这个有可能,TensorRT只支持主流的操作,比如说一个神经网络专家开发了一个新的网络层,TensorRT是不知道是做什么的。这个时候涉及到customer layer的功能,即用户自定义层,构建用户自定义层需要告诉TensorRT该层的连接关系和实现方式,这样TensorRT才能去做。
2.2.2 engine优化
模型解析后,engine会进行优化,得到优化好的engine可以序列化到内存(buffer)或文件(file),读的时候需要反序列化,将其变成engine以供使用。然后在执行的时候创建context,主要是分配预先的资源,engine加context就可以做推断(Inference)。
TensorRT所做的优化?
第一,也是最重要的,它把一些网络层进行了合并。
第二,取消不需要的层,比如concat这一层。
第三,Kernel可以自动选择最合适的算法。
第四,不同的batch size会做tuning。
第五,对硬件做优化。
2.3 总结TensorRT的优点
- TensorRT是一个高性能的深度学习推断(Inference)的优化器和运行的引擎;
- TensorRT支持Plugin,对于不支持的层,用户可以通过Plugin来支持自定义创建;
- TensorRT使用低精度的技术获得相对于FP32二到三倍的加速,用户只需要通过相应的代码来实现。
二、安装
下载(需要登录):https://developer.nvidia.com/tensorrt
我下载的是:TensorRT 5.1.5.0 GA for Ubuntu 16.04 and CUDA 9.0 tar package
首先确认安装以下依赖项:
- 安装CUDA Toolkit 9.0,10.0或10.1
- cuDNN 7.5.0
- Python 2或Python 3(可选)
解压并进入目录:
# 添加环境变量到文件中:
$ gedit ~/.bashrc
# 在末行增加:
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/home/toson/soft/TensorRT-5.1.5.0/lib
安装 Python TensorRT whell 文件:
$ cd ~/soft/TensorRT-5.1.5.0/python/
$ sudo pip2 install tensorrt-5.1.5.0-cp27-none-linux_x86_64.whl
#$ sudo pip3 install tensorrt-5.1.x.x-cp3x-none-linux_x86_64.whl
安装Python UFF wheel文件:
只有在计划将 TensorRT 与 TensorFlow 一起使用时才需要这样做
$ cd ~/soft/TensorRT-5.1.5.0/uff/
$ sudo pip2 install uff-0.6.3-py2.py3-none-any.whl
#$ sudo pip3 install uff-0.6.3-py2.py3-none-any.whl
# 在任一情况下:
$ which convert-to-uff
/usr/local/bin/convert-to-uff
安装Python graphsurgeon wheel文件:
$ cd ~/soft/TensorRT-5.1.5.0/graphsurgeon
$ sudo pip2 install graphsurgeon-0.4.1-py2.py3-none-any.whl
#$ sudo pip3 install graphsurgeon-0.4.1-py2.py3-none-any.whl
验证安装:
- Ensure that the installed files are located in the correct directories. For example, run the
tree -dcommand to check whether all supported installed files are in place in thelib, include, data, etc… directories. - Build and run one of the shipped samples, for example,
sampleMNISTin the installed directory. You should be able to compile and execute the sample without additional settings. For more information about sampleMNSIT, see the"Hello World" For TensorRTsample.(https://docs.nvidia.com/deeplearning/sdk/tensorrt-sample-support-guide/index.html#mnist_sample) - The Python samples are in the
samples/pythondirectory.