文本分类
应用:垃圾邮件分类、主题分类、情感分析
workflow:

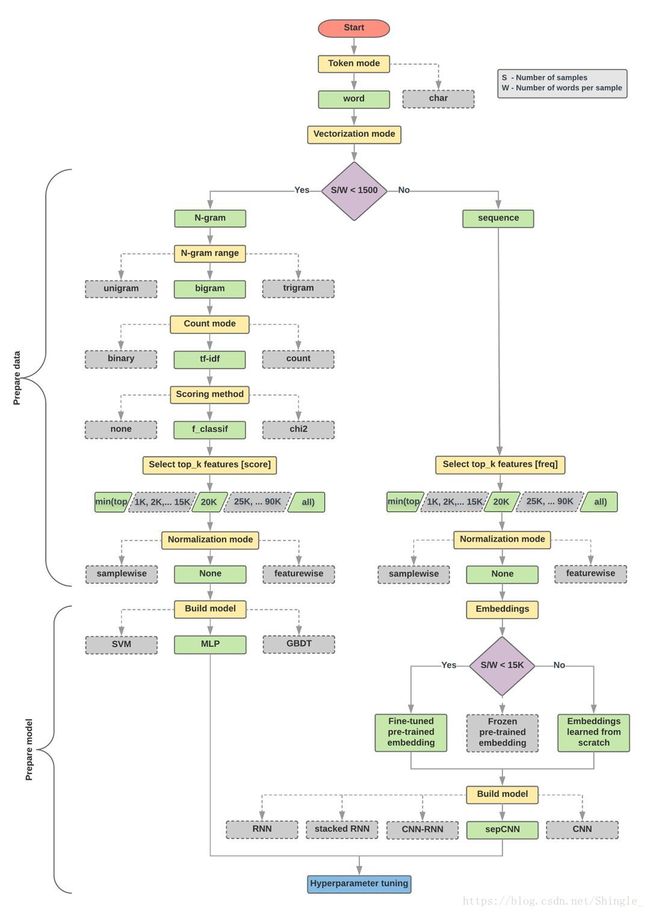
https://developers.google.com/machine-learning/guides/text-classification/
model
- 使用字符级 ngram 的词袋模型很有效。不要低估词袋模型,它计算成本低且易于解释。
- RNN 很强大。但你也可以用 GloVe 这样的外部预训练嵌入套在 RNN 模型上。当然也可以用 word2vec 和 FastText 等其他常见嵌入。
- CNN 也可以应用于文本。CNN 的主要优势在于训练速度很快。此外,对 NLP 任务而言,CNN 从文本中提取局部特征的能力也很有趣。
- RNN 和 CNN 可以堆叠在一起,可以同时利用这两种结构。
LSTM Networks for Text Classification

class BiRNN(nn.Block):
def __init__(self, vocab, embed_size, num_hiddens, num_layers, **kwargs):
super(BiRNN, self).__init__(**kwargs)
self.embedding = nn.Embedding(len(vocab), embed_size)
self.encoder = rnn.LSTM(num_hiddens, num_layers=num_layers,
bidirectional=True, input_size=embed_size)
self.decoder = nn.Dense(2)
def forward(self, inputs):
# inputs 形状是(批量大小,词数),因为 LSTM 需要将序列作为第一维,
# 所以将输入转置后再提取词特征,输出形状为(词数,批量大小,词向量长度)。
embeddings = self.embedding(inputs.T)
# states 形状是(词数,批量大小,2* 隐藏单元个数)。
states = self.encoder(embeddings)
# 连结初始时间步和最终时间步的隐藏状态作为全连接层输入。
# 它的形状为(批量大小,2* 隐藏单元个数)。
encoding = nd.concat(states[0], states[-1])
outputs = self.decoder(encoding)
return outputs
这边的LSTM是双向的,把每个h的h_0和h_1的结果contact作为最后的h输出。初始的包括反向rnn对句子的编码信息,最终的包括正向rnn对句子的编码信息。
http://deeplearning.net/tutorial/lstm.html#lstm
https://zh.gluon.ai/chapter_natural-language-processing/sentiment-analysis.html
TextCNN
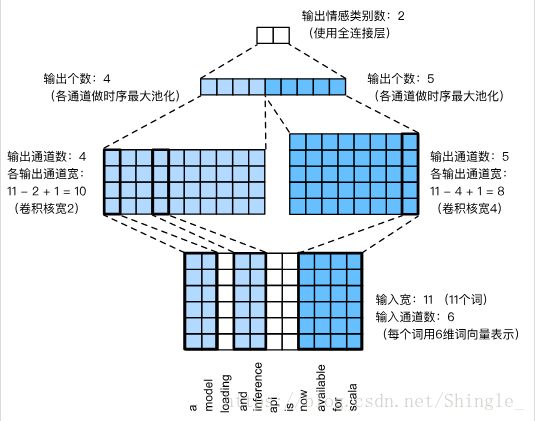
class TextCNN(nn.Block):
def __init__(self, vocab, embed_size, kernel_sizes, num_channels,
**kwargs):
super(TextCNN, self).__init__(**kwargs)
self.embedding = nn.Embedding(len(vocab), embed_size)
# 不参与训练的嵌入层。
self.constant_embedding = nn.Embedding(len(vocab), embed_size)
self.dropout = nn.Dropout(0.5)
self.decoder = nn.Dense(2)
# 时序最大池化层没有权重,所以可以共用一个实例。
self.pool = nn.GlobalMaxPool1D()
self.convs = nn.Sequential() # 创建多个一维卷积层。
for c, k in zip(num_channels, kernel_sizes):
self.convs.add(nn.Conv1D(c, k, activation='relu'))
def forward(self, inputs):
# 将两个嵌入层的输出,其形状是(批量大小,词数,词向量维度),在上连结。
embeddings = nd.concat(
self.embedding(inputs), self.constant_embedding(inputs), dim=2)
# 然后将词向量维度,这是一维卷积层的通道维,调整到第二维。
embeddings = embeddings.transpose((0, 2, 1))
# 对于第 i 个一维卷积层,在时序最大池化后会得到一个形状为(批量大小,通道大小,1)
# 的矩阵。使用 flatten 函数去掉最后一个维度,然后在通道维上连结。
encoding = nd.concat(*[nd.flatten(
self.pool(conv(embeddings))) for conv in self.convs], dim=1)
# 作用丢弃层后使用全连接层得到输出。
outputs = self.decoder(self.dropout(encoding))
return outputs
https://zh.gluon.ai/chapter_natural-language-processing/sentiment-analysis-cnn.html
改进点:
- 把迭代周期改大。你的模型能在训练和测试数据集上得到怎样的准确率?通过调节超参数,你能进一步提升分类准确率吗?
- 使用更大的预训练词向量,例如 300 维的 GloVe 词向量
- 使用 spaCy 分词工具,能否提升分类准确率?。你需要安装 spaCy:pip install spacy,并且安装英文包:python -m spacy download en。在代码中,先导入 spacy:import spacy。然后加载 spacy 英文包:spacy_en = spacy.load(‘en’)。最后定义函数:def tokenizer(text): return [tok.text for tok in spacy_en.tokenizer(text)]替换原来的基于空格分词的tokenizer函数。需要注意的是,GloVe 的词向量对于名词词组的存储方式是用“-”连接各个单词,例如词组“new york”在 GloVe 中的表示为“new-york”。而使用 spacy 分词之后“new york”的存储可能是“new york”。
Recurrent + Convolutional neural network
https://ahmedbesbes.com/sentiment-analysis-on-twitter-using-word2vec-and-keras.html
https://ahmedbesbes.com/overview-and-benchmark-of-traditional-and-deep-learning-models-in-text-classification.html
Attention Model
https://richliao.github.io/supervised/classification/2016/12/26/textclassifier-HATN/