Yolo算法v1-v3介绍
YoloV1
一. Yolo的核心思想就是把整张图作为网络的输入, 直接在输出层回归bounding box的位置及其类别.
二. 实现方法:
- 将图像分成S*S个网格, 每个网格预测B个bounding box, 每个bounding box输出5个值, 包括p, x, y, w, h
- 每个网格还需要输出C个类别概率. 所以给定一张图片, 网络输出维度为S * S * (5*B+C). 例如在PASCAL VOC中, 图像输入为448 * 448, S=7, B=2, 20个类别, 于是输出为7 * 7 * 30.
- 网络结构:

网络基本结构为GoogleNet, 只是去掉了Inception模块用1 * 1 + 3 * 3 的卷积结构替代(简化). 最后把GoogleNet的classifier output用4个卷积层和2个全连接层替换掉, 得到想要的输出维度. 因为使用了全连接层, 预测图片必须和训练图片分辨率一致. - 损失函数:
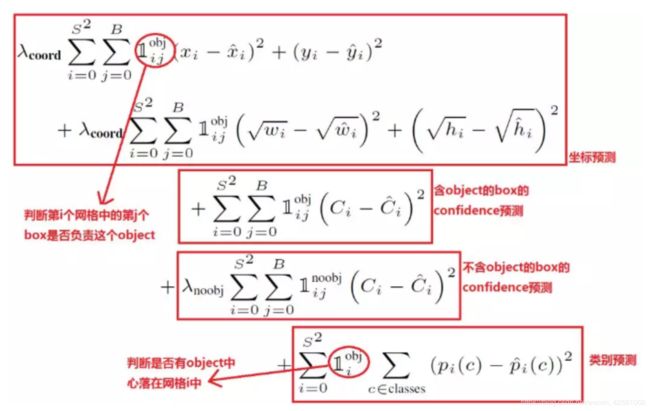
训练的时候, 分三个部分计算损失, 包括"坐标损失", “IOU损失"和"类别损失”.
坐标损失: 只计算label中有物体的格子所对应的box.
用label中的坐标x,y, w, h与predict得到的box的x',y', w', h'做平方和损失.
其余没有物体的格子中的box坐标不计入损失函数中.
x, y, w, h都归一化到0-1之间.
应该更重视坐标预测, 所以坐标损失赋予更大的权重, 5.
注意: 坐标损失中, w和h的计算取了根号, 原因是相等的误差值, 对大物体的影响应该小于对小物体的影响. 根据平方根函数(如下图)来看, 取平方根能一定程度缓解这个问题(仍然没有解决).

IOU损失: 计入损失函数的目的是为了优化所有box的p值(置信度).
对于有物体的格子, 它的box中的p值应该尽可能的大, 此时把IOU作为p值, 就是希望p尽可能等于1, 表示predict的坐标与label的坐标尽可能重合.
对于没有物体的格子, 它的box中的p值应该尽可能等于0, 方便后续根据p值把这些box过滤掉.
同时, 因为没有物体的格子更多, 数据不平衡, 所以对这些box设置权重为0.5, 减弱每个box的影响.
类别损失: 关注有物体的格子做的分类预测是否准确, 把分类误差计入损失中.
-
训练过程:
a. 先用ImageNet预训练: Yolo的前20个卷积层 + 1个average池化层 + 1个全连接层做分类. 图像分辨率为224 * 224.
b. 前20个卷积层得到了初始化, 然后接上4个卷积层 + 2个全连接层得到检测模型. 在Pascal Voc上用448 * 448的图片训练检测模型. -
预测:
预测的时候, 对网络得到的所有box, 先把p小于0.5(阈值, 可调节)的box先去掉, 然后对剩下的box, 用非极大值抑制法(NMS)筛选得到最终的结果. -
Yolo的优点:
a. 快: 高准确率下的实时检测.
b. 背景误检率低. 因为Yolo能看到全局图像, 而基于region的rcnn/fast rcnn等只能看到局部图像. -
Yolo的缺点:
a. 对相互靠近的物体以及小物体的检测效果不好, 因为一个格子只能检测一个物体, 并且算loss的时候即使对w和h开了根号, 小物体的位置偏差仍然对loss贡献不大, 因此没有做到很好的优化.
b. 泛化能力弱, 对于非常见形状的物体检测效果不好.
YoloV2
YoloV2的目标是提高定位的准确度, 以及改善recall(召回率/查全率).
改进之处有:
更好
-
Batch Normalization: 卷积层全部使用Batch Normalization, 同时取消Dropout.
-
高分辨率分类器: V1中用224 * 224的图片来训练分类器网络, 然后用448 * 448的图像来微调检测网络. V2除了224 * 224的图像, 还用了448 * 448的图像来微调分类器网络, 让filter有时间来调整.
-
借鉴Faster R-CNN的思想, 采用anchor box(先验), 让模型预测box的偏移, 而不是直接预测坐标, 这样简化了问题让模型更容易学习.
-
采用K-Means来生成anchor box, 而不是像Faster-RCNN手动标注, 并证明这样更好. K取5时, 模型在复杂度和准确率间取得平衡.
-
细粒度特征: 添加一个passthrough层, 将上一层(26 * 26)的特征图叠加到最后一层(13 * 13)的特征图上, 使检测器能学到更细粒度的特征.
-
多尺度训练: 因为是全卷积网络, 输入图像尺寸可以变化. 每10个batch改变一次图像尺寸进行训练, 让网络更健壮.

更快
- 自定义的新的分类网络: DarkNet-19, 效果更好
更强
- 定义了新的联合训练方法, 使用WordTree, 让模型能够同时使用目标检测数据集和分类数据集进行训练, 并且分类目标达到9000个, 采用联合训练方法的算法叫Yolo9000.
YoloV3
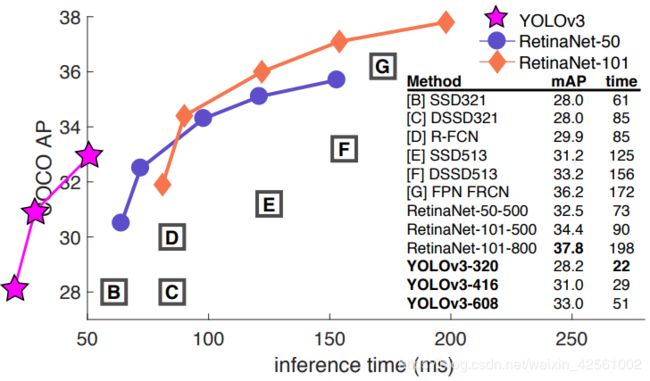
改进之处:
- 更好的分类器(independent logistic classifier)
不再使用Softmax对每个格子进行分类, 而是使用多个独立的 logistic 分类器.
原因是Softmax使得每个格子只能有一个类别, 对于有物体重叠的数据不适用.
- 多尺度预测
与YoloV2的多尺度不同, V3的多尺度是指同一张图片在卷积后得到的不同尺度上做预测. 即:
使用聚类k=9得到9个anchor box, 按照大小分到3个尺度:
尺度1: 在基础网络之后添加一些卷积层再输出box信息
尺度2: 从尺度1中的倒数第二层的卷积层上采样(x2)再与最后一个 16x16 大小的特征图相加,再次通过多个卷积后输出 box 信息,相比尺度1变大两倍.
尺度3: 与尺度2类似,使用了 32x32 大小的特征图

3. 更好的基础分类网络(DarkNet-53)
DarkNet-53与ResNet-101或ResNet-152准确率接近, 但速度更快.
总结
- YoloV3对小物体的检测能力得到了提高.
- Yolo算法最重要的优点还是保证一定准确率的同时, 速度快.
- 对检测速度要求高的场景下, 可以使用Yolo系列或者MobileNet, Yolo是在算力足够的前提下, 速度快, 移动端适合MobileNet, 算力要求小, 速度相对快.
- 如果不要求检测速度, 算力足够, 可以考虑Mask-RCNN, 准确率目前来说最高.