面试题基础题解答
1、为什么学习Python?
语言本身简洁,优美,功能超级强大
跨平台
非常火爆的社区
很多有名的大公司在用
2、通过什么途径学习的Python?
培训机构 + 自学
3、Python和Java、PHP、C、C#、C++等其他语言的对比?
C,它是现代编程语言的祖师爷,所以非常古老了,在现代应用中使用不多。但由于C是祖师爷,所以绝大部分语言,写法都和C语言差不多。。。常常用作学习其他语言的基础。。而C语言也有其他语言不可替代的用途,现在最主要的应用就是单片机。。。单片机是啥?就是用C语言控制一些简单的电子元件。。。比如电视用的遥控器,其实就是一个单片机。
PHP是用来做网站的,其实从技术角度,属于第一代的后端技术(植入式脚本技术),现在最新的后端技术,已经发展到第三代了(MVC架构),因此从技术上讲,PHP早该过时了,但由于市场需求的存在,所以它依然是做网站后台的主流之一。。就类似于WindowsXP一样,技术上太淘汰了,但市场却依然是主流,普及度依然很高。缺点一大堆,但又个最主要的优势,就是简单。。。MVC虽好,但学习难度远比PHP要高的多。
C++是面向对象的C语言,由于偏底层,所以性能非常高,仅次于C语言,主要用在一个要求高性能的领域。。。这个不好说,因为实际需求上,用处挺杂的,而且也确实不太好学。。因为它把C语言面向过程的那套东西,和JAVA面向对象的那些东西,堆砌到了一起。。也就同时把两种完全不同的思想揉在了一起。。个人的理解是,它就像周星驰电影里的那个“要你命3000”,把苍蝇拍,杀虫剂,手枪,手榴弹,灭鼠灵,用一根麻绳串在一起。。。杀虫可以,灭鼠可以,杀人也可以,堪称无所不能。。。但用起来,真是麻烦死了。。所以对于很多人来说,认可它的地位,承认它的功能,但敬而远之。
JAVA是今天真正意义上的大道正宗,名门正派。。。。丐帮有降龙十八掌,华山派有独孤九剑。。但你却很难说出,少林派有什么武功特别强。。而它又是公认的名门正宗。。。这其实就已经说明问题了,JAVA没有什么特别强的方面,但每个方面都不弱。。整体平均值,便非常高。。JAVA还有一个比较突出的优势,就是它是安卓系统的官方开发语言。。既然说到了少林,就不得不提一下武当。。。那就是微软的官方语言C#。。。.C#和JAVA相比,其实80%都是一样的。。几乎等于学一门,会两门,C#比JAVA稍微简单一些,IDE也好一些,其实比JAVA更适合新手,但由于之前不能跨平台,所以流行度比JAVA低,但确是游戏开发行业的第一大语言。。JAVA与C#基本可以看成一门语言的两种方言。。英式英语和美式英语的差别一样。。说到底还是半斤八两。。。一个是传统应用和安卓系统的第一大语言,一个是WINDOWS系统和游戏开发的第一大语言。。而且学一门会两门,你还要求啥?
Python也是个很有历史的语言,诞生时间和JAVA,C#差不多,但今天却依然非常时髦。。因为它的语法,简洁,优雅,风骚到了极致。。像写信一样写代码。。而又无所不能,JAVA和C#能做到的,Python几乎一样都不少。。。简单易学,尤其受到初学者喜爱。。但Python更像一把双刃剑,优点特别突出,缺点也特别明显,就是特别慢。。。一般认为,Python比JAVA慢25倍到50倍。。还有一门语言叫Ruby,和Python相似,也是语法特别简洁。。但比Python更慢,用途也不如Python。。。基本可以看作华山,丐帮,在某些情况下,可以胜过少林武当。。但整体上比较,还是要差一截。。但即便如此,它的前景也是非常好的。。由于语法简单,更容易被机器解析,所以在人工智能领域非常有前途。比如那个下围棋的Alpha Go,以及中国的北斗卫星定位系统。。都有大量的Python代码在里面。
4、简述解释型和编译型编程语言?
编译型语言:把做好的源程序全部编译成二进制代码的可运行程序。然后,可直接运行这个程序。
解释型语言:把做好的源程序翻译一句,然后执行一句,直至结束!python是一门解释型语言
5:Python解释器种类以及特点?
Python是一门解释器语言,代码想运行,必须通过解释器执行,Python存在多种解释器,分别基于不同语言开发,每个解释器有不同的特点,但都能正常运行Python代码,以下是常用的五种Python解释器:
CPython
当 从Python官方网站下载并安装好Python2.7后,就直接获得了一个官方版本的解释器:Cpython,这个解释器是用C语言开发的,所以叫 CPython,在命名行下运行python,就是启动CPython解释器,CPython是使用最广的Python解释器。
IPython
IPython是基于CPython之上的一个交互式解释器,也就是说,IPython只是在交互方式上有所增强,但是执行Python代码的功能和CPython是完全一样的,好比很多国产浏览器虽然外观不同,但内核其实是调用了IE。
PyPy
PyPy是另一个Python解释器,它的目标是执行速度,PyPy采用JIT技术,对Python代码进行动态编译,所以可以显著提高Python代码的执行速度。
Jython
Jython是运行在Java平台上的Python解释器,可以直接把Python代码编译成Java字节码执行。
IronPython
IronPython和Jython类似,只不过IronPython是运行在微软.Net平台上的Python解释器,可以直接把Python代码编译成.Net的字节码。
在Python的解释器中,使用广泛的是CPython,对于Python的编译,除了可以采用以上解释器进行编译外,技术高超的开发者还可以按照自己的需求自行编写Python解释器来执行Python代码,十分的方便!
6:位和字节的关系?
1、位(bit)
来自英文bit,音译为“比特”,表示二进制位。位是计算机内部数据储存的最小单位,11010100是一个8位二进制数。一个二进制位只可以表示0和1两种状态(21);两个二进制位可以表示00、01、10、11四种(22)状态;三位二进制数可表示八种状态(23)……。
2、字节(byte)
字节来自英文byte,音译为“拜特”,习惯上用大写的“b”表示。
字节是计算机中数据处理的基本单位。计算机中以字节为单位存储和解释信息,规定一个字节由八个二进制位构成,即1个字节等于8个比特(1byte=8bit)。八位二进制数最小为00000000,最大为11111111;通常1个字节可以存入一个ascii码,2个字节可以存放一个汉字国标码。
3、字
计算机进行数据处理时,一次存取、加工和传送的数据长度称为字(word)。一个字通常由一个或多个(一般是字节的整数位)字节构成。例如286微机的字由2个字节组成,它的字长为16;486微机的字由4个字节组成,它的字长为32位机。
计算机的字长决定了其cpu一次操作处理实际位数的多少,由此可见计算机的字长越大,其性能越优越。
7 :b、B、KB、MB、GB 的关系?
b ,B,KB,MB,GB之间的关系
utf-8种一个字母或者 数字等于一个字节 , 一个汉字等于3个字节,表情等于4个字节
b 比特bit / 位
B——字节
KB——千比特
MB——兆比特
GB——吉比特
1 B = 8b (8个bit/ 位) 一个字节(byte)等于8位(bit)
1 kB = 1024 B (kB - kilobajt)
1 MB = 1024 kB (MB - megabajt)
1 GB = 1024 MB (GB - gigabajt)
英文和数字占一个字节
中文占一个字符,也就是两个字节
字符 不等于 字节。
字符(char)是 Java 中的一种基本数据类型,由 2 个字节组成,范围从 0 开始,到 2^16-1。
字节是一种数据量的单位,一个字节等于 8 位。所有的数据所占空间都可以用字节数来衡量。例如一个字符占 2 个字节,一个 int 占 4 个字节,一个 double 占 8 个字节 等等。
1字符=2字节;
1Byte=8bit
1k=2^10;b:位;B:字节1kb=1024 位1kB=1024 字节
8:请至少列举5个 PEP8 规范(越多越好)
pep8规范
pep8规范 官方文档:https://www.python.org/dev/peps/pep-0008/
PEP8中文翻译:http://www.cnblogs.com/ajianbeyourself/p/4377933.html
一 代码编排
1 缩进。4个空格的缩进(编辑器都可以完成此功能),不使用Tap,更不能混合使用Tap和空格。
2 每行最大长度79,换行可以使用反斜杠,最好使用圆括号。换行点要在操作符的后边敲回车。
3 类和top-level函数定义之间空两行;类中的方法定义之间空一行;函数内逻辑无关段落之间空一行;其他地方尽量不要再空行。
二 文档编排
1 模块内容的顺序:模块说明和docstring—import—globals&constants—其他定义。其中import部分,又按标准、三方和自己编写顺序依次排放,之间空一行。
2 不要在一句import中多个库,比如import os, sys不推荐。
3 如果采用from XX import XX引用库,可以省略‘module.’,都是可能出现命名冲突,这时就要采用import XX。
三 空格的使用
总体原则,避免不必要的空格。
1 各种右括号前不要加空格。
2 逗号、冒号、分号前不要加空格。
3 函数的左括号前不要加空格。如Func(1)。
4 序列的左括号前不要加空格。如list[2]。
5 操作符左右各加一个空格,不要为了对齐增加空格。
6 函数默认参数使用的赋值符左右省略空格。
7 不要将多句语句写在同一行,尽管使用‘;’允许。
8 if/for/while语句中,即使执行语句只有一句,也必须另起一行。
四 注释
总体原则,错误的注释不如没有注释。所以当一段代码发生变化时,第一件事就是要修改注释!
注释必须使用英文,最好是完整的句子,首字母大写,句后要有结束符,结束符后跟两个空格,开始下一句。如果是短语,可以省略结束符。
1 块注释,在一段代码前增加的注释。在‘#’后加一空格。段落之间以只有‘#’的行间隔。比如:
# Description : Module config.
#
# Input : None
#
# Output : None
2 行注释,在一句代码后加注释。比如:x = x + 1 # Increment x
但是这种方式尽量少使用。
3 避免无谓的注释。
五 文档描述
1 为所有的共有模块、函数、类、方法写docstrings;非共有的没有必要,但是可以写注释(在def的下一行)。
2 如果docstring要换行,参考如下例子,详见PEP 257
"""Return a foobang
Optional plotz says to frobnicate the bizbaz first.
"""
六 命名规范
总体原则,新编代码必须按下面命名风格进行,现有库的编码尽量保持风格。
1 尽量单独使用小写字母‘l’,大写字母‘O’等容易混淆的字母。
2 模块命名尽量短小,使用全部小写的方式,可以使用下划线。
3 包命名尽量短小,使用全部小写的方式,不可以使用下划线。
4 类的命名使用CapWords的方式,模块内部使用的类采用_CapWords的方式。
5 异常命名使用CapWords+Error后缀的方式。
6 全局变量尽量只在模块内有效,类似C语言中的static。实现方法有两种,一是__all__机制;二是前缀一个下划线。
7 函数命名使用全部小写的方式,可以使用下划线。
8 常量命名使用全部大写的方式,可以使用下划线。
9 类的属性(方法和变量)命名使用全部小写的方式,可以使用下划线。
9 类的属性有3种作用域public、non-public和subclass API,可以理解成C++中的public、private、protected,non-public属性前,前缀一条下划线。
11 类的属性若与关键字名字冲突,后缀一下划线,尽量不要使用缩略等其他方式。
12 为避免与子类属性命名冲突,在类的一些属性前,前缀两条下划线。比如:类Foo中声明__a,访问时,只能通过Foo._Foo__a,避免歧义。如果子类也叫Foo,那就无能为力了。
13 类的方法第一个参数必须是cls,而实例方法第一个参数必须是self
七 编码建议
1 编码中考虑到其他python实现的效率等问题,比如运算符‘+’在CPython(Python)中效率很高,都是Jython中却非常低,所以应该采用.join()的方式。
2 尽可能使用‘is’‘is not’取代‘==’,比如if x is not None 要优于if x。
3 使用基于类的异常,每个模块或包都有自己的异常类,此异常类继承自Exception。
4 异常中不要使用裸露的except,except后跟具体的exceptions。
5 异常中try的代码尽可能少。比如:
try:
value = collection[key]
except KeyError:
return key_not_found(key)
else:
return handle_value(value)
要优于
try:
# Too broad!
return handle_value(collection[key])
except KeyError:
# Will also catch KeyError raised by handle_value()
return key_not_found(key)
6 使用startswith() and endswith()代替切片进行序列前缀或后缀的检查。比如:
Yes: if foo.startswith('bar'):优于
No: if foo[:3] == 'bar':
7 使用isinstance()比较对象的类型。比如
Yes: if isinstance(obj, int): 优于
No: if type(obj) is type(1):
8 判断序列空或不空,有如下规则
Yes: if not seq:
if seq:
优于
No: if len(seq)
if not len(seq)
9 字符串不要以空格收尾。
10 二进制数据判断使用 if boolvalue的方式。
9:通过代码实现如下转换:
二进制转换成十进制:v = “0b1111011”
十进制转换成二进制:v = 18
八进制转换成十进制:v = “011”
十进制转换成八进制:v = 30
十六进制转换成十进制:v = “0x12”
十进制转换成十六进制:v = 87
(1)二进制转换成十进制:v = “0b1111011”
#先将其转换为字符串,再使用int函数,指定进制转换为十进制。
print(int("0b1111011",2))
值为123
(2)十进制转换成二进制:v = 18
print("转换为二进制为:", bin(18))
#转换为二进制为: 0b10010
(3)八进制转换成十进制:v = “011”
print(int("011",8))
#9
(4)十进制转换成八进制:v = 30
print("转换为八进制为:", oct(30))
#转换为八进制为: 0o36
(5)十六进制转换成十进制:v = “0x12”
print(int("0x12",16))
#18
(6)十进制转换成十六进制:v = 87
print("转换为十六进制为:", hex(87))
转换为十六进制为: 0x57
10:请编写一个函数实现将IP地址转换成一个整数。
如 10.3.9.12 转换规则为:
10 00001010
3 00000011
9 00001001
12 00001100
再将以上二进制拼接起来计算十进制结果:00001010 00000011 00001001 00001100 = ?
num = bin(10), bin(3), bin(9), bin(12)
def int1():
global num
return num, int(bin(10), 2) + int(bin(3), 2) + int(bin(9), 2) + int(bin(12), 2)
print(int1())
count = 0
for i in num:
count += int(i, 2)
print(count)
11:python递归的最大层数?
def fab(n):
if n == 1:
return 1
else:
return fab(n - 1) + n
print(fab(998))
# 测试完之后为最大998 到了999就超过了最大的递归程度
import sys
sys.setrecursionlimit(100000)
def foo(n):
print(n)
n += 1
foo(n)
if __name__ == '__main__':
foo(1)
#得到的最大数字在3922-3929之间浮动,这个是和计算机有关系的,将数字调到足够大了,已经大于系统堆栈,python已经无法支撑到太大的递归崩了。
12:求结果:
v1 = 1 or 3
v2 = 1 and 3
v3 = 0 and 2 and 1
v4 = 0 and 2 or 1
v5 = 0 and 2 or 1 or 4
v6 = 0 or Flase and 1
print(1 or 3) #1
print(1 and 3) # 3
print(0 and 2 and 1) # 0
print(0 and 2 or 1) #1
print(0 and 2 or 1 or 4) # 1
print(0 or False and 1) # False
print(None or 0) #0
print(True or 0) #Ture
print(None and 0) # None
print(True and 0) # 0
or 第一个为Ture的话就直接打印出第一个对象,如果第一个为False的话直接打印出第二个。
and 第一个为ture 直接打印出来第二个参数,第一个参数为False直接打印出第一个参数 (and连接符 第一个为False 也就不会在 往下面走了)
13:ascii、unicode、utf-8、gbk 区别?
很久很久以前,有一群人,他们决定用8个可以开合的晶体管来组合成不同的状态,以表示世界上的万物。他们看到8个开关状态是好的,于是他们把这称为“字节”。
再后来,他们又做了一些可以处理这些字节的机器,机器开动了,可以用字节来组合出很多状态,状态开始变来变去。他们看到这样是好的,于是它们就这机器称为“计算机”。
开始计算机只在美国用。八位的字节一共可以组合出256(2的8次方)种不同的状态。 他们把其中的编号从0开始的32种状态分别规定了特殊的用途,一但终端、打印机遇上约定好的这些字节被传过来时,就要做一些约定的动作,如:
遇上0×10, 终端就换行;
遇上0×07, 终端就向人们嘟嘟叫;
遇上0x1b, 打印机就打印反白的字,或者终端就用彩色显示字母。
- 1
- 2
- 3
- 4
- 5
- 6
他们看到这样很好,于是就把这些0×20以下的字节状态称为“控制码”。他们又把所有的空 格、标点符号、数字、大小写字母分别用连续的字节状态表示,一直编到了第127号,这样计算机就可以用不同字节来存储英语的文字了。
大家看到这样,都感觉很好,于是大家都把这个方案叫做 ANSI的“Ascii”编码(American Standard Code for Information Interchange,美国信息互换标准代码)。当时世界上所有的计算机都用同样的ASCII方案来保存英文文字。
后来,就像建造巴比伦塔一样,世界各地的都开始使用计算机,但是很多国家用的不是英文,他们的字母里有许多是ASCII里没有的,为了可以在计算机保存他们的文字,他们决定采用 127号之后的空位来表示这些新的字母、符号,还加入了很多画表格时需要用下到的横线、竖线、交叉等形状,一直把序号编到了最后一个状态255。
从128 到255这一页的字符集被称“扩展字符集”。从此之后,贪婪的人类再没有新的状态可以用了,美帝国主义可能没有想到还有第三世界国家的人们也希望可以用到计算机吧!
等中国人们得到计算机时,已经没有可以利用的字节状态来表示汉字,况且有6000多个常用汉字需要保存呢。
但是这难不倒智慧的中国人民,我们不客气地把那些127号之后的奇异符号们直接取消掉, 规定:
一个小于127的字符的意义与原来相同,但两个大于127的字符连在一起时,就表示一个汉字;
前面的一个字节(他称之为高字节)从0xA1用到 0xF7,后面一个字节(低字节)从0xA1到0xFE;
- 1
- 2
- 3
- 4
这样我们就可以组合出大约7000多个简体汉字了。
在这些编码里,我们还把数学符号、罗马希腊的字母、日文的假名们都编进去了,连在 ASCII 里本来就有的数字、标点、字母都统统重新编了两个字节长的编码,这就是常说的“全角”字符。
而原来在127号以下的那些就叫“半角”字符了。
中国人民看到这样很不错,于是就把这种汉字方案叫做 “GB2312”。GB2312 是对 ASCII 的中文扩展。
但是中国的汉字太多了,我们很快就就发现有许多人的人名没有办法在这里打出来,特别是某些很会麻烦别人的国家领导人。
于是我们不得不继续把 GB2312 没有用到的码位找出来老实不客气地用上。
后来还是不够用,于是干脆不再要求低字节一定是127号之后的内码,只要第一个字节是大于127就固定表示这是一个汉字的开始,不管后面跟的是不是扩展字符集里的内容。结果扩展之后的编码方案被称为 GBK 标准,GBK包括了GB2312 的所有内容,同时又增加了近20000个新的汉字(包括繁体字)和符号。
后来少数民族也要用电脑了,于是我们再扩展,又加了几千个新的少数民族的字,GBK扩成了 GB18030。从此之后,中华民族的文化就可以在计算机时代中传承了。
中国的程序员们看到这一系列汉字编码的标准是好的,于是通称他们叫做 “DBCS“(Double Byte Charecter Set 双字节字符集)。
在DBCS系列标准里,最大的特点是两字节长的汉字字符和一字节长的英文字符并存于同一套编码方案里,因此他们写的程序为了支持中文处理,必须要注意字串里的每一个字节的值,如果这个值是大于127的,那么就认为一个双字节字符集里的字符出现了。
那时候凡是受过加持,会编程的计算机僧侣们都要每天念下面这个咒语数百遍: “一个汉字算两个英文字符!一个汉字算两个英文字符……”
因为当时各个国家都像中国这样搞出一套自己的编码标准,结果互相之间谁也不懂谁的编码,谁也不支持别人的编码。
连大陆和台湾这样只相隔了150海里,使用着同一种语言的兄弟地区,也分别采用了不同的 DBCS 编码方案——当时的中国人想让电脑显示汉字,就必须装上一个“汉字系统”,专门用来处理汉字的显示、输入的问题,但是那个台湾的愚昧封建人士写的算命程序就必须加装另一套支持 BIG5 编码的什么“倚天汉字系统”才可以用,装错了字符系统,显示就会乱了套!这怎么办?而且世界民族之林中还有那些一时用不上电脑的穷苦人民,他们的文字又怎么办? 真是计算机的巴比伦塔命题啊!
正在这时,大天使加百列及时出现了——一个叫 ISO (国际标谁化组织)的国际组织决定着手解决这个问题。
他们采用的方法很简单:
废了所有的地区性编码方案,重新搞一个包括了地球上所有文化、所有字母和符号 的编码!
- 1
- 2
他们打算叫它”Universal Multiple-Octet Coded Character Set”,简称 UCS, 俗称 “unicode”。
unicode开始制订时,计算机的存储器容量极大地发展了,空间再也不成为问题了。于是 ISO 就直接规定必须用两个字节,也就是16位来统一表示所有的字符,对于ASCII里的那些“半角”字符,unicode包持其原编码不变,只是将其长度由原来的8位扩展为16位,而其他文化和语言的字符则全部重新统一编码。由于“半角”英文符号只需要用到低8位,所以其高8位永远是0,因此这种大气的方案在保存英文文本时会多浪费一倍的空间。
这时候,从旧社会里走过来的程序员开始发现一个奇怪的现象:他们的strlen函数靠不住了,一个汉字不再是相当于两个字符了,而是一个!是的,从unicode开始,无论是半角的英文字母,还是全角的汉字,它们都是统一的“一个字符”!同时,也都是统一的“两个字节”,请注意“字符”和“字节”两个术语的不同:
“字节”是一个8位的物理存贮单元,
而“字符”则是一个文化相关的符号。
- 1
- 2
- 3
- 4
在unicode中,一个字符就是两个字节。一个汉字算两个英文字符的时代已经快过去了。
unicode同样也不完美,这里就有两个的问题,
一个是,如何才能区别unicode和ascii?计算机怎么知道三个字节表示一个符号,而不是分别表示三个符号呢?
第二个问题是,我们已经知道,英文字母只用一个字节表示就够了,如果unicode统一规定,每个符号用三个或四个字节表示,那么每个英文字母前都必然有二到三个字节是0,这对于存储空间来说是极大的浪费,文本文件的大小会因此大出二三倍,这是难以接受的。
- 1
- 2
- 3
- 4
unicode在很长一段时间内无法推广,直到互联网的出现,为解决unicode如何在网络上传输的问题,于是面向传输的众多 UTF(UCS Transfer Format)标准出现了,顾名思义:
UTF-8就是每次8个位传输数据,
而UTF-16就是每次16个位。
- 1
- 2
- 3
- 4
UTF-8就是在互联网上使用最广的一种unicode的实现方式,这是为传输而设计的编码,并使编码无国界,这样就可以显示全世界上所有文化的字符了。
UTF-8最大的一个特点,就是它是一种变长的编码方式。
它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度,当字符在ASCII码的范围时,就用一个字节表示,保留了ASCII字符一个字节的编码做为它的一部分,(注意的是unicode一个中文字符占2个字节,而UTF-8一个中文字符占3个字节)。
从unicode到uft-8并不是直接的对应,而是要过一些算法和规则来转换。
Unicode符号范围 | UTF-8编码方式
(十六进制) | (二进制)
—————————————————————–
0000 0000-0000 007F | 0xxxxxxx
0000 0080-0000 07FF | 110xxxxx 10xxxxxx
0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx
0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
14:字节码和机器码的区别?
机器码
机器码(machine code),学名机器语言指令,有时也被称为原生码(Native Code),是电脑的CPU可直接解读的数据。
通常意义上来理解的话,机器码就是计算机可以直接执行,并且执行速度最快的代码。
字节码
字节码(Bytecode)是一种包含执行程序、由一序列 op 代码/数据对 组成的二进制文件。字节码是一种中间码,它比机器码更抽象,需要直译器转译后才能成为机器码的中间代码。
15:三元运算规则以及应用场景?
三元运算符
三元运算符就是在赋值变量的时候,可以直接加判断,然后赋值
格式:[on_true] if [expression] else [on_false]
res = 值1 if 条件 else 值2
1.举例说明:
a =1
b = 2
c= a if a>1 else b #如果a大于1的话,c=a,否则c=b
16:列举 Python2和Python3的区别?
1:print语句
python2中print是一个语句,不论想输出什么,直接放到print关键字后面即可。python3里,print()是一个函数,像其他函数一样,print()需要你将要输出的东西作为参数传给它。
2:UNICODE字符串
python2中有两种字符串类型:Unicode字符串和非Unicode字符串。Python3中只有一种类型:Unicode字符串
Python2中使用 ASCII 码作为默认编码方式导致string有两种类型str和unicode,Python3只支持unicode的
3 全局函数UNICODE()
python2有两个全局函数可以把对象强制转换成字符串:unicode()把对象转换成unicode字符串,还有str()把对象转换为非Unicode字符串。Python3只有一种字符串类型,unicode字符串,所以str()函数即可完成所有的功能。
4:LONG长整型
python2有非浮点数准备的int和long类型。int类型最大值不能超过sys.maxint,而且这个最大值是平台相关的。可以通过在数字的末尾附上一个L来定义长整型,显然,它比int类型表示的数字范围更大。在python3里,只有一种整数类型int,大多数情况下,和python2中的长整型类似。
5:<>比较运算符
Python2支持<>作为!=的同义词, python3只支持!=, 不再支持<>
6:字典类方法HAS_KEY()
Python2中,字典对象has_key()方法测试字典是否包含指定的键。python3不再支持这个方法,需要使用in.
7:重命名或重新组织的模块
从python2到python3,标准库里的一些模块已经被重命名。还有一些相互关联的模块也被组合或则重新组织,使得这种关联更有逻辑性。
8:全局函数FILTER()
在python2里,filter()方法返回一个列表,这个列表是通过一个返回值为True或False的函数来检测序列里的每一项的道德。在python3中,filter()函数返回一个迭代器,不再是列表。
9:MAP()
跟filter()的改变一样,map()函数现在返回一个迭代器,python2中返回一个列表。
10:APPLY()
python2有一个叫做apply()的全局函数,它使用一个函数f和一个列表[a,b,c]作为参数,返回值是f(a,b,c).可以直接调用这个函数,在列表前添加一个星号作为参数传递给它来完成同样的事情。在python3里记,apply()函数不再存在;必须使用星号标。
11:EXEC
就像print语句在python3里变成了一个函数一样,exec语句也是这样的。exec()函数使用一个包含任意python代码的字符串作为参数,然后像执行语句或表达式一样执行它。exec()跟eval()是相似,但exec()更加强大并具有挑战性。eval()函数只能执行单独一条表达式,但是exec()能够执行多条语句,导入(import),函数声明-实际上整个python程序的字符串表示也可以
12:execfile
python2中的execfile语句可以像执行python代码那样使用字符串。不同的是exec使用字符串,而execfile使用文件。在python3,execfile语句被去掉了
13:TRYEXCEPT语句
python2到python3,捕获异常的语法有些变化
14:RAISE
python3里,抛出自定义异常的语法有细微的变化。
15:生成器THROW
在python2里,生成器有一个throw()方法。调用a_generator.throw()会在生成器被暂停的时候抛出异常,然后返回由生成器函数获取的下一个值。python3中,这一功能仍然可用,但语法有一点不同。
16:XRANGE()
python2里,有两种方法获得一定范围内的数字:range(),返回一个列表,还有xrange(),返回一个迭代器。python3 里,range()返回迭代器,xrange()不再存在。
17:RAW_INPUT()和INPUT()
python2有两个全局函数,用在命令行请求用户输入。第一个叫input(),它等待用户输入一个python表达式(然后返回结果)。第二个叫做raw_input(),用户输入什么他就返回什么。python3 通过input替代了他们。
18:函数属性FUNC_*
python2,函数的代码可用访问到函数本身的特殊属性。python3为了一致性,这些特殊属性被重命名了。
例子:
| a_function.func_name | a_function.__name__ | __name__属性包含了函数的名字 |
19:I/O方法XREADLINES()
python2中,文件对象有一个xreadlines()方法,返回一个迭代器,一次读取文件的一行。这在for循环中尤其实用。python3中,xreadlines()方法不再可用。
20:lambda函数
在python2中,可以定义匿名函数lambda函数,通过指定作为参数的元组的元素个数,使这个函数实际上能够接收多个参数。python2的解释器把这个元组"解开“成命名参数,然后可以在lambda函数里引用它们。在python3中仍然可以传递一个元组为lambda函数的参数。但是python解释器不会把它当成解析成命名参数。需要通过位置索引来引用每个参数。
例子 :
# b为函数名 a,v都是形参 a+v为返回值
b = lambda a,v: a+v
print(b(1,10))
21:STANDARDERROR异常
python2中,StandardError是除了StopIteration,GeneratorExit,KeyboardInterrupt, SystemExit之外所有其他内置异常的基类。python3中StandardError已经被取消了,使用Exception取代。
22:TYPES模块中的常量
types模块里各种各样的常量能够帮助你决定一个对象的类型。在python2里,它包含了代表所有基本数据类型的常量,如dict和int。在python3里,这些常量被取消了,只需使用基础类型的名字来替代。
例子:
| python2 | python3 |
|---|---|
| types.UnicodeType | str |
23:全局函数ISINSTANCE()
isinstance()函数检查一个对象是否是一个特定类(class)或类型(type)的实例。在python2,可以传递一个由类型构成的元组给isinstance(),如果该对象是元组里的任意一种类型,函数返回True. 在python3,依然可以这样做。
24:ITERTOOLS模块
python2.3引入itertools模块,定义了zip(),map(),filter()的变体,这个变体返回的是迭代器,而非列表。在python3,这些函数返回的本身就是迭代器,所有这些变体函数就取消了。
24:对元组的列表解析
python2,如果需要编写一个遍历元组的列表解析,不需要在元组值周围加上括号。在python3里,这些括号是必需的。
| python2 | python3 |
|---|---|
| [ i for i in 1, 2] | [i for i in (1,2)] |
25:元类
在python2里,可以通过在类的声明中定义metaclass参数,或者定义一个特殊的类级别(class-level)__metaclass__属性,来创建元类。python3中,__metaclass__属性被取消了。
17:用一行代码实现数值交换:
a = 1
b = 2
a,b=b,a
print(a,b)
18:Python3和Python2中 int 和 long的区别?
python2有非浮点数准备的int和long类型。int类型最大值不能超过sys.maxint,而且这个最大值是平台相关的。可以通过在数字的末尾附上一个L来定义长整型,显然,它比int类型表示的数字范围更大。在python3里,只有一种整数类型int,大多数情况下,和python2中的长整型类似。
19:xrange和range的区别?
python2里,有两种方法获得一定范围内的数字:range(),返回一个列表,还有xrange(),返回一个迭代器。python3 里,range()返回迭代器,xrange()不再存在。
20:文件操作时:xreadlines和readlines的区别?
python2中,文件对象有一个xreadlines()方法,返回一个迭代器,一次读取文件的一行。这在for循环中尤其实用。python3中,xreadlines()方法不再可用。python3中readlines是返回整个文档的内容 并且是一个列表的形式 且每一行的对应着列表中的下标索引
21:列举布尔值为False的常见值?
1:数字0
2:None
3:空对象
4:空字符串
22:字符串、列表、元组、字典每个常用的5个方法?
字符串的方法:
<1>find
检测 str 是否包含在 mystr中,如果是返回开始的索引值,否则返回-1
mystr.find(str, start=0, end=len(mystr))
<2>index
跟find()方法一样,只不过如果str不在 mystr中会报一个异常.
mystr.index(str, start=0, end=len(mystr))
<3>count
返回 str在start和end之间 在 mystr里面出现的次数
mystr.count(str, start=0, end=len(mystr))
<4>replace
把 mystr 中的 str1 替换成 str2,如果 count 指定,则替换不超过 count 次.
mystr.replace(str1, str2, mystr.count(str1))
<5>split
以 str 为分隔符切片 mystr,如果 maxsplit有指定值,则仅分隔 maxsplit 个子字符串
mystr.split(str=" ", 2)
<6>capitalize
把字符串的第一个字符大写
mystr.capitalize()
<7>title
把字符串的每个单词首字母大写
>>> a = "hello itcast"
>>> a.title()
'Hello Itcast'
<8>startswith
检查字符串是否是以 obj 开头, 是则返回 True,否则返回 False
mystr.startswith(obj)
<9>endswith
检查字符串是否以obj结束,如果是返回True,否则返回 False.
mystr.endswith(obj)
<10>lower
转换 mystr 中所有大写字符为小写
mystr.lower()
<11>upper
转换 mystr 中的小写字母为大写
mystr.upper()
列表的方法:
chars = ['a', 'b', 'c', 'd']
for i, chr in enumerate(chars):
print(i, chr)
0 a
1 b
2 c
3 d
chars1=['c','d','k']
for i in zip(chars,chars1):
print(i)
('a', 'c')
('b', 'd')
('c', 'k')
<1>添加元素(“增”append, extend, insert)
通过append可以向列表添加元素
#定义列表A,有3个元素
A = ['xiaoWang','xiaoZhang','xiaoHua']
for tempName in A:
print(tempName)
temp = input('请输入要添加的学生姓名:')
A.append(temp)
for tempName in A:
print(tempName)
通过extend可以将另一个集合中的元素逐一添加到列表中
>>> a = [1, 2]
>>> b = [3, 4]
>>> a.append(b)
>>> a
[1, 2, [3, 4]]
>>> a.extend(b)
>>> a
[1, 2, [3, 4], 3, 4]
insert(index, object) 在指定位置index前插入元素object
>>> a = [0, 1, 2]
>>> a.insert(1, 3)
>>> a
[0, 3, 1, 2]
<2>修改元素(“改”)
修改元素的时候,要通过下标来确定要修改的是哪个元素,然后才能进行修改
#定义列表A,有3个元素
A = ['xiaoWang','xiaoZhang','xiaoHua']
for tempName in A:
print(tempName)
#修改元素
A[1] = 'xiaoLu'
for tempName in A:
print(tempName)
<3>查找元素(“查”in, not in, index, count)
所谓的查找,就是看看指定的元素是否存在。python中查找的常用方法为:
in(存在),如果存在那么结果为true,否则为false
not in(不存在),如果不存在那么结果为true,否则false
#待查找的列表
nameList = ['xiaoWang','xiaoZhang','xiaoHua']
#获取用户要查找的名字
findName = input('请输入要查找的姓名:')
#查找是否存在
if findName in nameList:
print('在字典中找到了相同的名字')
else:
print('没有找到')
index和count与字符串中的用法相同
index是索引到下标是给机器看的从0开始 count是给人看的计数 从1开始的 a.index('a',1,3)后面接的两个1,3参数是从1到3不包括3 (左闭右开,所谓包头不包尾)
>>> a = ['a', 'b', 'c', 'a', 'b']
>>> a.index('a', 1, 3) # 注意是左闭右开区间
Traceback (most recent call last):
File "", line 1, in
ValueError: 'a' is not in list
>>> a.index('a', 1, 4)
3
>>> a.count('b')
2
>>> a.count('d')
0
<4>删除元素(“删”del, pop, remove)
类比现实生活中,如果某位同学调班了,那么就应该把这个条走后的学生的姓名删除掉;在开发中经常会用到删除这种功能。列表元素的常用删除方法有:
del:根据下标进行删除
pop:删除最后一个元素
remove:根据元素的值进行删除
demo:(del) :对原列表进行操作 没有返回值 会报错 del movieName[2] (根据下表进行删除)
movieName = ['加勒比海盗','骇客帝国','第一滴血','指环王','霍比特人','速度与激情']
for tempName in movieName:
print(tempName)
del movieName[2]
for tempName in movieName:
print(tempName)
demo:(pop)
a = ['a', 'b', 'c', 'd']
print(a.pop()) 返回的是删除的值
print(a) ['a', 'b', 'c'] 删除最后一个元素
demo:(remove) a.remove('a') 根据选中的元素删除
a = ['a', 'b', 'c', 'd']
print(a.remove('a')) #返回值为None
print(a) #['b', 'c', 'd']
<5>排序(sort, reverse)
sort方法是将list按特定顺序重新排列,默认为由小到大,参数reverse=True可改为倒序,由大到小。reverse方法是将list逆置。
list1 = [1, 3, 5, 8, 1, 8]
a=sorted(list1, reverse=False) #为False是升序,为Ture是降序(默认升序)接受到的是返回值和sort不同
print(list1) # 顺序没改变
print(a) # 顺序为升序
>>> a = [1, 4, 2, 3]
>>> a
[1, 4, 2, 3]
>>> a.reverse()
>>> a
[3, 2, 4, 1]
>>> a.sort()
>>> a
[1, 2, 3, 4]
>>> a.sort(reverse=True)
>>> a
[4, 3, 2, 1]
元组
Python的元组与列表类似,不同之处在于元组的元素不能修改。元组使用小括号,列表使用方括号。
说明: python中不允许修改元组的数据,包括不能删除其中的元素。
<3>元组的内置函数count, index
index和count与字符串和列表中的用法相同
>>> a = ('a', 'b', 'c', 'a', 'b')
>>> a.index('a', 1, 3) # 注意是左闭右开区间
Traceback (most recent call last):
File "", line 1, in
ValueError: tuple.index(x): x not in tuple
>>> a.index('a', 1, 4)
3
>>> a.count('b')
2
>>> a.count('d')
0
字典
<1>软件开发中的字典
变量info为字典类型:
info = {'name':'班长', 'id':100, 'sex':'f', 'address':'地球亚洲中国北京'}
- 1
- 2
说明:
字典和列表一样,也能够存储多个数据
列表中找某个元素时,是根据下标进行的
字典中找某个元素时,是根据’名字’(就是冒号:前面的那个值,例如上面代码中的’name’、’id’、’sex’)
字典的每个元素由2部分组成,键:值。例如 ‘name’:’班长’ ,’name’为键,’班长’为值
注意:根据键访问若不存在则会报错
在我们不确定字典中是否存在某个键而又想获取其值时,可以使用get方法,还可以设置默认值:
>>> age = info.get('age')
>>> age #'age'键不存在,所以age为None >>> type(age) > >>> age = info.get('age', 18) # 若info中不存在'age'这个键,就返回默认值18 >>> age 18 字典的常见操作1(方法) <1>修改元素 : (修改值得话直接键赋值) <2>添加元素 总结:如果键存在的话就直接修改了, 不存在的话就直接增加了 <3>删除元素 1:demo:del删除指定的元素 de1 a #删除了怎么字典此时字典a已经找不到了 2:demo:clear清空整个字典 字典的常见操作2(方法) <1>len() 测量字典中,键值对的个数 <2>keys 返回一个包含字典所有KEY的列表 <3>values 返回一个包含字典所有value的列表 <4>items 返回一个包含所有(键,值)元祖的列表 lambda表达式,通常是在需要一个函数,但是又不想费神去命名一个函数的场合下使用,也就是指匿名函数。 map()函数第一个参数是lambda 列表迭代 *arg和**kwarg 可以帮助我们处理上面这种情况,允许我们在调用函数的时候传入多个实参 从上面的例子可以看到,当我传入了更多实参的时候 区别:*args是位置传参数,**kwarg是关键字传参数 # 解包列表a is比较的是对象的内存地址 ==比较对象的是值(内容) 1:==是python标准操作符中的比较操作符,用来比较判断两个对象的value(值)是否相等 2:is也被叫做同一性运算符,这个运算符比较判断的是对象间的唯一身份标识,也就是id是否相同 深浅拷贝用法来自copy模块。 导入模块:import copy 浅拷贝:copy.copy 深拷贝:copy.deepcopy 字面理解:浅拷贝指仅仅拷贝数据集合的第一层数据,深拷贝指拷贝数据集合的所有层。所以对于只有一层的数据集合来说深浅拷贝的意义是一样的,比如字符串,数字,还有仅仅一层的字典、列表、元祖等. 对于数字和字符串的深浅拷贝都只是将变量的索引指向了原来的内存地址,对于不可变的类型的对象都是将变量的索引指向了原来的内存地址 字典(列表)的深浅拷贝: Python为了避免频繁的申请和删除内存所造成系统切换于用户态和核心态的开销,从而引入了内存池机制,专门用来管理小内存的申请和释放。整个小块内存的内存池可以视为一个层次结构,其一共分为4层,从下之上分别是block、pool、arena和内存池。需要说明的是:block、pool和area都是代码中可以找到的实体,而最顶层的内存池只是一个概念上的东西,表示Python对于整个小块内存分配和释放行为的内存管理机制。 注意,内存大小以256字节为界限,大于则通过malloc进行分配,小于则通过内存池分配。 Python的GC模块主要运用了引用计数来跟踪和回收垃圾。在引用计数的基础上,还可以通过“标记-清除”解决容器对象可能产生的循环引用的问题。通过分代回收以空间换取时间进一步提高垃圾回收的效率。 原理:当一个对象的引用被创建或者复制时,对象的引用计数加1;当一个对象的引用被销毁时,对象的引用计数减1,当对象的引用计数减少为0时,就意味着对象已经再没有被使用了,可以将其内存释放掉。 优点:引用计数有一个很大的优点,即实时性,任何内存,一旦没有指向它的引用,就会被立即回收,而其他的垃圾收集技术必须在某种特殊条件下才能进行无效内存的回收 缺点:但是它也有弱点,引用计数机制所带来的维护引用计数的额外操作与Python运行中所进行的内存分配和释放,引用赋值的次数是成正比的,这显然比其它那些垃圾收集技术所带来的额外操作只是与待回收的内存数量有关的效率要低。同时,引用技术还存在另外一个很大的问题-循环引用,因为对象之间相互引用,每个对象的引用都不会为0,所以这些对象所占用的内存始终都不会被释放掉。如下: 标记-清除只关注那些可能会产生循环引用的对象,显然,像是PyIntObject、PyStringObject这些不可变对象是不可能产生循环引用的,因为它们内部不可能持有其它对象的引用。Python中的循环引用总是发生在container对象之间,也就是能够在内部持有其它对象的对象,比如list、dict、class等等。这也使得该方法带来的开销只依赖于container对象的的数量??? 原理:1. 寻找跟对象(root object)的集合作为垃圾检测动作的起点,跟对象也就是一些全局引用和函数栈中的引用,这些引用所指向的对象是不可被删除的; 2. 从root object集合出发,沿着root object集合中的每一个引用,如果能够到达某个对象,则说明这个对象是可达的,那么就不会 被删除,这个过程就是垃圾检测阶段; 3. 当检测阶段结束以后,所有的对象就分成可达和不可达两部分,所有的可达对象都进行保留,其它的不可达对象所占用的内存将会被回收,这就是垃圾回收阶段。(底层采用的是链表将这些集合的对象连接在一起) 缺点:标记和清除的过程效率不高。 原理:将系统中的所有内存块根据其存活时间划分为不同的集合,每一个集合就成为一个“代”,Python默认定义了三代对象集合,垃圾收集的频率随着“代”的存活时间的增大而减小。也就是说,活得越长的对象,就越不可能是垃圾,就应该减少对它的垃圾收集频率。那么如何来衡量这个存活时间:通常是利用几次垃圾收集动作来衡量,如果一个对象经过的垃圾收集次数越多,可以得出:该对象存活时间就越长。 Python的每个对象都分为可变和不可变,主要的核心类型中,数字、字符串、元组是不可变的,列表、字典,集合是可变的 取并集 更新 结果:{'k2': [66, 666], 'k1': [66, 666]} 答案:[6, 6, 6, 6] python补充最常见的内置函数 最常见的内置函数是: print("Hello World!") 数学运算 abs(-5) # 取绝对值,也就是5 round(2.6) # 四舍五入取整,也就是3.0 pow(2, 3) # 相当于2**3,如果是pow(2, 3, 5),相当于2**3 % 5 cmp(2.3, 3.2) # 比较两个数的大小 divmod(9,2) # 返回除法结果和余数 max([1,5,2,9]) # 求最大值 min([9,2,-4,2]) # 求最小值 sum([2,-1,9,12]) # 求和 类型转换 int("5") # 转换为整数 integer float(2) # 转换为浮点数 float str(2.3) # 转换为字符串 string complex(3, 9) # 返回复数 3 + 9i ord("A") # "A"字符对应的数值 chr(65) # 数值65对应的字符 bool(0) # 转换为相应的真假值,在Python中,0相当于False 在Python中,下列对象都相当于False:[], (),{},0, None,0.0,'' bin(56) # 返回一个字符串,表示56的二进制数 hex(56) # 返回一个字符串,表示56的十六进制数 oct(56) # 返回一个字符串,表示56的八进制数 list((1,2,3)) # 转换为表 list tuple([2,3,4]) # 转换为定值表 tuple slice(5,2,-1) # 构建下标对象 slice dict(a=1,b="hello",c=[1,2,3]) # 构建词典 dictionary({'c': [1, 2, 3], 'b': 'xx', 'a': 1}) 序列操作 all([True, 1, "hello!"]) # 是否所有的元素都相当于True值 any(["", 0, False, [], None]) # 是否有任意一个元素相当于True值 sorted([1,5,3]) # 返回正序的序列,也就是[1,3,5] 类,对象,属性 hasattr(me, "test") # 检查me对象是否有test属性和方法 getattr(me, "test") # 返回test属性 setattr(me, "test", new_test) # 将test属性设置为new_test delattr(me, "test") # 删除test属性 isinstance(me, Me) # me对象是否为Me类生成的对象 (一个instance) issubclass(Me, object) # Me类是否为object类的子类 filter(lambda n : n>5,range(10) filter,迭代器,把符合要求的值列出来(此处要求为n>5) map(lambda n : n*n,range(10) map,把对参数的操作就过列出来(此处操作为n*n) functools.reduce(lambda x ,y : x*y,range(1,10)) reduce把一个函数作用在一个序列[x1, x2, x3...]上,这个函数必须接收两个参数,reduce把结果继续和序列的下一个元素做累积计算,其效果就是: 比方说对一个序列求和,就可以用reduce实现: 过去的教程讲得有点抽象,今天我们来形象地了解filter(),map()和reduce()的用法及区别。先来看filter()和map()。 [True, False, True, False, True, False, True, False, True, False, True, False, True, False, True, False, True, False, True] 这里如果用filter的话,说明匿名函数lambda给出的是个筛选条件,从1到19中筛选出奇数来,但这里如果用map的话,就好像变成了它判断对错的条件,只打印true和false。 而map一般的用法如下,参数有一个函数一个序列,将右边的序列经过左边的函数变换,生成新的序列。 l2 = list(map(lambda n: n * n, range(1, 20))) print(l2) [1, 4, 9, 16, 25, 36, 49, 64, 81, 100, 121, 144, 169, 196, 225, 256, 289, 324, 361] 而至于reduce这样的累加函数,并不是很常用,在python3中已将其从全局空间移除,现被放置在functools的模块里,用之前需要引入 from functools import reduce 利用reduce将1累加到19的程序如下: one: two: three: 得到的是1+到20的结果190 在Python中,安装第三方模块,是通过setuptools这个工具完成的。Python有两个封装了setuptools的包管理工具:easy_install和pip。目前官方推荐使用pip 如果你正在使用Mac或Linux,安装pip本身这个步骤就可以跳过了。 如果你正在使用Windows,确保安装时勾选了pip和Add python.exe to Path。 在命令提示符窗口下尝试运行pip,如果Windows提示未找到命令,可以重新运行安装程序添加pip gevent django threading multiprocessing ....很多 os模块#用作系统级别的工作 sys模块#提供解释器相关操作 hashlib模块# 用于加密相关的操作 json和pickle模块 #用于序列化数据 subprocess模块 shuit模块 #文件的复制移动 logging模块#格式化记录日志 random模块 用于取随机数 time datetime模块时间模块 re模块 正则匹配 match()函数只检测RE是不是在string的开始位置匹配, search()会扫描整个string查找匹配; 也就是说match()只有在0位置匹配成功的话才有返回, 如果不是开始位置匹配成功的话,match()就返回none。 print(re.match(‘super’, ‘superstition’).span()) 会返回(0, 5) 而print(re.match(‘super’, ‘insuperable’)) 则返回None 例如:print(re.search(‘super’, ‘superstition’).span())返回(0, 5) print(re.search(‘super’, ‘insuperable’).span())返回(2, 7) 1.什么是正则表达式的贪婪与非贪婪匹配 默认贪婪: 贪婪匹配:正则表达式一般趋向于最大长度匹配,也就是所谓的贪婪匹配。 非贪婪匹配:就是匹配到结果就好,就少的匹配字符。 2.编程中如何区分两种模式 默认是贪婪模式;在量词后面直接加上一个问号?就是非贪婪模式。 量词:{m,n}:m到n个 *:任意多个 +:一个到多个 ?:0或一个 那我们先通过程序看看这个函数有什么坑吧! 看下结果 [1] 函数的第二个默认参数是一个list,当第一次执行的时候实例化了一个list,第二次执行还是用第一次执行的时候实例化的地址存储,所以三次执行的结果就是 [1, 1, 1] ,想每次执行只输出[1] ,默认参数应该设置为None。 print([1, 2, 3]) [1, 2, 3] 在一个函数中用global声明一个变量,在函数外是可以调用的, 通过log的分析,可以方便用户了解系统或软件、应用的运行情况;如果你的应用log足够丰富,也可以分析以往用户的操作行为、类型喜好、地域分布或其他更多信息;如果一个应用的log同时也分了多个级别,那么可以很轻易地分析得到该应用的健康状况,及时发现问题并快速定位、解决问题,补救损失。 即:DEBUG < INFO < WARNING < ERROR < CRITICAL,而日志的信息量是依次减少的; Python实现的栈(Stack) Python本身已有顺序表(List、Tupple)的实现,所以这里从栈开始。 想象一摞被堆起来的书,这就是栈。这堆书的特点是,最后被堆进去的书,永远在最上面。从这堆书里面取一本书出来,取哪本书最方便?肯定是最上面那本。栈这种数据结构的特点就是如此:后进先出(Last In First Out - LIFO),即最后被堆进去的数据,最先被拿出来。 Python的字符串格式化常用的有三种! 第一种:最方便的 缺点:需一个个的格式化 第二种:最好用的 优点:不需要一个个的格式化,可以利用字典的方式,缩短时间 第三种:最先进的 优点:可读性强 迭代器是访问集合元素的一种方式。迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。迭代器只能往前不会后退。 迭代器有两个基本的方法 事实上,因为迭代器如此普遍,python专门为for关键字做了迭代器的语法糖。在for循环中,Python将自动调用工厂函数iter()获得迭代器,自动调用next()获取元素,还完成了检查StopIteration异常的工作。如下 带有 yield 的函数在 Python 中被称之为 generator(生成器) 简单地讲,yield 的作用就是把一个函数变成一个 generator,带有 yield 的函数不再是一个普通函数,Python 解释器会将其视为一个 generator,调用 fab(5) 不会执行 fab 函数,而是返回一个 iterable 对象!在 for 循环执行时,每次循环都会执行 fab 函数内部的代码,执行到 yield b 时,fab 函数就返回一个迭代值,下次迭代时,代码从 yield b 的下一条语句继续执行,而函数的本地变量看起来和上次中断执行前是完全一样的,于是函数继续执行,直到再次遇到 yield。看起来就好像一个函数在正常执行的过程中被 yield 中断了数次,每次中断都会通过 yield 返回当前的迭代值。 如果直接对文件对象调用 read() 方法,会导致不可预测的内存占用。好的方法是利用固定长度的缓冲区来不断读取文件内容。通过 yield,我们不再需要编写读文件的迭代类,就可以轻松实现文件读取。 不会 在一个外函数中定义了一个内函数,内函数里运用了外函数的临时变量,并且外函数的返回值是内函数的引用。这样就构成了一个闭包。 总结就是,os模块负责程序与操作系统的交互,提供了访问操作系统底层的接口;sys模块负责程序与python解释器的交互,提供了一系列的函数和变量,用于操控python的运行时环境。 import os print(os.remove(path)) remove是删除文件的,rmdir是删除文件夹的 1:面向对象的三大特征: 封装,继承,多态 面向对象是一种思想,把数据和功能结合起来,用称为对象的东西包裹起来组织程序的方法。这种方法称为,面向对象的编程理念 四、函数和面向对象编程的区别 相同点:都是把程序进行封装、方便重复利用,提高效率。 不同点:函数重点是用于整体调用,一般用于一段不可更改的程序。仅仅是解决代码重用性的问题。 而面向对象出来代码重用性。还包括继承、多态等。使用上更加灵活。 面向对象中的继承 子类继承了父类拥有的属性和方法,父类的私有属性不会被继承 例子: 什么是super? super() 函数是用于调用父类(超类)的一个方法。 functools,用于高阶函数:指那些作用于函数或者返回其它函数的函数。 1、构造方法,析构方法 2 当删除一个对象时,python解释器会默认调用__del__()方法 3、__call__(self, *args) 对象后面+()直接调用call方法,此方法python独有 *注意:类后面加()调用执行init方法,对象后面()直接调用call方法 4、__add__(self, other) 对象相加直接执行 5,__sub__(self,other) 对象相减直接执行 6、__dict__ 获取对象中封装的所有字段,用__dict__可以取到,并存放在字段中 Django REST framework URL响应请求的url路由 REST framework 包括 Request(继承自HttpRequest) 和 Response( 将model 实体转换为Python的dictionaires, 然后 渲染成多个API适用的格式,例如JSON或XML。 基于class的view可以用于复用代码,提供API到浏览器的显示。 总结:类方法和静态方法唯一不同的就是类方法需要传入一个参数而这个参数cls指的是类的本身,而静态方法不需要传参数 实例对象可以调用直接调用实例方法,类方法,静态方法。 类名字可以调用类方法和静态方法,也可以传入一个参数调用实例方法 根据官方文档: __init__是当实例对象创建完成后被调用的,然后设置对象属性的一些初始值。 __new__是在实例创建之前被调用的,因为它的任务就是创建实例然后返回该实例,是个静态方法。 也就是,__new__在__init__之前被调用,__new__的返回值(实例)将传递给__init__方法的第一个参数,然后__init__给这个实例设置一些参数。 0,__new__是在实例创建之前被调用的,因为它的任务就是创建实例然后返回该实例,是个静态方法。 1、构造方法,析构方法 2 当删除一个对象时,python解释器会默认调用__del__()方法 3、__call__(self, *args) 对象后面+()直接调用call方法,此方法python独有 *注意:类后面加()调用执行init方法,对象后面()直接调用call方法 4、__add__(self, other) 对象相加直接执行 5,__sub__(self,other) 对象相减直接执行 6、__dict__ 获取对象中封装的所有字段,用__dict__可以取到,并存放在字段中 总结:做这种题目第一反应就是for循环了吧 python的四个重要内置函数: 反射的定义 反射的概念是由Smith在1982年首次提出的,主要是指程序可以访问、检测和修改它本身状态或行为的一种能力。这一概念的提出很快引发了计算机科学领域关于应用反射性的研究 1:首先建立一个这样的文件 ------------------------------------------------------------------------------------------------------------------ 2:再创建一个这样的文件 除了使用 metaclass,直译为元类,简单的解释就是: 当我们定义了类以后,就可以根据这个类创建出实例,所以:先定义类,然后创建实例。 但是如果我们想创建出类呢?那就必须根据metaclass创建出类,所以:先定义metaclass,然后创建类。 连接起来就是:先定义metaclass,就可以创建类,最后创建实例。 所以,metaclass允许你创建类或者修改类。换句话说,你可以把类看成是metaclass创建出来的“实例”。 ------------------------------------------------------------------------------------------------------------------------------------------------------------------------- 单例模式概念:作为对象的创建模式,单例模式确保某一个类只有一个实例,而且自行实例化并向整个系统提供这个实例。这个类称为单例类。 1)单例类只能有一个实例 2)单例类必须自己创建自己的唯一实例 3)单例类必须给所有其他对象提供这一实例 在 Python 中,我们可以用多种方法来实现单例模式: 使用__new__实现单例模式的例子: 应用场景: 带参数装饰器: 例子: 打印结果: 1 总结:装饰器还可以用于面向切面 例子1: 注意:有异常的情况下走except Exceotion 里面去了,不发生异常走到else里面去了, 最终都会走到finally里面去 了解? 例子2: 注意:主动抛异常用raise 事实上,对于你定义的每一个类,Python 会计算出一个方法解析顺序(Method Resolution Order, MRO)列表,它代表了类继承的顺序,我们可以使用下面的方式获得某个类的 MRO 列表: 那这个 MRO 列表的顺序是怎么定的呢,它是通过一个 C3 线性化算法来实现的,这里我们就不去深究这个算法了,感兴趣的读者可以自己去了解一下,总的来说,一个类的 MRO 列表就是合并所有父类的 MRO 列表,并遵循以下三条原则: ( 就是检查一个对象是否是由指定的类创建的 isinstance(实例对象,类名字) 为Ture的话就是由该类创建的实例对象,为False就不是由该类创建的 在python中,序列化可以理解为:把python的对象编码转换为json格式的字符串,反序列化可以理解为:把json格式字符串解码为python数据对象。在python的标准库中,专门提供了json库与pickle库来处理这部分。 json的dumps方法和loads方法,可实现数据的序列化和反序列化。具体来说,dumps方法,把python数据类型转换为json相应的数据类型格式要求。loads方法则是相反,可将json格式数据序列为Python的相关的数据类型;在序列化时,中文汉字总是被转换为unicode码,在dumps函数中添加参数ensure_ascii=False即可解决。 断言条件为真时代码继续执行, 否则抛出异常,这个异常通常不会去捕获他.我们设置一个断言目的就是要求必须实现某个条件 文件操作的时候用过 with语句的作用是通过某种方式简化异常处理,它是所谓的上下文管理器的一种 当你要成对执行两个相关的操作的时候,这样就很方便,以上便是经典例子,with语句会在嵌套的代码执行之后,自动关闭文件。这种做法的还有另一个优势就是,无论嵌套的代码是以何种方式结束的,它都关闭文件。如果在嵌套的代码中发生异常,它能够在外部exception handler catch异常前关闭文件。如果嵌套代码有return/continue/break语句,它同样能够关闭文件。 yield是python中定义为生成器函数
字典的每个元素中的数据是可以修改的,只要通过key找到,即可修改
info = {'name':'班长', 'id':100, 'sex':'f', 'address':'地球亚洲中国北京'}
newId = input('请输入新的学号')
info['id'] = int(newId)
print('修改之后的id为%d:'%info['id'])
a = {'name': 'xm', 'age': 10}
a['sex'] = '女' {'name': 'xm', 'sex': '女', 'age': 10}
a['name'] = 'xjw' {'name': 'xjw', 'sex': '女', 'age': 10}
对字典进行删除操作,有一下几种:
del
clear()
a = {'name': 'xm', 'age': 10}
del a['name']
print(a) #{'age': 10}
a = {'name': 'xm', 'age': 10}
a.clear()
print(a) #{} 字典还存在只是为空字典了
a = {'name': 'xm', 'age': 10}
print(len(a)) # 测量字典中元素的长度
a = {'name': 'xm', 'age': 10}
print(a.keys()) # dict_keys(['name', 'age']) 返回的是键
print(type(a.keys())) #
a = {'name': 'xm', 'age': 10}
print(a.values()) # dict_values([10, 'xm']) 返回的是值
print(type(a.values())) #
print(type(a.values()))
a = {'name': 'xm', 'age': 10}
print(a.items()) # dict_items([('age', 10), ('name', 'xm')])23:lambda表达式格式以及应用场景?
f = lambda x: pow(x, 4)
print(f(2)) # 1624:pass的作用?
25:*arg和**kwarg作用
定义函数时,使用*arg和**kwarg
def exmaple2(required_arg, *arg, **kwarg):
if arg:
print "arg: ", arg
if kwarg:
print "kwarg: ", kwarg
exmaple2("Hi", 1, 2, 3, keyword1 = "bar", keyword2 = "foo")
>> arg: (1, 2, 3)
>> kwarg: {'keyword2': 'foo', 'keyword1': 'bar'}
tupledict
def sum(a, b, c):
return a + b + c
a = [1, 2, 3]
# the * unpack list a
print sum(*a)
>> 626:is和==的区别
27:简述Python的深浅拷贝以及应用场景?
>>> import copy
>>> name="hahah" #字符串
>>> name1=copy.copy(name)
>>>
>>> name2=copy.deepcopy(name)
>>> print(id(name),id(name1),id(name2))
11577192 11577192 11577192 赋值:
import copy
n1 = {'k1':'wu','k2':123,'k3':['alex',678]}
n2 = n1
浅拷贝:对于第一层的数据内存地址发生改变,copy出来了一个新的对象,对象深层次的仍然保持引用
import copy
n1 = {'k1':'wu','k2':123,'k3':['alex',678]}
n3 = copy.copy(n1)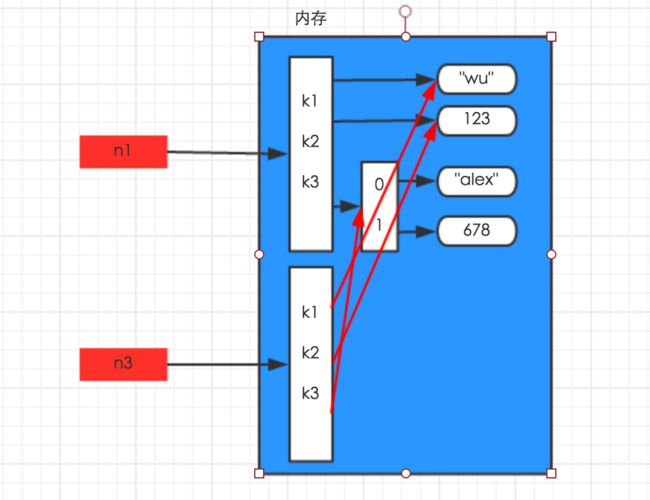
深拷贝:直接copy出来一个新的对象,不管对于第一层还是深层次的,内存地址都发生改变了
import copy
n1 = {'k1':'wu','k2':123,'k3':['alex',678]}
n4 = copy.deepcopy(n1)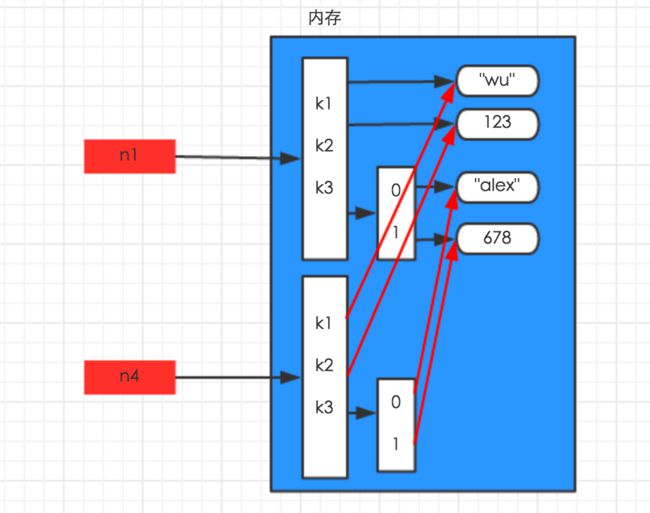
28:Python垃圾回收机制?
内存池
垃圾回收
引用计数
a = []
b = []
a.append(b)
b.append(a)
print a
[[[…]]]
print b
[[[…]]]标记-清除
分代回收
29:可变类型和不可变类型
se = {11, 22, 33}
be = {22,44,55}
temp=se.union(be) #取并集,并赋新值
print(se) #{33, 11, 22}
print(temp) #{33, 22, 55, 11, 44}
se = {11, 22, 33}
be = {22,44,55}
se.update(be) # 把se和be合并,得出的值覆盖se
print(se)
se.update([66, 77]) # 可增加迭代项
print(se)30:求结果:
v = dict.fromkeys(['k1','k2'],[33])
v['k1'].append(666)
print(v)
v['k1'] = 777
print(v)
{'k2': [66, 666], 'k1': 777}31:求结果
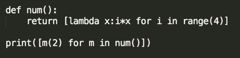
32:列举常见的内置函数?
33:filter、map、reduce的作用?
>>> def add(x, y): return x + y>>> reduce(add, [1, 3, 5, 7, 9]重点
l1 = list(filter(lambda n: n % 2 == 1, range(1, 20)))
print(l1)
[1, 3, 5, 7, 9, 11, 13, 15, 17, 19]
l2 = list(map(lambda n: n % 2 == 1, range(1, 20)))
print(l2)
总结:filter和map返回的都是迭代器 可用for循环和next()函数 拿到得到结果
a = filter(lambda n: n % 2 == 1, range(1, 20))
# for i in a:
# print(i)
print(a)
print(type(a)) 1
print(next(a)) 3
print(next(a)) 5
print(next(a)) 7
print(next(a)) 9
a = (map(lambda n: n * n, range(10)))
print(type(a))
print(next(a)) 0
print(next(a)) 1
print(next(a)) 4
print(next(a)) 9
print(next(a)) 16
print(next(a)) 25
for i in a:
print(i)
36
49
64
81 接着上面输出后的继续接着输出 ,这就是迭代器的特性
from functools import reduce
print(reduce(lambda x, y: x + y, range(1, 20))) 34:一行代码实现9*9乘法表
print("\n".join("\t".join(["%s*%s=%s" % (x, y, x * y) for y in range(1, x + 1)]) for x in range(1, 10)))
35、如何安装第三方模块?以及用过哪些第三方模块?
常用模块:
36:至少列举8个常用模块都有那些?
常用模块
37:re的match和search区别?
注意:re正则模块match函数第一个参数是匹配规则,第二个参数是要匹配的数据
例如:
search()会扫描整个字符串并返回第一个成功的匹配38:什么是正则的贪婪匹配?
例子:
a = re.match('\d+', '111sss55dfsdfsdf5')
print(a) <_sre.SRE_Match object; span=(0, 1), match='111'>
非贪婪模式:
b = re.match('\d{5,20}?', '111111111sss55dfsdfsdf5')
print(b) <_sre.SRE_Match object; span=(0, 5), match='11111'>
39:求结果:
a. [ i % 2 for i in range(10) ]
b. ( i % 2 for i in range(10) )
没看懂题目是什么意思????
40:求结果:
a. 1 or 2
b. 1 and 2
c. 1 < (2==2)
d. 1 < 2 == 2
还是看不懂::::::
41、def func(a,b=[]) 这种写法有什么坑?
def func(a,b=[]):
b.append(a)
print(b)
func(1)
func(1)
func(1)
func(1)
[1, 1]
[1, 1, 1]
[1, 1, 1, 1]42:如何实现 “1,2,3” 变成 [‘1’,’2’,’3’] ?
str1 = "1,2,3"
str1 = str1.split(',')
print(str1)43:如何实现[‘1’,’2’,’3’]变成[1,2,3] ?
a = ['1', '2', '3']
第一种:a = [int(i) for i in a]
print(a)
第二种:b = map(int, a)
print(list(b))44:比较: a = [1,2,3] 和 b = [(1),(2),(3) ] 以及 c = [(1,),(2,),(3,) ] 的区别?
print([(1), (2), (3)]) [1, 2, 3]
print((1,), (2,), (3,)) (1,) (2,) (3,)
a 列表里面的的每个元素都是数字类型,
b 列表里面的元素也是数字,这里面的小括号代表的优先运算符,
c 列表里面的每个元素都是元组。
45:如何用一行代码生成[1,4,9,16,25,36,49,64,81,100] ?
num = [i*i for i in range(1,11)]
print(num)46:一行代码实现删除列表中重复的值 ?
list2 = [1, 2, 3, 2, 5, 6, 4, 4]
print(list(set(list2)))47:如何在函数中设置一个全局变量 ?
a = 1
def xm():
global a
a = a + 3
print(id(a))
return a + 1
print(xm())
print(id(a)) # 这个时候id是一样的
print(a)
48:logging模块的作用?以及应用场景?
1.日志的作用
简单来讲就是,我们通过记录和分析日志可以了解一个系统或软件程序运行情况是否正常,也可以在应用程序出现故障时快速定位问题。比如,做运维的同学,在接收到报警或各种问题反馈后,进行问题排查时通常都会先去看各种日志,大部分问题都可以在日志中找到答案。再比如,做开发的同学,可以通过IDE控制台上输出的各种日志进行程序调试。对于运维老司机或者有经验的开发人员,可以快速的通过日志定位到问题的根源。可见,日志的重要性不可小觑。日志的作用可以简单总结为以下3点:
49:请用代码简答实现stack 。
前言
什么是栈
class Stack(object):
def __init__(self):
self.stack = []
def push(self, value): # 进栈
self.stack.append(value)
def pop(self): # 出栈
if self.stack:
self.stack.pop()
else:
try:
raise LookupError
except Exception:
print('stack is empty!')
def is_empty(self): # 如果栈为空
return bool(self.stack)
def top(self):
# 取出目前stack中最新的元素
return self.stack[-1]
s = Stack()
s.push(1)
s.push(2)
s.push(3)
s.push(4)
print(s.stack)
s.pop()
s.pop()
print(s.stack)
print(s.is_empty())
print(s.top())
50、常用字符串格式化有哪几种?
print('hello %s and %s'%('df','another df'))
print('hello %(first)s and %(second)s'%{'first':'df' , 'second':'another df'})
print('hello {first} and {second}'.format(first='df',second='another df'))51:简述 生成器、迭代器、可迭代对象 以及应用场景?
1. 迭代器(iterator)
next方法:返回迭代器的下一个元素__iter__方法:返回迭代器对象本身
a = [1, 2, 3]
a = iter(a) # 可迭代对象转换为迭代器
# for i in range(5):
# print(next(a))
# raise StopIteration()
# print(next(a))
# print(next(a))
# print(next(a))斐波拉契:
max = input('请输入')
def fab(max):
a, b = 0, 1
for i in range(int(max)):
print(b)
a, b = b, a + b
fab(int(max))
注意:python处理迭代器越界是抛出StopIteration异常
扩展:
>>> a = (1, 2, 3, 4)
>>> for key in a:
print key
1
2
3
42. 生成器(Generators)
def fab(max):
n, a, b = 0, 0, 1
while n < max:
yield b # 声明一个生成器
a, b = b, a + b
n = n + 1
f1 = fab(5)
# print(next(f1))
# print(next(f1))
# print(next(f1))
# print(next(f1))
# print(next(f1))
for i in f1:
print(i)
白话解释:
def read_file(fpath):
BLOCK_SIZE = 1024
with open(fpath, 'rb') as f:
while True:
block = f.read(BLOCK_SIZE)
if block:
yield block
else:
try:
raise StopIteration('没有数据了')
except Exception as e:
print(repr(e))
return
a = read_file('三棵树.jpg')
# 用for循环就不会报错,因为没有数据也就不会循环了,如果使用next(a)那么没有数据在打印下一个的话就会报错了,(StopIteration)
for i in a:
print(i)
3:Python可迭代对象(Iterable)
Python中经常使用for来对某个对象进行遍历,此时被遍历的这个对象就是可迭代对象,像常见的list,tuple都是。如果给一个准确的定义的话,就是只要它定义了可以返回一个迭代器的__iter__方法,或者定义了可以支持下标索引的__getitem__方法(这些双下划线方法会在其他章节中全面解释),那么它就是一个可迭代对象。52:用Python实现一个二分查找的函数。
53:谈谈你对闭包的理解?
闭包:
例子1:
def outer(a):
b = 10
# inner是内函数
def inner():
# 在内函数中 用到了外函数的临时变量
print(a + b)
# 外函数的返回值是内函数的引用
return inner
o = outer(1)
o() # 11例子2:
def outer(a):
b = 10 # a和b都是闭包变量
c = [a] # 这里对应修改闭包变量的方法2
# inner是内函数
def inner():
# 内函数中想修改闭包变量
# 方法1 nonlocal关键字声明
nonlocal b
b += 1
# 方法二,把闭包变量修改成可变数据类型 比如列表
c[0] += 1
print(c[0])
print(b)
# 外函数的返回值是内函数的引用
return inner
if __name__ == '__main__':
demo = outer(5)
demo() # 6 11
54:os和sys模块的作用?
55:如何生成一个随机数?
import random
print(random.random())
56:如何使用python删除一个文件?
57:谈谈你对面向对象的理解?
58:Python面向对象中的继承有什么特点?
59:面向对象深度优先和广度优先是什么?
深度优先的模型,像是一条道走到黑,不撞南墙不回头的模式。但是基于的模型,类似于堆栈模型。再撞到南墙的时候,回溯到上一次撞墙前的位置。这样的的操作相当于stack的pop出最新入栈的那条数据。然后继续找一个之前没有走过的结点尝试。
深度优先:不全部保留节点,占用空间小,有回溯操作(即有入栈/出栈操作),运行速度慢。
广度优先:保留全部节点,占用空间大;无回溯操作(既无入栈、出栈操作)、运行速度快。总结:深度优先就是垂直往下走,广度优先就是平行的走
60:面向对象中super的作用?
super 是用来解决多重继承问题的,直接用类名调用父类方法在使用单继承的时候没问题,但是如果使用多继承,会涉及到查找顺序(MRO)、重复调用(钻石继承)等种种问题。
MRO 就是类的方法解析顺序表, 其实也就是继承父类方法时的顺序表。
class A(object): # python3版本的
pass
class B(A):
def add(self, x):
super().add(x)
class A(object): # Python2.x 记得继承 object
pass
class B(A):
def add(self, x):
super(B, self).add(x)61:是否使用过functools中的函数?其作用是什么?
通常只要是可以被当做函数调用的对象就是这个模块的目标。
里面包含如偏函数 partial 等。
from functools import reduce
def add(x, y):
return x + y
print(reduce(add, [1, 3, 5, 7, 9])) #2562:列举面向对象中带爽下划线的特殊方法,如:__new__、__init__
![]() __init__(self,...) 构造方法,这个方法在创建对象时就会访问。也即:类后面加()调用执行init方法
__init__(self,...) 构造方法,这个方法在创建对象时就会访问。也即:类后面加()调用执行init方法![]() __del__(self) 析构方法,恰好在对象要被删除之前调用。不用专门写,系统会自动调用
__del__(self) 析构方法,恰好在对象要被删除之前调用。不用专门写,系统会自动调用
class A(object):
def __init__(self, age):
self.age = age
print('init初始化函数')
def __call__(self, *args, **kwargs):
print('call方法被调用了')
def __str__(self):
return 'str方法被调用了'
def __add__(self, other):
return self.age + other.age
# return '年龄和{}+{}={}'.format(self.age, other.age, self.age - other.age)
def __sub__(self, other):
return self.age - other.age
def __eq__(self, other):
return True
def __iter__(self):
return iter([1, 2, 3, 4, 5])
def __getitem__(self, item):
print(item)
def __del__(self):
print('del方法被调了')
a = A(20)
b = A(20)
# -------__call__-------演示
a() # call方法被调用了
# =================================================
# -------__str__------演示
print(a) # str方法被调用了
# -------__str__-------演示
print(a.__str__()) # str方法被调用了
# =================================================
# -------__add__------演示
print(a.__add__(other=b)) # 30
# -------__add__------演示
print(a + b) # 30
# =================================================
# -------__sub__------演示
print(a - b) # -10
# =================================================
# --------__dict__演示------
print(a.__dict__) # {'age': 10}
print(b.__dict__) # {'age': 20}
# =================================================
# ------------ __iter__-------演示
for i in a:
print(i) # 1,2,3,4,5
# python中在删除对象之前会自动调用__del__的方法
# ------------ __eq__-------演示
print(a == b)
63:如何判断是函数还是方法?
我们的函数只有跟我们的实例化出来的对象有绑定关系才能称之为方法,否则都是函数,即便它是写到类里面的方法,没有跟我们的类实例化出来的对象进行绑定,它依然是函数,而不是类里面的方法.64:django rest framework框架中都有那些组件?
框架主要包括四个主要概念URLs
Request & Responses
TemplateResponse)Model Serializers
Class-based Views
64:静态方法和类方法区别?
class A(object):
def run(self):
print('xm正在跑')
@classmethod #类方法
def lei(cls):
print('xm正在调用类方法')
@staticmethod # 静态方法
def fun():
print('xm正在调用静态方法')
a = A()
a.run()
a.lei()
a.fun()
# 类名点实例方法的时候必须传一个参数进去
A.run(1)
A.lei()
A.fun()65:列举面向对象中的特殊成员以及应用场景
![]() __init__(self,...) 构造方法,这个方法在创建对象时就会访问。也即:类后面加()调用执行init方法
__init__(self,...) 构造方法,这个方法在创建对象时就会访问。也即:类后面加()调用执行init方法![]() __del__(self) 析构方法,恰好在对象要被删除之前调用。不用专门写,系统会自动调用
__del__(self) 析构方法,恰好在对象要被删除之前调用。不用专门写,系统会自动调用66:1、2、3、4、5 能组成多少个互不相同且无重复的三位数
count = 0
for i in range(1, 6):
for j in range(1, 6):
for k in range(1, 6):
if (i != j) and (j != k) and (k != i):
count += 1
print('{}{}{}'.format(i, j, k), end='\n')
print(count) # 60
67:什么是反射?以及应用场景?getattr、hasattr、delattr和setattr较为全面的实现了基于字符串的反射机制。他们都是对内存内的模块进行操作,并不会对源文件进行修改。
def login():
print("这是一个登陆页面!")
def logout():
print("这是一个退出页面!")
def home():
print("这是网站主页面!")
def run1():
inp = input("请输入您想访问页面的url: ").strip()
modules, func = inp.split("/")
obj = __import__(modules)
if hasattr(obj, func):
func = getattr(obj, func)
func()
else:
print('404')
if __name__ == '__main__':
try:
run1()
except Exception as e:
print(repr(e))
68:metaclass作用?以及应用场景
metaclass
type()动态创建类以外,要控制类的创建行为,还可以使用metaclass。
'''
要创建一个class对象,type()函数依次传入3个参数:
1 class的名称;
2 继承的父类集合,注意Python支持多重继承,如果只有一个父类,别忘了tuple的单元素写法;
3 class的方法名称与函数绑定,这里我们把函数fn绑定到方法名hello上。
'''
# 通过type()函数创建的类和直接写class是完全一样的,因为Python解释器遇到class定义时,
# 仅仅是扫描一下class定义的语法,然后调用type()函数创建出class。
def fn(name='world'):
print('hello{}'.format(name))
Hello = type('Hello', (object,), dict(hello=fn))
h = Hello
h.hello()
69:用尽量多的方法实现单例模式
单例模式特点:
实现方式:
__new__
class Singleton(object):
_instance = None
def __new__(cls, *args, **kwargs):
if not cls._instance:
cls._instance = super().__new__(cls)
return cls._instance
singleton = Singleton()
singleton1 = Singleton()
print(id(singleton))
print(id(singleton1))70:装饰器的写法以及应用场景。
import time
def f1(b):
print(b)
def func(f):
def xm(*args, **kwargs):
print('我先执行了')
result = f(*args, **kwargs)
time1 = time.asctime()
print(time1)
return result
return xm
return func
@f1('1')
def hello(a):
print('是你先执行的吗?')
return a
print(hello(1))
我先执行了
是你先执行的吗?
Wed Aug 22 23:31:33 2018
171:异常处理写法以及如何主动跑出异常(应用场景)
try:
1/0
except Exception as e:
print(repr(e))
else:
print('来到这里了')
finally:
print('你们最后还是要走这里的知道吗')
try:
raise ZeroDivisionError('没有东西可以下载了')
except Exception as e:
print(repr(e))
finally:
print('你们最后还是要走这里的知道吗')
72:什么是面向对象的mro
class A(object):
pass
class B(A):
pass
class C(A):
pass
class D(B, C):
pass
print(D.__mro__)
print(D.mro())
[73:isinstance作用以及应用场景?
74:忽略
75:json序列化时,可以处理的数据类型有哪些?如何定制支持datetime类型?
from datetime import datetime, date
import json
now = datetime.now()
#直接这样序列化就报错了,要先创建一个类继承于json.JSONEncoder
# print(json.dumps({'now': now}))
class ComplexEncoder(json.JSONEncoder):
def default(self, obj):
if isinstance(obj, datetime):
return obj.strftime('%Y-%m-%d %H:%M:%S')
elif isinstance(obj, date):
return obj.strftime('%Y-%m-%d')
else:
return json.JSONEncoder.default(self, obj)
# 在调用json.dumps时需要指定cls参数为ComplexEncode
print(json.dumps({'now': now}, cls=ComplexEncoder))
76:json序列化时,默认遇到中文会转换成unicode,如果想要保留中文怎么办?
import json
dict1 = {'name': '李小萌', 'age': 10}
#序列化的时候添加一个参数 ensure_ascii=False
print(json.dumps(dict1, ensure_ascii=False))Python Json序列化与反序列化
77:什么是断?应用场景?
78:有用过with statement吗?它的好处是什么?
with open('output.txt', 'w') as f:
f.write('Hi there!')79:使用代码实现查看列举目录下的所有文件。
import os
# 可以通过相对路径
print(os.listdir('../面试题'))
#也可以通过绝对路径 得到的结果是一个列表的形式可以遍历出来
print(os.listdir('D:\python.Object\python_day1\面试题'))80:简述 yield和yield from关键字。
yield from iterable本质上等于for item in iterable: yield item的缩写
def feifrom(f):
yield from f # from后面必须接的是可叠代对象
list1 = [1,2,3]
xx1 = feifrom(list1)
for i in list1:
print(i)
def fei(f1):
yield f1
list2 = '10'
xx2 = fei(list2)
print(next(xx2))