斯坦福CS231n作业代码(汉化)Assignment 2 Q1 - Q3
一段关于神经网络的故事
编写:土豆 MoreZheng SlyneD
校对:碧海听滔 Molly
总校对与审核:寒小阳
- 一段关于神经网络的故事
- 待折腾的数据集
- 关于神经网络你起码应该知道的
- 所谓的前向传播
- 一个神经元的本事
- 强大的层状神经元
- 不废话了看代码
- 传说中的反向传播
- 审判官损失函数登场
- 跟着梯度走
- 链式的反向传播
- 小结拉起神经网络的大网
- 高速运转的加强版神经网络
- 论自我惩罚后的救赎之路正则化
- 批量归一化
- 就是这么任性Dropout
- 构造任意深度的神经网络
- 最终章
- 漫漫优化路SGD with momentum
- 夜黑风高小试牛刀
To-Do:
[x] 统一所有的数学符号和代码符号
[x] 统一所有的术语名称
[x] 术语的英文词汇对应
[x] 线性模型的名字是?perceptron?
[x] 损失函数的计算公式和符号是否严格和合适?
[x] denominator layout?
- [ ] BN梯度的证明
- [x] bn_param[‘running_mean’] = running_mean
bn_param[‘running_var’] = running_var
(我是盗图大仙,所有图片资源全部来源于网络,若侵权望告知~)
本文是什么?
本文以CS231n的Assignment2中的Q1-Q3部分代码作为例子,目标是由浅入深得搞清楚神经网络,同时以图片分类识别任务作为我们一步一步构建神经网路的目标。
本文既适合仅看得懂一点Python代码、懂得矩阵的基本运算、听说过神经网络算法这个词的朋友,也适合准备学习和正在完成CS231n课程作业的朋友。
本文内容涉及:很细节的Python代码解析 + 神经网络中矩阵运算的图像化解释 + 模块化Python代码的流程图解析
本文是从Python编程代码的实现角度理解,一层一层拨开神经网络的面纱,以搞清楚数据在其中究竟是怎么运动和处理的。希望可以为小白,尤其是为正在学习CS231n课程的朋友,提供一个既浅显又快捷的观点,用最直接的方式弄清楚并构建一个神经网络出来。所以,此文不适合章节跳跃式阅读。
本文不是什么?
不涉及艰深的算法原理,忽略绝大多数数学细节,也尽量不扯任何生涩的专业术语,也不会对算法和优化处理技术做任何横向对比。
CS231n课程讲师Andrej Karpathy在他的博客上写过一篇文章Hacker’s guide to Neural Networks,其中的精神是我最欣赏的一种教程写作方式:“My exposition will center around code and physical intuitions instead of mathematical derivations. Basically, I will strive to present the algorithms in a way that I wish I had come across when I was starting out.”
“…everything became much clearer when I started writing code.”
废话不多说,找个板凳坐好,慢慢听故事~
待折腾的数据集
俗话说得好:皮裤套棉裤,里边有缘故;不是棉裤薄,就是皮裤没有毛!
我们的神经网络是要用来解决某特定问题的,不是家里闲置的花瓶摆设,模型的构建都有着它的动机。所以,首先让我们简单了解下要摆弄的数据集(CIFAR-10),最终的目标是要完成一个图片样本数据源的分类问题。
图像分类数据集:CIFAR-10。
这是一个非常流行的图像分类数据集是CIFAR-10。这个数据集包含了60000张 32×32 的小图像,单个像素的数值范围都在0-255之间。每张图像都对应于是10种分类标签(label)中的一种。此外,这60000张图像被分为包含带有标签的50000张图像的训练集和包含不带有标签的10000张图像的测试集。
上图是图片样本数据源CIFAR-10中训练集的一部分样本图像,从中你可以预览10个标签类别下的10张随机图片。
小结:
在我们的故事中,只需要记得这个训练集是一堆 32×32 的RGB彩色图像作为训练目标,一个样本图像共有 32×32×3 个数据,每个数据的取值范围0~255,一般用x来标记。每个图还配有一个标签值,总共10个标签,以后我们都用y来标记。(悄悄告诉你的是:每个像素点的3个数据维度是有序的,分别对应红绿蓝(RGB))
关于神经网络,你起码应该知道的!
下图是将神经网络算法以神经元的形式绘制的两个图例,想必同志们早已见怪不怪了。
但是,你起码应该知道的是其中各种约定和定义:

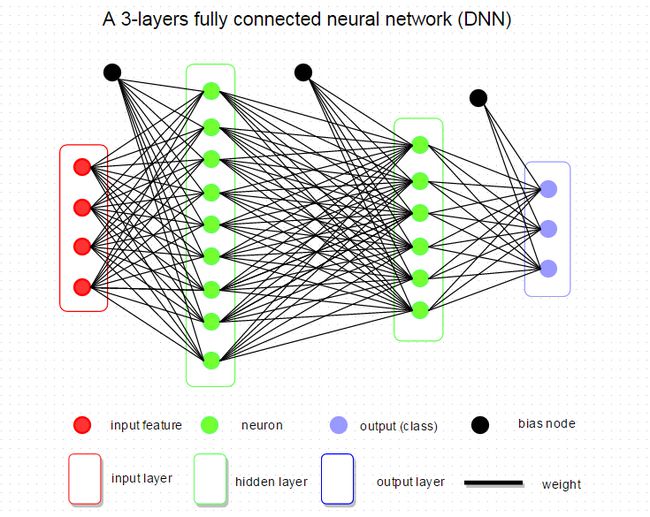
左边是一个2层神经网络,一个隐藏层(蓝色层)有4个神经元(也可称为单元(unit))组成,输出层(绿色)由2个神经元组成,输入层(红色)是3个”神经元”。右边是一个3层神经网络,两个隐藏层,每层分别含4个神经元。注意:层与层之间的神经元是全连接的,但是层内的神经元不连接(如此就是所谓全连接层神经网络)。
这里有个小坑:输入层的每个圈圈代表的可不是每一张图片,其实也不是神经元。应该说整个纵向排列的输入层包含了一张样本图片的所有信息,也就是说,每个圈圈代表的是某样本图片对应位置的像素数值。可见对于CIFAR-10数据集来说,输入层的维数就是 32×32×3 ,共3072个圈圈呢!至于输出层的神经元数也是依赖数据集的,就CIFAR-10数据集来说,输出层维数必然是10,即对应数据集的10个标签。至于中间的隐藏层可以有多少层,以及每层的神经元个数就都可以任意啦!你说牛不牛?!
在接下来我们的故事中,要从代码实现的角度慢慢剖析,先从一个神经元的角度出发,再搞清楚一层神经元们是如何干活的,然后逐渐的弄清楚一个含有任意神经元个数隐藏层的神经网络究竟是怎么玩的,在故事的最后将会以CIFAR-10数据集的分类问题为目标一试身手,看看我们构造的神经网络究竟是如何工作运转的。
所谓的前向传播
一个神经元的本事
我们先仅前向传播而言,来谈谈一个神经元究竟是做了什么事情。
前向传播,这名字起的也是神乎其神的,说白了就是将样本图片的数据信息,沿着箭头正向传给一个带参数的神经网络层中咀嚼一番,然后再吐出来一堆数据再喂给后面的一层吃(如此而已,居然就叫做了前向/正向传播了,让人忍不住吐槽一番)。那么,对于一个全连接层(fully-connected layer) 1
的前向传播来说,所谓的“带参数的神经网络层”一般就是指对输入数据源(此后用”数据源”这个词来表示输入层所有输入样本图片数据总体)先进行一个矩阵乘法,然后加上偏置,得到数字再运用激活函数”修饰”,最后再反复迭代罢了(后文都默认使用此线性模型)。
是不是晕了?别着急,我们进一步嚼碎了来看看一个神经元(处于第一隐藏层)究竟是如何处理输入层传来的一张样本图片(带有猫咪标签)的?
上面提到过,输入数据源是一张尺寸为 32×32 的RGB彩色图像,我们假定输入数据 xi 的个数是 D 的话(即 i 是有 D 个),那这个 D=32×32×3=3072 。为了普遍意义,下文继续用大写字母 D 来表示一张图片作为数据源的维数个数(如果该神经元位于隐藏层,则大写字母 D 表示本隐藏层神经元的神经元个数,下一节还会提到)。
显然,一张图片中的 D 个数据 xi 包含了判断该图片是一支猫的所有特征信息,那么我们就需要”充分利用”这些信息来给这张样本图片”打个分”,来评价一下这张图像究竟有多像猫。
不能空口套白狼,一张美图说明问题:

左图不用看,这个一般是用来装X用的,并不是真的要严格类比。虽然最初的神经网络算法确实是受生物神经系统的启发,但是现在早已与之分道扬镳,成为一个工程问题。关键我们是要看右图的数学模型(严格地说,这就是传说中的感知器perceptron)。
如右图中的数学模型所示,我们为每一个喂进来的数据 xi 都对应的”许配”一个”权重”参数 wi ,再加上一个偏置 b ,然后一股脑的把他们都加起来得到一个数(scalar):
上面的代数表达式看上去很繁杂,不容易推广,所以我们把它改写成
上面等式左侧这样算出的一个数字,表示为对于输入进来的 D 个数据 xi ,在当前选定的参数 (wi,b) 下,这个神经元能够正确评价其所对应的”猫咪”标签的程度。所以,这个得分越高,越能说明其对应的在某种 (wi,b) 这 D+1 个参数的评价下,该神经元正确判断的能力越好,准确率越高。
换句话说,相当于是有一个神经元坐在某选秀的评委席里,戴着一款度数为 (wi,b) 雷朋眼镜,给某一位台上模仿猫咪的样本图片 xi 打了一个分(评价分数)。显然,得分的高低是不仅依赖于台上的主角 xi 的表现,还严重依赖于神经元评委戴着的有色眼镜(参数 wi,b )。当然,我们已经假定评委的智商(线性模型)是合乎统一要求的。
现如今,参加选秀的人可谓趋之若鹜,一个神经元评委该如何同时的批量化打分,提高效率嗯?
也就是说,一个神经元面对 N 张图片该如何给每一张图片打分的问题。这就是矩阵表达式的优势了,我们只需要很自然地把上述矩阵表达式纵向延展下即可,如下所示:
上面矩阵表达式中,等号左侧的得分矩阵中每一行运算都是独立并行的,并且其每一行分别代表 N 张样本图片的数据经过一个神经元后的得分数值。到此,我们就明白了一个神经元是如何面对一个shape为(N, D)的输入样本图片数据矩阵,并给出得分的。
然而,关于一个神经元的故事还没完。
你可能注意到了,上面例子中的美图中有个函数f,我们把图放大仔细看清楚:
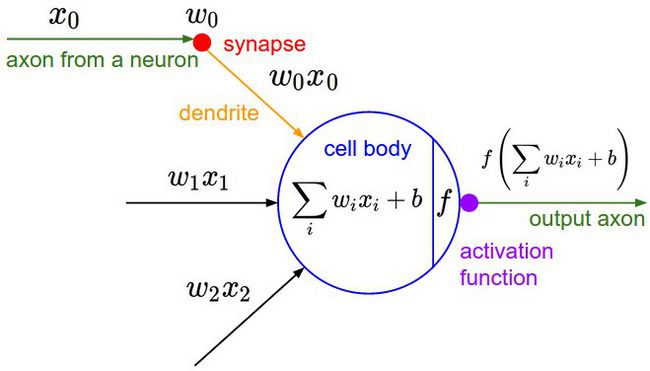
在神经元对每张图片算得的“得分”送给下一个神经元之前都要经过一个函数f的考验。这就暗示我们,选秀节目的导演对神经元评委给出的得分还并不满意,为了(未来模型训练的)快捷方便,导演要求对每一个得分需要做进一步的“激活”处理(即上图中的函数 f ),于是这个叫激活函数(activation)的家伙会对结果做进一步的处理、比如大家这些年都在用的ReLU就是临门一脚,要求把得分小于零的都阉割掉,一律给0分(都得负分的了还选什么秀啊?给0分滚蛋):
所以,总结下来,一个神经元干的活就是如下所示的公式:
如果这个数学看得让人心烦意乱,不要怕,一层神经元的故事之后就是万众期待的Python代码实现了,相信看后会让你不禁感慨:“小样!不过如此嘛~”
小备注:
这里最后再多一句嘴:一个神经元在前向传播中输出的只是一个数字,另外,神经网络的训练过程,训练的是上述提到的模型参数 (wi,b) 。
再多一句嘴,通常我们在整个神经网络结构中只使用一种激活函数。并且值得你注意的是,全连接层的最后一层就是输出层,除了这个最后一层,其它的全连接层神经元都要包含激活函数。
最最后说再一句,神经网络的激活函数是非线性的,所以神经网络是一个非线性分类器。
强大的层状神经元
在正式开始谈一层神经元之前,我们继续来探讨下神经元面对一张图片还可以做什么?
对于一张标签是猫咪的样本图片,我们光能评价有多么的像猫咪还不能满足,我们还需要神经元评价一下其他9个标签才行,然后才好比较评判得出最终结论。于是,光用 (wi,b) 这 D+1 个参数就不够用了,应该要有 10×(D+1) 个参数才行。还是用那个恶搞的例子说明的话,就是说一个神经元评委可不够用哦,要10个戴着不同有色眼镜的神经元评委分头去考察10个不同标签,这样就可以对每个样本图片给出10个对应不同类别的得分。
所以,我们可以在最初的矩阵表达式 ∑iwixi+b 的基础上横向延展成如下矩阵表达式:
忘了说,在上面表达式里,大括号下面的数字表示的是当前矩阵的【行数 × 列数】。同样地,这里运用了矩阵乘法和向量化表示会大大的提高运算效率。在如此简单的矩阵运算之后,等号左边所得到一行数组(行向量)就表达了在参数矩阵w和向量b的描述下,该一张样本图片分别对应10个不同类标标签的得分。而我们最终的目标就是学习如何训练这里的参数w和b,并且我们希望训练好后的某样本图片在正确目标标签下所对应的得分是最高的。
为了便于直观理解,给你一个数值栗子尝尝鲜(和上面的矩阵公式有点区别,但并不影响理解):
可以看到我们拿了样本猫咪图片中的四个像素作为一个神经元的输入数据源,不过上图只查看了3个标签(猫/狗/船),且把输入数据 xi 改成用列向量表达罢了,这并不影响我们理解,无非是我们的矩阵公式改为 wTx+bT 表达 。接下来看图说话,可以看到在如图初始化矩阵 W 和 b 的情况下,算出的得分对应于猫咪的分数居然是最低的2
,这说明 W 和 b 的值没有训练好啊。那么究竟该如何训练出合适的参数呢?难道每次都要肉眼观察每个标签算出的得分再同时对比参数选的究竟好不好?再难道每次都要自己手调参数矩阵的每个值来观察得分效果么?当然不会这么傻啦,到时候一个叫损失函数的概念就登场了,且继续听故事先~
回到上面经过横向延展后的矩阵表达式:
可以看到对于一个 D 维图片 xi ,都和w矩阵的每一列(10个神经元评委)有过亲密接触,独立并行的进行过矩阵乘法,回想一下,这不和一个神经元面对一张样本图片的公式异曲同工了么?只不过换成了10个神经元并行面对一张样本图片。所以,上述矩阵表达式就相当于一张图片的数据从输入层流到含有10个神经元的层状结构(无激活函数)。(严格地说,这其实是 无隐层神经网络,或者叫 单层感知器,因为输入层的下一层就是输出层,直接输出了10个标签的打分结果了,如下面的示意图)
接下来,推广到一般的隐藏层神经元们是如何干活的就易如反掌了!只要充分利用矩阵乘法,就可以很清楚了。小结如下:

从右往左看公式(等号类似赋值操作)。上述矩阵表达式表示的是某一隐藏层的H个神经元们在面对上一层输入数据 xi 是如何传给下一层的M个神经元的。N表示数据样本的个数,H表示本隐藏层神经元的个数,M表示下一隐藏层神经元的个数(或位于下一输出层的样本图片标签种类数)。(最后矩阵b里的Broadcasting含义见后文哈~不要急)
每一个隐藏层得出得分 x̂ i 后,都还需要经过激活函数 f(x̂ i)=max(0,x̂ i) 的处理,要留意的是最后的输出层并不需要激活函数,给出得分后即可交给损失函数(后文会提到)。
小备注:
值得注意的是:流入每一层神经元们的输入数据矩阵x和流出每一层神经元们的输出数据矩阵的行数没有变化,都是N,即样本图片个数。每一层神经元们的参数矩阵w和b都是不同的,那么你就能想象到对于一个”很大很深”神经网络而言,需要训练学习的参数个数可是相当多的哦~而且参数矩阵w的维数也很有特点,其行数H和列数M,分别对应于当前隐藏层神经元个数和下一层神经元的个数。如此一来,就把每一层神经元一层套一层连接起来了。
不废话了,看代码!
正如本文开头那句话,
“…everything became much clearer when I started writing code.”
再强大的算法,无论矫情得怎么解释,也都不如直接飞代码来得更清晰,更直接。
那么任意某一层神经元们在前向传播中,究竟做了什么呢?前面总算把数据如何运动的故事说清楚了,现在开始直接用代码说明一切,第一步,我们定义面对输入数据某一层神经元们给出“得分”的函数 affine_forward(x, w, b) = (out, cache) :
def affine_forward(x, w, b):
""" Inputs: - x: A numpy array containing input data, of shape (N, d_1, ..., d_k) 样本 - w: A numpy array of weights, of shape (D, M) 权重 - b: A numpy array of biases, of shape (M,) 偏置 Returns a tuple of: - out: output, of shape (N, M) - cache: (x, w, b) """
out = None # 初始化
reshaped_x = np.reshape(x, (x.shape[0],-1)) # 确保x是一个规整的矩阵
out = reshape_x.dot(w) +b # out = w x +b
cache = (x, w, b) # 将该函数的输入值缓冲储存起来,以备后面计算梯度时使用
return out, cache代码详解:
- 首先,需要对输入数据 x 进行矩阵化,这是因为如果这代表的是第一层神经元前向传播,那么对于我们的图片数据集CIFAR-10,其每张图片输入进来的数据 x 的shape是 (N,32,32,3) ,是一个4维的array,所以需要将其reshape成 (N,3072) 的2维矩阵,其中每行是由一串3072个数字所代表的一个图片样本。
np.reshape(x, (x.shape[0],-1))中的-1是指剩余可填充的维度,所以这段代码意思就是保证reshape后的矩阵行数是 N ,剩余的维度信息都规则的排场一行即可。 - 输出的
cache变量就是把该函数的输入值 (x,w,b) 存为元组(tuple)再输出出去以备用,它当然不会流到下一层神经元,但其在后面会讲到的反向传播算法中利用到,由此可见我们是有多么的老谋深算啊! - 接下来是重点:
out = reshape_x.dot(w) +b这句代码就表达了某一层神经元中,每个神经元可以并行的独立完成上两节提到的线性感知器模型,对每个图像给出自己的评价分数,与代码对应一致的内涵可见如下矩阵表达式:
这里你要清楚的是 reshape_x 中每一行和 w 中的每一列的运算对应于一个神经元面对一张图片的运算过程。矩阵乘法没啥可说的,只要把输入矩阵和要输出的矩阵的维数掰扯清楚了,就会很简单。这里参数w和b都作为函数的输入参数参与运算的,可见你想让神经网络运作起来,你是需要先初始化所有的神经网络参数的,那么究竟如何初始化呢?这还是门小学问,我们暂且假定是随机填了些的参数进来。虽然输入进来的参数 b 的shape是 (M,),但在numpy中,两个array的”+”相加,是完全等价于np.add()函数(详情可help该函数),这里体现了numpy的Broadcasting机制:(详情可查看Python库numpy中的Broadcasting机制解析)
简单的说,对两个阵进行操作时,NumPy逐元素地比较他们的形状。只有两种情况下Numpy会认为两个矩阵内的两个对应维度是兼容的:1. 它们相等; 2. 其中一个是1维。举个例子:
A (4d array): 8 x 1 x 6 x 1 B (3d array): 7 x 1 x 5 Result (4d array): 8 x 7 x 6 x 5当任何一个维度是1,那么另一个不为1的维度将被用作最终结果的维度。也就是说,尺寸为1的维度将延展或“逐个复制”到与另一个维度匹配。
所以代码中的偏置b,其shape为(M,),其实它表明是一个 1×M 的行向量,面对另一个 N×M 的矩阵,b 便遇强则强的在弱势维度上(纵向)被延展成了一个 N×M 的矩阵:
>⏐↓⏐⏐⏐⎡⎣⎢⎢>⋯>⋯>⋯bbb⋯⋯⋯>⎤⎦⎥⎥⎫⎭⎬⎪⎪N行>
虽然,我们说清楚了 affine_forward(x,w,b) 函数的故事,但要注意的是,在前向传播中一层神经元要干的活还没完哦~ 在隐藏层中得到的得分结果还需要ReLU激活函数“刺激”一下才算结束。
于是我们再定义 relu_forward(x) = (out, cache) 函数来完成这一步,其Python代码就更简单了:
def relu_forward(x):
""" Computes the forward pass for a layer of rectified linear units (ReLUs). Input: - x: Inputs, of any shape Returns a tuple of: - out: Output, of the same shape as x - cache: x """
out = np.maximum(0, x) # 取x中每个元素和0做比较
cache = x # 缓冲输入进来的x矩阵
return out, cache代码详解:
我们可以注意到,np.maximum() 函数中的接受的两个参数一样用到了刚刚详解过的Broadcasting机制:前一个参数是只有一个维度的数值0,被延展成了一个和矩阵x同样shape的矩阵,然后在对应元素上比大小(相当于矩阵x的所有元素中把比0小的元素都替换成0),取较大元素填在新的同shape形的矩阵out中。
那么,终于到最后了。一个隐藏层层神经元们在前向传播中究竟做了什么呢?那就是下面定义的 affine_relu_forward(x, w, b) = (out, cache) 函数:
def affine_relu_forward(x, w, b):
""" Convenience layer that perorms an affine transform followed by a ReLU Inputs: - x: Input to the affine layer - w, b: Weights for the affine layer Returns a tuple of: - out: Output from the ReLU - cache: Object to give to the backward pass """
a, fc_cache = affine_forward(x, w, b) # 线性模型
out, relu_cache = relu_forward(a) # 激活函数
cache = (fc_cache, relu_cache) # 缓冲的是元组:(x, w, b, (a))
return out, cache这里还是要留个心眼,对于输出层的神经元们来说,他们只需要用 affine_forward(x, w, b) 函数给出得分即可,无需再被”激活”。
小结一下:
我们手绘一张图来说清楚,一隐藏层神经元们在前向传播的 affine_relu_forward() 函数中,数据变量在模块代码中究竟是如何流动的:
传说中的反向传播
关于传说中的反向传播,首先我们最重要的是要明白:我们为什么需要这个反向传播?
然而,要想弄清楚这点,我们就需要回头考察下我们前向传播下最后输出层得到10个标签的评分究竟有什么用。这个问题的答案,将会直接引出故事中的审判官——损失函数。
前情提要:
在前向传播(从左向右)中,输入的图像数据 xi (以及所对应的正确标签 yi )是给定的,当然不可修改,唯一可以调整的参数是权重矩阵W(大写字母W表示神经网络中每层权重矩阵w的集合)和参数B(大写字母表示神经网络中每层偏置向量b的集合),即上图中每一条黑色的线和黑色的圈。所以,我们希望通过调节参数(W, B),使得最后评分的结果与训练数据集中图像的真实类别一致,即输出层输出的评分在正确的分类上应当得到最高的评分。
审判官!损失函数登场!
回到之前那张用来尝鲜的猫的图像分类栗子,它有针对“猫”,“狗”,“船”三个类别的分数。我们看到例子中权重值非常差,因为猫分类的得分非常低(-96.8),而狗(437.9)和船(61.95)比较高。正如上文提到的,究竟该如何让计算机自动地判别得分的结果与正确标签之间的差异,并且对神经网络所有参数给出改进意见呢?
我们自己仅凭肉眼和肉脑当然是做不了审判官的,但是一个叫做损失函数(Loss Function)(有时也叫代价函数Cost Function或目标函数Objective)的可以做到!直观地讲,当输出层的评分给出结果与真实结果之间差异越大,我们的审判官——损失函数就会给出更加严厉的判决!举起一个写有很大的判决分数,以表示对其有多么的不满!反之差异若越小,损失函数就会给出越小的结果。
我们这里请的是交叉熵损失(cross-entropy loss)来作为最终得分的审判官!废话少说,直接看代码!
def softmax_loss(z, y):
""" Computes the loss and gradient for softmax classification. Inputs: - z: Input data, of shape (N, C) where z[i, j] is the score for the jth class for the ith input. - y: Vector of labels, of shape (N,) where y[i] is the label for x[i] and 0 <= y[i] < C Returns a tuple of: - loss: Scalar giving the loss - dz: Gradient of the loss with respect to z """
probs = np.exp(z - np.max(z, axis=1, keepdims=True)) # 1
probs /= np.sum(probs, axis=1, keepdims=True) # 2
N = z.shape[0] # 3
loss = -np.sum(np.log(probs[np.arange(N), y])) / N # 4
dz = probs.copy()
dz[np.arange(N), y] -= 1
dz /= N
return loss, dz代码详解:
softmax_loss(z, y)函数的输入数据是shape为(N, C)的矩阵z和shape为(N, )的一维array行向量y。由于损失函数的输入数据来自神经网络的输出层,所以这里的矩阵z中的N代表是数据集样本图片的个数,C代表的是数据集的标签个数,对应于CIFAR-10的训练集来说,z矩阵的shape应该为(50000, 10),其中矩阵元素数值就是CIFAR-10的训练集数据经过整个神经网络层到达输出层,对每一张样本图片(每行)打分,给出对应各个标签(每列)的得分分数。一维array行向量y内的元素数值储存的是训练样本图片数据源的正确标签,数值范围是 0⩽yi<C=10 ,亦即 yi=0,1,…,9 。- 前2行代码定义了
probs变量。首先,np.max(z, axis=1, keepdims=True)是对输入矩阵x在横向方向挑出一个最大值,并要求保持横向的维度输出一个矩阵,即输出为一个shape为(N, 1)的矩阵,其每行的数值表示每张样本图片得分最高的标签对应得分;然后,再np.exp(z - ..)的操作表示的是对输入矩阵z的每张样本图片的所有标签得分都被减去该样本图片的最高得分,换句话说,将每行中的数值进行平移,使得最大值为0;再接下来对所有得分取exp函数,然后在每个样本图片中除以该样本图片中各标签的总和(np.sum),最终得到一个与矩阵z同shape的(N, C)矩阵probs。上述得到矩阵probs中元素数值的过程对应的就是softmax函数:
其中,我们已经取定了 C 的值: logC=−maxizij ,且 zij(z;W,B) 对应于代码中的输出数据矩阵x的第 i 行、第 j 列的得分z[i, j],其取值仅依赖于从输出层输入来的数据矩阵z和参数 (W,B) ,同理, Sij 表示矩阵probs的第 i 行、第 j 列的新得分。我们举一个简单3个图像样本,4个标签的输入数据矩阵x的栗子来说明得分有着怎样的变化:
可以看到”新得分矩阵”probs的取值范围为 (0,1) 之间,并且矩阵每行的数值之和为1,由此可看出来每张样本图片分布在各个标签的得分有 概率的含义。
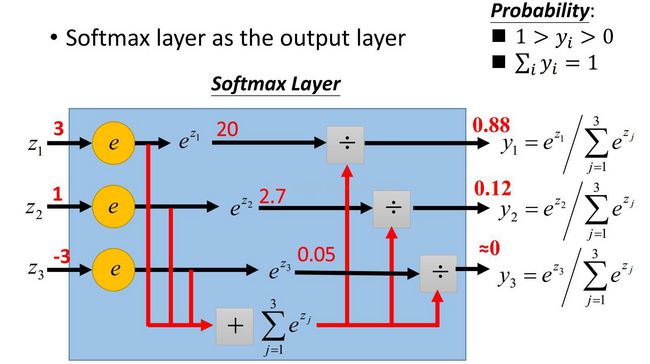
这个图是另一个小例子来说明Softmax函数可以镶嵌在输出层中,相当于其他隐藏层神经元们中的激活函数一样,用Softmax函数对输出层算得的得分进行了一步“激活”操作。
- 定义损失函数:
loss = -np.sum(np.log(probs[np.arange(N), y])) / N,输出是一个scalar数loss。其数学含义是这样的
其中的 ∑i;j=yi 表示的是对每个图片正确标签下的得分全部求和。听上去很晕是不是?还是痛快的给个栗子就清楚了:
上图的例子依旧是3个图像样本,4个标签从输出层输出数据矩阵x,同时利用到了该三个图像样本的正确标签y。我们通过对probs矩阵的切片操作,即
probs[np.arange(N), y],取出了每个图片样本在正确标签下的得分(红色数字)。这里值得留意的是向量y的标签取值范围(0~9)刚好是可以对应于probs矩阵每列的index。
详解一下:
probs[np.arange(N), y]在例子中,对probs矩阵确切的切片含义是
probs[np.array([0, 1 ,2]), np.array([2, 0, 1])]这就像是定义了经纬度一样,指定了确切的行列数,要求切片出相应的数值。对于上面的例子而已,就是说取出第0行、第2列的值;取出第1行、第0列的值;取出第2行、第1列的值。于是,就得到了例子中的红色得分数值。切行数时,
np.arange(N)相当于是说“我每行都要切一下哦~”,而切列数时,y向量(array)所存的数值型分类标签(0~9),刚好可以对应于probs矩阵每列的index(0~9),如果y = np.array(['cat', 'dog', 'ship']),显然代码还这么写就会出问题了。
再简单解释一下上面获得loss损失函数的过程:我们首先对输出层输出的矩阵x做了一个”概率化”的rescale操作,改写为同shape的矩阵probs,使得每张样本图片的正确得分数值是足够充分考虑到了其他标签得分的(概率化),可见,Softmax分类器为每种分类都提供了“可能性”;然后针对这个矩阵probs,取出每个样本图片的正确标签所对应得分,再被单调递增函数log和sum取平均值操作后,取其负值即为损失函数的结果了。最后要说一下,公式中负号的存在,并不仅仅保证了一个正定的损失函数,还使得若损失函数的结果越小,那么就意味着我们最初追求的是正确标签下得分越高,整个神经网络模型的参数就训练得越好,其中的关联性正是损失函数的数学定义中单调递增函数exp和log的保证下所实现的。
由此很显然,在一整套层状神经网络框架里,我们希望能够得到让我们满意的模型参数(W, B),只需要使得损失函数最小,就说明我们的模型参数(W, B)取得好哈!
所以说,找输出层给出的得分和正确标签得分差距小的参数(W, B)的问题,就被转移为究竟什么样的参数(W, B)使得损失函数最小!
跟着梯度走!
别忘了代码中的 softmax_loss(z, y) 函数最后还有三行哈!它非常重要,是除了评分函数和损失函数之外,体现的是神经网络算法的第三个关键组成部分:最优化Optimization!最优化是寻找能使得损失函数值最小化的参数(W, B)的过程。由于每当我们取定的模型参数(W, B)稍微变化一点点的时候,最后算得的损失函数应该也会变化一点点。自然地,我们就非常希望模型参数每变化一点点的时候,损失函数都刚好能变小一点点,也就是说损失函数总是很乖地向着变小的方向变化,最终达到损失函数的最小值,然后我们就收获到理想的模型参数(W, B)。若真如此,不就省下了“踏破铁鞋无觅处”,反而“得来全不费工夫“!那么究竟怎么走才能才能如此省心省事呢?
这时候,就有必要引出梯度这个概念了。因为,我们希望能够看到损失函数是如何随着模型参数的变化而变化的,也就是说损失函数与模型参数之间的变化关系,然后才好进一步顺着我们想走的可持续发展的道路上,”衣食无忧,顺理成章,奔向小康~”
那么究竟什么是梯度呢?
梯度的本意是一个向量(矢量),表示某一函数在该点处的方向导数沿着该方向取得最大值,即函数在该点处沿着该方向(此梯度的方向)变化最快,变化率最大(为该梯度的模)。一张小图来解释梯度怎么用:

上图中的曲面是二元函数 f(x,y) 在自变量 (x,y) 的图像。图上箭头就表示该点处函数f关于坐标参数x,y的梯度啦!从我们的神经网络角度去看,二元函数 f(x,y) 可以对应于模型最终算得的损失函数loss,其自变量就是模型的参数(W, B)。如果我们让训练样本图片经过一次神经网络,最后就可以得到一个损失值loss,再根据我们初始选定的模型参数(W, B),就也可以在上面的(高维)曲面上找到一点对应。假若我们同时也知道了该点处loss的梯度,记号为grad,那么也就意味着参数(W, B)如果加上这个grad数值,在新参数(W+grad, b+grad)下让样本图片经过神经网络新计算出来的loss损失值一定会更大一些,这正是梯度的定义所保证的,如下图:(注:梯度grad是可为正也可为负的)

但是不要忘了,我们的目标是希望得到损失函数loss最小时的参数(W, B),所以我们要让神经网络的参数(W, B)在每次有样本图片经过神经网络之后,都要让所有参数减去梯度(加负梯度)的方式来更新所有的参数,这就是所谓的梯度下降(gradient descent)。最终,使得损失函数关于模型参数的梯度达到足够小,即接近损失函数的最小值,就可以真正完成我们神经网络最优化的目的(更详细实现梯度下降的故事,我们留到最后的来说明)。
那么,如何在每一次有样本图片经过神经网络之后,得到损失函数关于模型参数的梯度呢?
寒暄到此为止,我们再贴一遍 softmax_loss(z, y) = (loss, dx) 函数代码,来观察下后三行代码里损失函数关于输出层输出数据矩阵z的梯度是如何计算出的:
def softmax_loss(z, y):
""" Computes the loss and gradient for softmax classification. Inputs: - z: Input data, of shape (N, C) where z[i, j] is the score for the jth class for the ith input. - y: Vector of labels, of shape (N,) where y[i] is the label for x[i] and 0 <= y[i] < C Returns a tuple of: - loss: Scalar giving the loss - dz: Gradient of the loss with respect to z, of shape (N, C) """
probs = np.exp(z - np.max(z, axis=1, keepdims=True))
probs /= np.sum(probs, axis=1, keepdims=True)
N = z.shape[0]
loss = -np.sum(np.log(probs[np.arange(N), y])) / N
dz = probs.copy() # 1 probs.copy() 表示获得变量probs的副本
dz[np.arange(N), y] -= 1 # 2
dz /= N # 3
return loss, dz代码解析:
- 这里的后三行计算出的
dz变量是损失函数关于从输出层输入来的数据矩阵z的梯度,其shape与数据矩阵z相同,即(N, C)。其严格的数学解析定义(证明过程)是:
不明白数学没有关系,只需要清楚我们算得的梯度是损失函数关于从输出层输入来的数据矩阵x上的梯度 ∂L/∂x 就足够了,直接看代码来弄清楚数据是如何运动的:
在上述的过程中,我们得到经过Softmax函数处理过的”新得分矩阵” Sij ,并且令其中每张样本图片(每行)对应于正确标签的得分都减一,再配以系数1/N之后,就得到了损失函数关于输入矩阵z的“梯度矩阵”
dz。严格的说,我们在
softmax_loss(z, y) 函数中输出的shape为(N, C)的
dz 矩阵变量对应的是
dLij/dzil 。
小结一下:
在我们定义的 softmax_loss(z, y) 函数中,不仅对神经网络的输出层给出的得分矩阵z给出了一个最终打分 loss——即损失函数,同时还输出了一个和得分矩阵z相同shape的散度矩阵 dz,代表的是损失函数关于得分矩阵z的梯度:根据 ∂Lij∂zij=1N(Sij−1);∂Lij∂zil=1NSil;(l≠yi) ,有:
可以看到这个损失函数的梯度矩阵 dz 会得出每张样本图片(每行)的每个标签(每列)下输出层输出数据的得分梯度,亦即我们得到的是损失函数关于输出层得分的变化率 ∂L/∂z (后文用 ∂L/∂z 表示损失函数关于输出层神经元得分数据的梯度,用 ∂L/∂x,∂L/∂y 表示损失函数关于隐藏层神经元输出数据的梯度)。然而,我们的故事还远没有说完,回忆一下!我们需要的可是损失函数关于神经网络中所有参数(W, B)的变化率啊!(即 ∂L/∂W,∂L/∂B ) 然后我们才能不断通过损失函数 L 的反馈来调整神经网络中的参数(W, B)。
那么究竟该如何把损失函数关于输出层得分的变化率 ∂L/∂z 与损失函数关于神经网络中参数(W, B)的变化率 ∂L/∂W,∂L/∂B 建立起联系呢?这时候,传说中的反向传播终于要登场了!
链式的反向传播!
目前,我们已经将损失函数 L 与输出层输出数据矩阵的每一个得分建立起了联系。只要最后我们能算得出损失函数的值,就说明我们已经获得输出层的输出数据,进而就能得到损失函数关于输出层输出数据的梯度 ∂L/∂z 。
那么该如何进一步得到损失函数关于其他隐藏神经元层的输出数据的梯度 ∂L/∂x 呢?还有其关于每一隐藏层的参数数据的梯度 ∂L/∂W,∂L/∂B 呢?这时候就要感谢一下伟大的莱布尼兹,感谢他发明复合函数的微积分求导“链式法则”就是传说中的反向传播算法的核心基础。
废话少说,看图说话,故事还是要先从一个神经元说起:

图中正中的函数f相当于输出层的某一个神经元。绿色箭头代表的是得分数据的前向传播 f(x,y)=z (可以看到输出层正向来的数据 x,y 被”激活”过,流出输出层的数据 z 并没有考虑”激活“),红色箭头即代表的是梯度的反向传播。图中右侧的 ∂L/∂z 表示损失函数 L 关于输出层中来自当前神经元的数据得分 z 的梯度(scalar)。以上都是我们已知的,而我们未知且想知道的是损失函数 L 关于最后一隐藏层中流入当前神经元的数据得分 x 和 y 的梯度,即 ∂L/∂x,∂L/∂y 。
链式法则给我们提供了解决方案,那就是通过“局部梯度”将损失函数的梯度传递回去:
在反向传播的过程中,我们只需要给出上面蓝色公式所代表的局部梯度 ∂z/∂x,∂z/∂y ,即可从损失函数 L 关于输出层输出数据 z 的梯度 ∂L/∂z 得到 L 关于上一隐藏层输出数据 x,y 的梯度 ∂L/∂x,∂L/∂y 。如此一来,只要我们在每一层神经元处都定义好了局部梯度,就可以很轻松的把损失函数 L 关于该层神经元们输出数据的梯度”搬运”到该层神经元们输入数据的梯度,如此反复迭代,就实现了传说中的反向传播。。。
关于反向传播的故事还有一点没说完:对损失函数的 L 全微分不仅会涉及每层神经元给出的得分的微分,也会牵扯到该层参数(w, b)的微分,如此一来就可以得到我们想要的损失函数 L 关于神经网络模型参数(W, B)的梯度。
整个过程很像是 L 关于数据的梯度在每一层反向传播,顺便地把各层关于参数的梯度也算了出来。
是不是又被说晕了?不要急,直接上代码,最后奇迹立现!
def affine_backward(dout, cache):
""" Computes the backward pass for an affine layer. Inputs: - dout: Upstream derivative, of shape (N, M) 上一层的散度输出 - cache: Tuple of: - z: Input data, of shape (N, d_1, ... d_k) - w: Weights, of shape (D, M) - b: biases, of shape (M,) Returns a tuple of: - dz: Gradient with respect to z, of shape (N, d1, ..., d_k) - dw: Gradient with respect to w, of shape (D, M) - db: Gradient with respect to b, of shape (M,) """
z, w, b = cache
dz, dw, db = None, None, None
reshaped_x = np.reshape(z, (z.shape[0], -1))
dz = np.reshape(dout.dot(w.T), z.shape) # np.dot() 是矩阵乘法
dw = (reshaped_x.T).dot(dout)
db = np.sum(dout, axis=0)
return dz, dw, db代码详解:
- 我们定义
affine_backward(dout, cache) = (dz, dw, db)函数来描述输出层神经元的反向传播。其中shape为(N, M)的dout矩阵就是损失函数 L 关于该层在affine_forward()函数正向输出数据out的梯度,其对应于我们上一节定义的softmax_loss()函数输出的dz矩阵。梯度在输出层反向传播的话,M的大小就等于样本图片的标签数,即 M=10 。cache元组是正向流入输出层的神经元的数据x和输出层的参数(w, b),即有z, w, b = cache,其中输出层的输入数据z是未经过reshaped的一个多维array,shape为 (N,d1,…,dk) ,权重矩阵W的shape是(D, M),偏置b的shape是(M, )。
接下来就是重点了!首先,在前向传播中,我们已经清楚该输出层神经元中数据的流动依据的是一个线形模型,即 形如函数表达式 z(x,w,b)=xw+b 。找到函数 z 的局部梯度显然很简单:
进而,就可以有:(蓝色部分即为局部梯度!)
然而,我们的“得分”函数可没这么简单,其是如下的一个矩阵表达式:
那么,这个矩阵表达式的局部梯度究竟该怎么写呢?通常,大家把故事讲到这里都是用”矩阵维度适配”的办法说明的,我们也会遵循主流,因为故事这样讲会很容易理解,也更方便应用。若想详细了解其中涉及的矩阵论知识,可参阅: cs231n, Wiki。
“矩阵维度匹配”到底是什么意思?这其实是个挺”猥琐”的方法,故事是这样的:
首先,我们要约定好所有损失函数 L 梯度的shape都要与其相关的矩阵变量的shape相同。比方说,上一节损失函数 softmax_loss(z, y) = (loss, dz) 中的梯度 dz 就和数据矩阵 z 的shape相同。所以,在函数 affine_backward(dout, cache) = (dz, dw, db) 中,我们就要求损失函数 L 关于正向输入矩阵(x, w, b)的梯度矩阵 (dx, dw, db) 与矩阵 (x, w, b) 维度相同。(严格说,我们的局部梯度求导其实对应于vector-by-vector derivatives,我们如此约定不过是相当于取定denominator layout)
于是,我们就可以按照上面函数 z 的局部梯度规则书写,只要保证矩阵表达式维度匹配即可: